标签:文件 roc lan 注意 负载 cal 写入 lag 表名
ProxySQL是一个高性能的MySQL中间件,拥有强大的规则引擎。具有以下特性:
官方参考文档 https://github.com/sysown/proxysql/wiki
生产环境建议架构如下:
注意, MHA 的VIP 已经不需要了,因为ProxySQL 可以检查发现并剔除故障的机器,对应用是透明的。
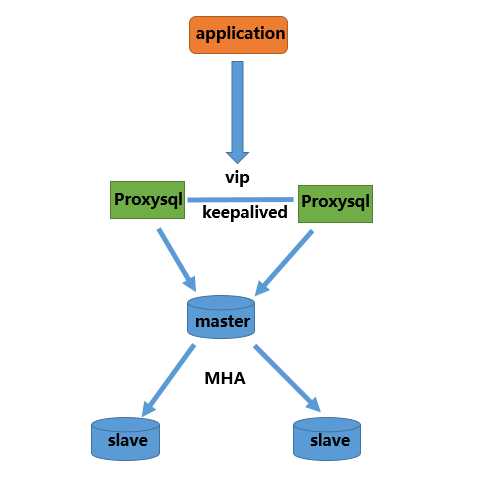
10.180.3.1 Proxy1 10.180.2.163 MHA-M1 10.180.2.164 MHA-S1 10.180.2.165 MHA-S2
推荐使用percona 的源,使用yum install
[root@Proxy1 ~]# yum list proxysql |grep proxysql proxysql.x86_64 1.3.9-1.1.el6 percona-release-x86_64
安装完后,在/etc 有两个初始化的文件
proxysql-admin.cnf proxysql.cnf , 里面配置有默认的IP 和端口号, 可以根据需要进行修改
使用service proxysql start 启动服务
启动之后,可以看到这些文件:proxysql.db是SQLITE的数据文件,proxysql配置,如后端数据库的账号、密码、路由等存储在这个数据库里面,proxysql.log是日志文件。proxysql.pid这个pid文件。proxysql.cnf是ProxySQL的一些静态配置项,比如一些启动选项,sqlite的数据目录等等。配置文件只在第一次启动的时候读取进行初始化,后面只读取db文件。
[root@Proxy1 init.d]# ps -ef|grep proxysql root 1084 997 0 10:17 pts/0 00:00:00 mysql -uadmin -p -S /tmp/proxysql_admin.sock proxysql 3940 1 0 Jul17 ? 00:00:00 /usr/bin/proxysql -c /etc/proxysql.cnf -D /var/lib/proxysql proxysql 3941 3940 0 Jul17 ? 01:45:30 /usr/bin/proxysql -c /etc/proxysql.cnf -D /var/lib/proxysql
和MySQL的很相似,我们启动一个进程,然后fork出一个子进程,父进程负责监控子进程运行状况如果挂了则拉起来,子进程负责执行真正的任务
root@proxysql1:~# mysql -uadmin -padmin -h127.0.0.1 -P6032 ... ... admin@127.0.0.1 : (none) 12:43:08>show databases; +-----+---------+-------------------------------+ | seq | name | file | +-----+---------+-------------------------------+ | 0 | main | | | 2 | disk | /var/lib/proxysql/proxysql.db | | 3 | stats | | | 4 | monitor | | +-----+---------+-------------------------------+
main 内存配置数据库,表里存放后端db实例、用户验证、路由规则等信息。表名以 runtime_开头的表示proxysql当前运行的配置内容,不能通过dml语句修改,只能修改对应的不以 runtime_ 开头的(在内存)里的表,然后 LOAD 使其生效, SAVE 使其存到硬盘以供下次重启加载。disk 是持久化到硬盘的配置,sqlite数据文件。stats 是proxysql运行抓取的统计信息,包括到后端各命令的执行次数、流量、processlist、查询种类汇总/执行时间等等。monitor 库存储 monitor 模块收集的信息,主要是对后端db的健康/延迟检查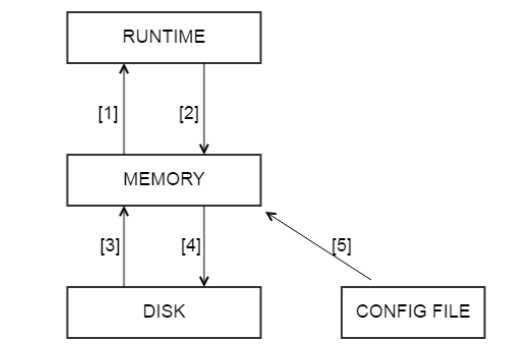
至于库里面每一个表和字段的说明,请详细阅读
http://seanlook.com/2017/04/10/mysql-proxysql-install-config/
登入ProxySQL,把MySQL主从的信息添加进去。将主库master也就是做写入的节点放到HG 300中,salve节点做读放到HG 3000。在proxysql输入命令:
mysql -uadmin -padmin -h127.0.0.1 -P6032
配置后端DB 的读写分组
admin@localhost:proxysql_admin.sock [(none)]>insert into mysql_servers(hostgroup_id,hostname,port,weight,max_connections,max_replication_lag,comment) values (3000,‘10.180.2.163‘,3306,1,300,10,‘proxysql‘); admin@localhost:proxysql_admin.sock [(none)]>insert into mysql_servers(hostgroup_id,hostname,port,weight,max_connections,max_replication_lag,comment) values (3000,‘10.180.2.163‘,3306,1,3000,10,‘proxysql‘); admin@localhost:proxysql_admin.sock [(none)]>insert into mysql_servers(hostgroup_id,hostname,port,weight,max_connections,max_replication_lag,comment) values (3000,‘10.180.2.164‘,3306,5,3000,10,‘proxysql‘); admin@localhost:proxysql_admin.sock [(none)]>insert into mysql_servers(hostgroup_id,hostname,port,weight,max_connections,max_replication_lag,comment) values (3000,‘10.180.2.165‘,3306,5,3000,10,‘proxysql‘);
admin@localhost:proxysql_admin.sock [(none)]>select * from mysql_servers order by hostgroup_id; +--------------+--------------+------+--------+--------+-------------+-----------------+---------------------+---------+----------------+----------+ | hostgroup_id | hostname | port | status | weight | compression | max_connections | max_replication_lag | use_ssl | max_latency_ms | comment | +--------------+--------------+------+--------+--------+-------------+-----------------+---------------------+---------+----------------+----------+ | 300 | 10.180.2.163 | 3306 | ONLINE | 1 | 0 | 1000 | 10 | 0 | 0 | proxysql | | 3000 | 10.180.2.163 | 3306 | ONLINE | 1 | 0 | 1000 | 10 | 0 | 0 | proxysql | | 3000 | 10.180.2.164 | 3306 | ONLINE | 5 | 0 | 1000 | 10 | 0 | 0 | proxysql | | 3000 | 10.180.2.165 | 3306 | ONLINE | 5 | 0 | 1000 | 10 | 0 | 0 | proxysql | +--------------+--------------+------+--------+--------+-------------+-----------------+---------------------+---------+----------------+----------+
注意, 这里为什么要把master 也加到读 的HG 呢,这是为了防止所有的slave 都宕机仍然可以通过master 进行读,平时配置的weight 可以相对小一些
配置后端MySQL用户
这个用户需要先在后端MySQL里真实存在,一个是监控账号、一个是程序账号。
a) 监控账号
root@localhost:mysql3306.sock [(none)]>GRANT SUPER, REPLICATION CLIENT ON *.* TO ‘proxysql‘@‘%‘ identified by ‘proxysql‘;
注意:由于需要执行show slave status的命令来获得延迟时间,所以需要权限SUPER 和 REPLICATION CLIENT。并且需要设置mysql_servers.max_replication_lag的值,由于mysql_servers.max_replication_lag仅适用于从,但也可以将其配置为所有主机,无论是从还是主(不会有任何影响)。
b)程序账号
GRANT ALL ON `sbtest`.* TO ‘sbuser‘@‘%‘ identified by ‘sbuser‘;
配置user 和HG 的对应关系 和监控账号
Admin 的后台:
admin@localhost:proxysql_admin.sock [(none)]>insert into mysql_users(username,password,active,default_hostgroup,transaction_persistent)values -> (‘sbuser‘,‘sbuser‘,1,300,1); Query OK, 1 row affected (0.00 sec)
admin@localhost:proxysql_admin.sock [(none)]>select * from mysql_users\G; *************************** 1. row *************************** username: sbuser password: sbuser active: 1 use_ssl: 0 default_hostgroup: 300 default_schema: NULL schema_locked: 0 transaction_persistent: 1 fast_forward: 0 backend: 1 frontend: 1 max_connections: 10000 1 row in set (0.00 sec)
设置健康监测账号监控后台MySQL 节点
admin@localhost:proxysql_admin.sock [(none)]>set mysql-monitor_username=‘proxysql‘; Query OK, 1 row affected (0.00 sec) admin@localhost:proxysql_admin.sock [(none)]>set mysql-monitor_password=‘proxysql‘; Query OK, 1 row affected (0.00 sec)
加载并保存配置
admin@localhost:proxysql_admin.sock [(none)]>load mysql servers to runtime; Query OK, 0 rows affected (0.01 sec) admin@localhost:proxysql_admin.sock [(none)]>load mysql users to runtime; Query OK, 0 rows affected (0.00 sec) admin@localhost:proxysql_admin.sock [(none)]>load mysql variables to runtime; Query OK, 0 rows affected (0.01 sec) admin@localhost:proxysql_admin.sock [(none)]>save mysql servers to disk; Query OK, 0 rows affected (0.03 sec) admin@localhost:proxysql_admin.sock [(none)]>save mysql users to disk; Query OK, 0 rows affected (0.02 sec) admin@localhost:proxysql_admin.sock [(none)]>save mysql variables to disk; Query OK, 74 rows affected (0.01 sec)
连接Proxy尝试做业务
sbuser@proxy1:6033 [sbtest]> use sbtest Database changed, 2 warnings sbuser@proxy1:6033 [sbtest]> create table t1 ( id int); Query OK, 0 rows affected (0.08 sec) sbuser@proxy1:6033 [sbtest]> insert into t1 select 1; Query OK, 1 row affected (0.05 sec) Records: 1 Duplicates: 0 Warnings: 0 sbuser@proxy1:6033 [sbtest]> select * from t1; +------+ | id | +------+ | 1 | +------+ 1 row in set (0.00 sec)
从Stats 库,你可以看到有类似审计的功能
admin@localhost:proxysql_admin.sock [(none)]>select* from stats.stats_mysql_query_digest; +-----------+------------+----------+--------------------+--------------------------+------------+------------+------------+----------+----------+----------+ | hostgroup | schemaname | username | digest | digest_text | count_star | first_seen | last_seen | sum_time | min_time | max_time | +-----------+------------+----------+--------------------+--------------------------+------------+------------+------------+----------+----------+----------+ | 300 | sbtest | sbuser | 0x3765930C7143F468 | select * from t1 | 1 | 1504247943 | 1504247943 | 1678 | 1678 | 1678 | | 300 | sbtest | sbuser | 0x3C44D988579DAFFA | insert into t1 values(?) | 2 | 1504247939 | 1504247941 | 12085 | 6029 | 6056 | +-----------+------------+----------+--------------------+--------------------------+------------+------------+------------+----------+----------+----------+
默认是没有配置读写分离的,所以所有的读写都分配到了master 的HG 上面,下面我们配置读写分离规则
读写分离规则
除select * from tb for update的select全部发送到slave,其他的的语句发送到master。
admin@localhost:proxysql_admin.sock [(none)]>insert into mysql_query_rules(active,match_pattern,destination_hostgroup,apply) values -> (1,‘^select.*for updates‘,300,1); Query OK, 1 row affected (0.01 sec) admin@localhost:proxysql_admin.sock [(none)]>insert into mysql_query_rules(active,match_pattern,destination_hostgroup,apply) values (1,‘^select‘,3000,1); Query OK, 1 row affected (0.00 sec) admin@localhost:proxysql_admin.sock [(none)]>load mysql query rules to runtime; Query OK, 0 rows affected (0.00 sec) admin@localhost:proxysql_admin.sock [(none)]>save mysql query rules to disk; Query OK, 0 rows affected (0.02 sec) admin@localhost:proxysql_admin.sock [(none)]>select rule_id,active,match_pattern,destination_hostgroup,apply from runtime_mysql_query_rules; +---------+--------+----------------------+-----------------------+-------+ | rule_id | active | match_pattern | destination_hostgroup | apply | +---------+--------+----------------------+-----------------------+-------+ | 1 | 1 | ^select.*for updates | 300 | 1 | | 2 | 1 | ^select | 3000 | 1 | +---------+--------+----------------------+-----------------------+-------+ 2 rows in set (0.00 sec)
再次进行读写测试
先清空stats 表
select * from stats_mysql_query_digest_reset;
admin@localhost:proxysql_admin.sock [(none)]>select * from stats_mysql_query_digest; +-----------+------------+----------+--------------------+-----------------------------+------------+------------+------------+----------+----------+----------+ | hostgroup | schemaname | username | digest | digest_text | count_star | first_seen | last_seen | sum_time | min_time | max_time | +-----------+------------+----------+--------------------+-----------------------------+------------+------------+------------+----------+----------+----------+ | 3000 | sbtest | sbuser | 0x3DCE919B79C9576C | select * from t1 where id=? | 4 | 1504248872 | 1504248878 | 8218 | 1267 | 2707 | | 3000 | sbtest | sbuser | 0x3765930C7143F468 | select * from t1 | 1 | 1504248861 | 1504248861 | 2686 | 2686 | 2686 | | 300 | sbtest | sbuser | 0x3C44D988579DAFFA | insert into t1 values(?) | 3 | 1504248850 | 1504248855 | 15143 | 4029 | 6446 | +-----------+------------+----------+--------------------+-----------------------------+------------+------------+------------+----------+----------+----------+
可以看到读已经分发到slave 上,写还是在master,但是怎么知道发送到了3000HG的哪台slave 上?
下面配置和MHA 的集成
mysql_replication_hostgroups 表的主要作用是监视指定主机组中所有服务器的read_only值,并且根据read_only的值将服务器分配给写入器或读取器主机组,定义 hostgroup 的主从关系。ProxySQL monitor 模块会监控 HG 后端所有servers 的 read_only 变量,如果发现从库的 read_only 变为0、主库变为1,则认为角色互换了,自动改写 mysql_servers 表里面 hostgroup 关系,达到自动 Failover 效果。
admin@localhost:proxysql_admin.sock [(none)]>insert into mysql_replication_hostgroups(writer_hostgroup,reader_hostgroup,comment) values (300,3000,‘read_write_split‘); Query OK, 1 row affected (0.00 sec) admin@localhost:proxysql_admin.sock [(none)]>load mysql servers to runtime; Query OK, 0 rows affected (0.01 sec) admin@localhost:proxysql_admin.sock [(none)]>save mysql servers to disk; Query OK, 0 rows affected (0.06 sec) admin@localhost:proxysql_admin.sock [(none)]>select * from runtime_mysql_replication_hostgroups; +------------------+------------------+------------------+ | writer_hostgroup | reader_hostgroup | comment | +------------------+------------------+------------------+ | 300 | 3000 | read_write_split | +------------------+------------------+------------------+ 1 row in set (0.00 sec)
手工在线切换MHA:

[root@MHA-S2 mha]# masterha_master_switch --master_state=alive --conf=/etc/mha/app1.cnf --new_master_host=MHA-S1 --new_master_port=3306 --orig_master_is_new_slave Fri Sep 1 17:00:14 2017 - [info] MHA::MasterRotate version 0.57. Fri Sep 1 17:00:14 2017 - [info] Starting online master switch.. Fri Sep 1 17:00:14 2017 - [info] Fri Sep 1 17:00:14 2017 - [info] * Phase 1: Configuration Check Phase.. Fri Sep 1 17:00:14 2017 - [info] Fri Sep 1 17:00:14 2017 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping. Fri Sep 1 17:00:14 2017 - [info] Reading application default configuration from /etc/mha/app1.cnf.. Fri Sep 1 17:00:14 2017 - [info] Reading server configuration from /etc/mha/app1.cnf.. Fri Sep 1 17:00:14 2017 - [info] GTID failover mode = 1 Fri Sep 1 17:00:14 2017 - [info] Current Alive Master: MHA-M1(10.180.2.163:3306) Fri Sep 1 17:00:14 2017 - [info] Alive Slaves: Fri Sep 1 17:00:14 2017 - [info] MHA-S1(10.180.2.164:3306) Version=5.7.18-log (oldest major version between slaves) log-bin:enabled Fri Sep 1 17:00:14 2017 - [info] GTID ON Fri Sep 1 17:00:14 2017 - [info] Replicating from MHA-M1(10.180.2.163:3306) Fri Sep 1 17:00:14 2017 - [info] Primary candidate for the new Master (candidate_master is set) Fri Sep 1 17:00:14 2017 - [info] MHA-S2(10.180.2.165:3306) Version=5.7.18-log (oldest major version between slaves) log-bin:enabled Fri Sep 1 17:00:14 2017 - [info] GTID ON Fri Sep 1 17:00:14 2017 - [info] Replicating from MHA-M1(10.180.2.163:3306) It is better to execute FLUSH NO_WRITE_TO_BINLOG TABLES on the master before switching. Is it ok to execute on MHA-M1(10.180.2.163:3306)? (YES/no): yes Fri Sep 1 17:00:46 2017 - [info] Executing FLUSH NO_WRITE_TO_BINLOG TABLES. This may take long time.. Fri Sep 1 17:00:46 2017 - [info] ok. Fri Sep 1 17:00:46 2017 - [info] Checking MHA is not monitoring or doing failover.. Fri Sep 1 17:00:46 2017 - [info] Checking replication health on MHA-S1.. Fri Sep 1 17:00:46 2017 - [info] ok. Fri Sep 1 17:00:46 2017 - [info] Checking replication health on MHA-S2.. Fri Sep 1 17:00:46 2017 - [info] ok. Fri Sep 1 17:00:46 2017 - [info] MHA-S1 can be new master. Fri Sep 1 17:00:46 2017 - [info] From: MHA-M1(10.180.2.163:3306) (current master) +--MHA-S1(10.180.2.164:3306) +--MHA-S2(10.180.2.165:3306) To: MHA-S1(10.180.2.164:3306) (new master) +--MHA-S2(10.180.2.165:3306) +--MHA-M1(10.180.2.163:3306) Starting master switch from MHA-M1(10.180.2.163:3306) to MHA-S1(10.180.2.164:3306)? (yes/NO): yes Fri Sep 1 17:00:59 2017 - [info] Checking whether MHA-S1(10.180.2.164:3306) is ok for the new master.. Fri Sep 1 17:00:59 2017 - [info] ok. Fri Sep 1 17:00:59 2017 - [info] MHA-M1(10.180.2.163:3306): SHOW SLAVE STATUS returned empty result. To check replication filtering rules, temporarily executing CHANGE MASTER to a dummy host. Fri Sep 1 17:00:59 2017 - [info] MHA-M1(10.180.2.163:3306): Resetting slave pointing to the dummy host. Fri Sep 1 17:00:59 2017 - [info] ** Phase 1: Configuration Check Phase completed. Fri Sep 1 17:00:59 2017 - [info] Fri Sep 1 17:00:59 2017 - [info] * Phase 2: Rejecting updates Phase.. Fri Sep 1 17:00:59 2017 - [info] Fri Sep 1 17:00:59 2017 - [info] Executing master ip online change script to disable write on the current master: Fri Sep 1 17:00:59 2017 - [info] /usr/local/bin/master_ip_online_change --command=stop --orig_master_host=MHA-M1 --orig_master_ip=10.180.2.163 --orig_master_port=3306 --orig_master_user=‘root‘ --new_master_host=MHA-S1 --new_master_ip=10.180.2.164 --new_master_port=3306 --new_master_user=‘root‘ --orig_master_ssh_user=root --new_master_ssh_user=root --orig_master_is_new_slave --orig_master_password=xxx --new_master_password=xxx Unknown option: orig_master_ssh_user Unknown option: new_master_ssh_user Unknown option: orig_master_is_new_slave Unknown option: orig_master_password Unknown option: new_master_password Fri Sep 1 17:00:59 2017 957805 Set read_only on the new master.. ok. Fri Sep 1 17:00:59 2017 963583 Waiting all running 2 threads are disconnected.. (max 1500 milliseconds) {‘Time‘ => ‘1711541‘,‘Command‘ => ‘Binlog Dump GTID‘,‘db‘ => undef,‘Id‘ => ‘16‘,‘Info‘ => undef,‘User‘ => ‘repl‘,‘State‘ => ‘Master has sent all binlog to slave; waiting for more updates‘,‘Host‘ => ‘MHA-S2:44384‘} {‘Time‘ => ‘1711541‘,‘Command‘ => ‘Binlog Dump GTID‘,‘db‘ => undef,‘Id‘ => ‘17‘,‘Info‘ => undef,‘User‘ => ‘repl‘,‘State‘ => ‘Master has sent all binlog to slave; waiting for more updates‘,‘Host‘ => ‘MHA-S1:52664‘} Fri Sep 1 17:01:00 2017 464591 Waiting all running 3 threads are disconnected.. (max 1000 milliseconds) {‘Time‘ => ‘1711542‘,‘Command‘ => ‘Binlog Dump GTID‘,‘db‘ => undef,‘Id‘ => ‘16‘,‘Info‘ => undef,‘User‘ => ‘repl‘,‘State‘ => ‘Master has sent all binlog to slave; waiting for more updates‘,‘Host‘ => ‘MHA-S2:44384‘} {‘Time‘ => ‘1711542‘,‘Command‘ => ‘Binlog Dump GTID‘,‘db‘ => undef,‘Id‘ => ‘17‘,‘Info‘ => undef,‘User‘ => ‘repl‘,‘State‘ => ‘Master has sent all binlog to slave; waiting for more updates‘,‘Host‘ => ‘MHA-S1:52664‘} {‘Time‘ => ‘0‘,‘Command‘ => ‘Sleep‘,‘db‘ => undef,‘Id‘ => ‘1418‘,‘Info‘ => undef,‘User‘ => ‘proxysql‘,‘State‘ => ‘‘,‘Host‘ => ‘10.180.3.1:58934‘} Fri Sep 1 17:01:00 2017 966039 Waiting all running 3 threads are disconnected.. (max 500 milliseconds) {‘Time‘ => ‘1711542‘,‘Command‘ => ‘Binlog Dump GTID‘,‘db‘ => undef,‘Id‘ => ‘16‘,‘Info‘ => undef,‘User‘ => ‘repl‘,‘State‘ => ‘Master has sent all binlog to slave; waiting for more updates‘,‘Host‘ => ‘MHA-S2:44384‘} {‘Time‘ => ‘1711542‘,‘Command‘ => ‘Binlog Dump GTID‘,‘db‘ => undef,‘Id‘ => ‘17‘,‘Info‘ => undef,‘User‘ => ‘repl‘,‘State‘ => ‘Master has sent all binlog to slave; waiting for more updates‘,‘Host‘ => ‘MHA-S1:52664‘} {‘Time‘ => ‘0‘,‘Command‘ => ‘Sleep‘,‘db‘ => undef,‘Id‘ => ‘1418‘,‘Info‘ => undef,‘User‘ => ‘proxysql‘,‘State‘ => ‘‘,‘Host‘ => ‘10.180.3.1:58934‘} Fri Sep 1 17:01:01 2017 466934 Set read_only=1 on the orig master.. ok. Fri Sep 1 17:01:01 2017 469136 Waiting all running 2 queries are disconnected.. (max 500 milliseconds) {‘Time‘ => ‘1711543‘,‘Command‘ => ‘Binlog Dump GTID‘,‘db‘ => undef,‘Id‘ => ‘16‘,‘Info‘ => undef,‘User‘ => ‘repl‘,‘State‘ => ‘Master has sent all binlog to slave; waiting for more updates‘,‘Host‘ => ‘MHA-S2:44384‘} {‘Time‘ => ‘1711543‘,‘Command‘ => ‘Binlog Dump GTID‘,‘db‘ => undef,‘Id‘ => ‘17‘,‘Info‘ => undef,‘User‘ => ‘repl‘,‘State‘ => ‘Master has sent all binlog to slave; waiting for more updates‘,‘Host‘ => ‘MHA-S1:52664‘} Disabling the VIP on old master: MHA-M1 Fri Sep 1 17:01:02 2017 091930 Killing all application threads.. Fri Sep 1 17:01:02 2017 093785 done. Fri Sep 1 17:01:02 2017 - [info] ok. Fri Sep 1 17:01:02 2017 - [info] Locking all tables on the orig master to reject updates from everybody (including root): Fri Sep 1 17:01:02 2017 - [info] Executing FLUSH TABLES WITH READ LOCK.. Fri Sep 1 17:01:02 2017 - [info] ok. Fri Sep 1 17:01:02 2017 - [info] Orig master binlog:pos is 3306-binlog.000005:3916. Fri Sep 1 17:01:02 2017 - [info] Waiting to execute all relay logs on MHA-S1(10.180.2.164:3306).. Fri Sep 1 17:01:02 2017 - [info] master_pos_wait(3306-binlog.000005:3916) completed on MHA-S1(10.180.2.164:3306). Executed 0 events. Fri Sep 1 17:01:02 2017 - [info] done. Fri Sep 1 17:01:02 2017 - [info] Getting new master‘s binlog name and position.. Fri Sep 1 17:01:02 2017 - [info] 3306-binlog.000003:61948637 Fri Sep 1 17:01:02 2017 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST=‘MHA-S1 or 10.180.2.164‘, MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER=‘repl‘, MASTER_PASSWORD=‘xxx‘; Fri Sep 1 17:01:02 2017 - [info] Executing master ip online change script to allow write on the new master: Fri Sep 1 17:01:02 2017 - [info] /usr/local/bin/master_ip_online_change --command=start --orig_master_host=MHA-M1 --orig_master_ip=10.180.2.163 --orig_master_port=3306 --orig_master_user=‘root‘ --new_master_host=MHA-S1 --new_master_ip=10.180.2.164 --new_master_port=3306 --new_master_user=‘root‘ --orig_master_ssh_user=root --new_master_ssh_user=root --orig_master_is_new_slave --orig_master_password=xxx --new_master_password=xxx Unknown option: orig_master_ssh_user Unknown option: new_master_ssh_user Unknown option: orig_master_is_new_slave Unknown option: orig_master_password Unknown option: new_master_password Fri Sep 1 17:01:02 2017 282150 Set read_only=0 on the new master. Enabling the VIP - 10.180.2.168/19 on the new master - MHA-S1 Fri Sep 1 17:01:02 2017 - [info] ok. Fri Sep 1 17:01:02 2017 - [info] Fri Sep 1 17:01:02 2017 - [info] * Switching slaves in parallel.. Fri Sep 1 17:01:02 2017 - [info] Fri Sep 1 17:01:02 2017 - [info] -- Slave switch on host MHA-S2(10.180.2.165:3306) started, pid: 7360 Fri Sep 1 17:01:02 2017 - [info] Fri Sep 1 17:01:03 2017 - [info] Log messages from MHA-S2 ... Fri Sep 1 17:01:03 2017 - [info] Fri Sep 1 17:01:02 2017 - [info] Waiting to execute all relay logs on MHA-S2(10.180.2.165:3306).. Fri Sep 1 17:01:02 2017 - [info] master_pos_wait(3306-binlog.000005:3916) completed on MHA-S2(10.180.2.165:3306). Executed 0 events. Fri Sep 1 17:01:02 2017 - [info] done. Fri Sep 1 17:01:02 2017 - [info] Resetting slave MHA-S2(10.180.2.165:3306) and starting replication from the new master MHA-S1(10.180.2.164:3306).. Fri Sep 1 17:01:02 2017 - [info] Executed CHANGE MASTER. Fri Sep 1 17:01:03 2017 - [info] Slave started. Fri Sep 1 17:01:03 2017 - [info] End of log messages from MHA-S2 ... Fri Sep 1 17:01:03 2017 - [info] Fri Sep 1 17:01:03 2017 - [info] -- Slave switch on host MHA-S2(10.180.2.165:3306) succeeded. Fri Sep 1 17:01:03 2017 - [info] Unlocking all tables on the orig master: Fri Sep 1 17:01:03 2017 - [info] Executing UNLOCK TABLES.. Fri Sep 1 17:01:03 2017 - [info] ok. Fri Sep 1 17:01:03 2017 - [info] Starting orig master as a new slave.. Fri Sep 1 17:01:03 2017 - [info] Resetting slave MHA-M1(10.180.2.163:3306) and starting replication from the new master MHA-S1(10.180.2.164:3306).. Fri Sep 1 17:01:03 2017 - [info] Executed CHANGE MASTER. Fri Sep 1 17:01:04 2017 - [info] Slave started. Fri Sep 1 17:01:04 2017 - [info] All new slave servers switched successfully. Fri Sep 1 17:01:04 2017 - [info] Fri Sep 1 17:01:04 2017 - [info] * Phase 5: New master cleanup phase.. Fri Sep 1 17:01:04 2017 - [info] Fri Sep 1 17:01:04 2017 - [info] MHA-S1: Resetting slave info succeeded. Fri Sep 1 17:01:04 2017 - [info] Switching master to MHA-S1(10.180.2.164:3306) completed successfully.
切换完再次查看mysql_servers的HG 分组
admin@localhost:proxysql_admin.sock [(none)]>select * from runtime_mysql_servers; +--------------+--------------+------+--------+--------+-------------+-----------------+---------------------+---------+----------------+----------+ | hostgroup_id | hostname | port | status | weight | compression | max_connections | max_replication_lag | use_ssl | max_latency_ms | comment | +--------------+--------------+------+--------+--------+-------------+-----------------+---------------------+---------+----------------+----------+ | 3000 | 10.180.2.165 | 3306 | ONLINE | 5 | 0 | 1000 | 10 | 0 | 0 | proxysql | | 3000 | 10.180.2.163 | 3306 | ONLINE | 1 | 0 | 1000 | 10 | 0 | 0 | proxysql | | 3000 | 10.180.2.164 | 3306 | ONLINE | 5 | 0 | 1000 | 10 | 0 | 0 | proxysql | | 300 | 10.180.2.164 | 3306 | ONLINE | 5 | 0 | 1000 | 10 | 0 | 0 | proxysql | +--------------+--------------+------+--------+--------+-------------+-----------------+---------------------+---------+----------------+----------+ 4 rows in set (0.00 sec)
可以看到S1 已经自动变到300的写分组,但是发现weight 没有变化,这样切换后新的master 承受的读请求比原来会大
进行读写的测试
admin@localhost:proxysql_admin.sock [(none)]>select * from stats_mysql_query_digest; +-----------+------------+----------+--------------------+-----------------------------+------------+------------+------------+----------+----------+----------+ | hostgroup | schemaname | username | digest | digest_text | count_star | first_seen | last_seen | sum_time | min_time | max_time | +-----------+------------+----------+--------------------+-----------------------------+------------+------------+------------+----------+----------+----------+ | 300 | sbtest | sbuser | 0xE07EF74E5090A618 | show create table t1 | 1 | 1504256708 | 1504256708 | 1135 | 1135 | 1135 | | 300 | sbtest | sbuser | 0x74A739578E179F19 | show processlist | 1 | 1504256702 | 1504256702 | 682 | 682 | 682 | | 300 | sbtest | sbuser | 0x99531AEFF718C501 | show tables | 1 | 1504256697 | 1504256697 | 3345 | 3345 | 3345 | | 3000 | sbtest | sbuser | 0x3DCE919B79C9576C | select * from t1 where id=? | 8 | 1504248872 | 1504256695 | 17142 | 1267 | 3708 | | 3000 | sbtest | sbuser | 0x3765930C7143F468 | select * from t1 | 2 | 1504248861 | 1504256726 | 4387 | 1701 | 2686 | | 300 | sbtest | sbuser | 0x3C44D988579DAFFA | insert into t1 values(?) | 4 | 1504248850 | 1504256723 | 22325 | 4029 | 7182 | +-----------+------------+----------+--------------------+-----------------------------+------------+------------+------------+----------+----------+----------+ 6 rows in set (0.00 sec)
可以看出读写分离正常。
下面进行master 意外宕机测试
Fri Sep 1 17:07:42 2017 - [info] Reading application default configuration from /etc/mha/app1.cnf.. Fri Sep 1 17:07:42 2017 - [info] Reading server configuration from /etc/mha/app1.cnf.. Fri Sep 1 17:08:44 2017 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping. Fri Sep 1 17:08:44 2017 - [info] Reading application default configuration from /etc/mha/app1.cnf.. Fri Sep 1 17:08:44 2017 - [info] Reading server configuration from /etc/mha/app1.cnf.. orking directory. Check for details, and consider setting --workdir separately. Fri Sep 1 17:07:43 2017 - [info] GTID failover mode = 1 Fri Sep 1 17:07:43 2017 - [info] Dead Servers: Fri Sep 1 17:07:43 2017 - [info] Alive Servers: Fri Sep 1 17:07:43 2017 - [info] MHA-M1(10.180.2.163:3306) Fri Sep 1 17:07:43 2017 - [info] MHA-S1(10.180.2.164:3306) Fri Sep 1 17:07:43 2017 - [info] MHA-S2(10.180.2.165:3306) Fri Sep 1 17:07:43 2017 - [info] Alive Slaves: Fri Sep 1 17:07:43 2017 - [info] MHA-M1(10.180.2.163:3306) Version=5.7.18-log (oldest major version between slaves) log-bin:enabled Fri Sep 1 17:07:43 2017 - [info] GTID ON Fri Sep 1 17:07:43 2017 - [info] Replicating from MHA-S1(10.180.2.164:3306) Fri Sep 1 17:07:43 2017 - [info] MHA-S2(10.180.2.165:3306) Version=5.7.18-log (oldest major version between slaves) log-bin:enabled Fri Sep 1 17:07:43 2017 - [info] GTID ON Fri Sep 1 17:07:43 2017 - [info] Checking slave configurations.. Fri Sep 1 17:07:43 2017 - [info] Checking replication filtering settings.. Fri Sep 1 17:07:43 2017 - [info] binlog_do_db= , binlog_ignore_db= Fri Sep 1 17:07:43 2017 - [info] Replication filtering check ok. Fri Sep 1 17:07:43 2017 - [info] GTID (with auto-pos) is supported. Skipping all SSH and Node package checking. Fri Sep 1 17:07:43 2017 - [info] Checking SSH publickey authentication settings on the current master.. Fri Sep 1 17:07:43 2017 - [info] HealthCheck: SSH to MHA-S1 is reachable. Fri Sep 1 17:07:43 2017 - [info] MHA-S1(10.180.2.164:3306) (current master) +--MHA-M1(10.180.2.163:3306) +--MHA-S2(10.180.2.165:3306) Fri Sep 1 17:07:43 2017 - [info] Checking master_ip_failover_script status: Fri Sep 1 17:07:43 2017 - [info] /usr/local/bin/master_ip_failover --command=status --ssh_user=root --orig_master_host=MHA-S1 --orig_master_ip=10.180.2.164 --orig_master_port=3306 IN SCRIPT TEST====/sbin/ifconfig eth1:1 down==/sbin/ifconfig eth1:1 10.180.2.168/24=== Checking the Status of the script.. OK Fri Sep 1 17:07:43 2017 - [info] OK. Fri Sep 1 17:07:43 2017 - [warning] shutdown_script is not defined. Fri Sep 1 17:07:43 2017 - [info] Set master ping interval 1 seconds. Fri Sep 1 17:07:43 2017 - [info] Set secondary check script: /usr/local/bin/masterha_secondary_check -s MHA-S1 -s MHA-S2 Fri Sep 1 17:07:43 2017 - [info] Starting ping health check on MHA-S1(10.180.2.164:3306).. Fri Sep 1 17:07:43 2017 - [info] Ping(SELECT) succeeded, waiting until MySQL doesn‘t respond.. Fri Sep 1 17:08:41 2017 - [warning] Got error on MySQL select ping: 2006 (MySQL server has gone away) Fri Sep 1 17:08:41 2017 - [info] Executing SSH check script: exit 0 Fri Sep 1 17:08:41 2017 - [info] HealthCheck: SSH to MHA-S1 is reachable. Monitoring server MHA-S1 is reachable, Master is not reachable from MHA-S1. OK. Monitoring server MHA-S2 is reachable, Master is not reachable from MHA-S2. OK. Fri Sep 1 17:08:41 2017 - [info] Master is not reachable from all other monitoring servers. Failover should start. Fri Sep 1 17:08:42 2017 - [warning] Got error on MySQL connect: 2013 (Lost connection to MySQL server at ‘reading initial communication packet‘, system error: 111) Fri Sep 1 17:08:42 2017 - [warning] Connection failed 2 time(s).. Fri Sep 1 17:08:43 2017 - [warning] Got error on MySQL connect: 2013 (Lost connection to MySQL server at ‘reading initial communication packet‘, system error: 111) Fri Sep 1 17:08:43 2017 - [warning] Connection failed 3 time(s).. Fri Sep 1 17:08:44 2017 - [warning] Got error on MySQL connect: 2013 (Lost connection to MySQL server at ‘reading initial communication packet‘, system error: 111) Fri Sep 1 17:08:44 2017 - [warning] Connection failed 4 time(s).. Fri Sep 1 17:08:44 2017 - [warning] Master is not reachable from health checker! Fri Sep 1 17:08:44 2017 - [warning] Master MHA-S1(10.180.2.164:3306) is not reachable! Fri Sep 1 17:08:44 2017 - [warning] SSH is reachable. Fri Sep 1 17:08:44 2017 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping. Fri Sep 1 17:08:44 2017 - [info] Reading application default configuration from /etc/mha/app1.cnf.. Fri Sep 1 17:08:44 2017 - [info] Reading server configuration from /etc/mha/app1.cnf.. Fri Sep 1 17:08:44 2017 - [info] GTID failover mode = 1 Fri Sep 1 17:08:44 2017 - [info] Dead Servers: Fri Sep 1 17:08:44 2017 - [info] MHA-S1(10.180.2.164:3306) Fri Sep 1 17:08:44 2017 - [info] Alive Servers: Fri Sep 1 17:08:44 2017 - [info] MHA-M1(10.180.2.163:3306) Fri Sep 1 17:08:44 2017 - [info] MHA-S2(10.180.2.165:3306) Fri Sep 1 17:08:44 2017 - [info] Alive Slaves: Fri Sep 1 17:08:44 2017 - [info] MHA-M1(10.180.2.163:3306) Version=5.7.18-log (oldest major version between slaves) log-bin:enabled Fri Sep 1 17:08:44 2017 - [info] GTID ON Fri Sep 1 17:08:44 2017 - [info] Replicating from MHA-S1(10.180.2.164:3306) Fri Sep 1 17:08:44 2017 - [info] MHA-S2(10.180.2.165:3306) Version=5.7.18-log (oldest major version between slaves) log-bin:enabled Fri Sep 1 17:08:44 2017 - [info] GTID ON Fri Sep 1 17:08:44 2017 - [info] Replicating from MHA-S1(10.180.2.164:3306) Fri Sep 1 17:08:44 2017 - [info] Checking slave configurations.. Fri Sep 1 17:08:44 2017 - [info] Checking replication filtering settings.. Fri Sep 1 17:08:44 2017 - [info] Replication filtering check ok. Fri Sep 1 17:08:44 2017 - [info] Master is down! Fri Sep 1 17:08:44 2017 - [info] Terminating monitoring script. Fri Sep 1 17:08:44 2017 - [info] Got exit code 20 (Master dead). Fri Sep 1 17:08:44 2017 - [info] Fri Sep 1 17:08:44 2017 - [info] * Phase 1: Configuration Check Phase.. Fri Sep 1 17:08:44 2017 - [info] Fri Sep 1 17:08:44 2017 - [info] GTID failover mode = 1 Fri Sep 1 17:08:44 2017 - [info] Dead Servers: Fri Sep 1 17:08:44 2017 - [info] MHA-S1(10.180.2.164:3306) Fri Sep 1 17:08:44 2017 - [info] Checking master reachability via MySQL(double check)... Fri Sep 1 17:08:44 2017 - [info] ok. Fri Sep 1 17:08:44 2017 - [info] Alive Servers: Fri Sep 1 17:08:44 2017 - [info] MHA-M1(10.180.2.163:3306) Fri Sep 1 17:08:44 2017 - [info] MHA-S2(10.180.2.165:3306) Fri Sep 1 17:08:44 2017 - [info] Alive Slaves: Fri Sep 1 17:08:44 2017 - [info] MHA-M1(10.180.2.163:3306) Version=5.7.18-log (oldest major version between slaves) log-bin:enabled Fri Sep 1 17:08:44 2017 - [info] GTID ON Fri Sep 1 17:08:44 2017 - [info] Replicating from MHA-S1(10.180.2.164:3306) Fri Sep 1 17:08:44 2017 - [info] MHA-S2(10.180.2.165:3306) Version=5.7.18-log (oldest major version between slaves) log-bin:enabled Fri Sep 1 17:08:44 2017 - [info] GTID ON Fri Sep 1 17:08:44 2017 - [info] Replicating from MHA-S1(10.180.2.164:3306) Fri Sep 1 17:08:44 2017 - [info] Starting GTID based failover. Fri Sep 1 17:08:44 2017 - [info] Fri Sep 1 17:08:44 2017 - [info] ** Phase 1: Configuration Check Phase completed. Fri Sep 1 17:08:44 2017 - [info] Fri Sep 1 17:08:44 2017 - [info] * Phase 2: Dead Master Shutdown Phase.. Fri Sep 1 17:08:44 2017 - [info] Fri Sep 1 17:08:44 2017 - [info] Forcing shutdown so that applications never connect to the current master.. Fri Sep 1 17:08:44 2017 - [info] Executing master IP deactivation script: IN SCRIPT TEST====/sbin/ifconfig eth1:1 down==/sbin/ifconfig eth1:1 10.180.2.168/24=== Disabling the VIP on old master: MHA-S1 Fri Sep 1 17:08:44 2017 - [info] done. Fri Sep 1 17:08:44 2017 - [warning] shutdown_script is not set. Skipping explicit shutting down of the dead master. Fri Sep 1 17:08:44 2017 - [info] * Phase 2: Dead Master Shutdown Phase completed. Fri Sep 1 17:08:44 2017 - [info] Fri Sep 1 17:08:44 2017 - [info] * Phase 3: Master Recovery Phase.. Fri Sep 1 17:08:44 2017 - [info] Fri Sep 1 17:08:44 2017 - [info] * Phase 3.1: Getting Latest Slaves Phase.. Fri Sep 1 17:08:44 2017 - [info] Fri Sep 1 17:08:44 2017 - [info] The latest binary log file/position on all slaves is 3306-binlog.000003:61948894 Fri Sep 1 17:08:44 2017 - [info] Retrieved Gtid Set: 1c2dc99f-7b57-11e7-a280-005056b665cb:4 Fri Sep 1 17:08:44 2017 - [info] Latest slaves (Slaves that received relay log files to the latest): Fri Sep 1 17:08:44 2017 - [info] MHA-M1(10.180.2.163:3306) Version=5.7.18-log (oldest major version between slaves) log-bin:enabled Fri Sep 1 17:08:44 2017 - [info] GTID ON Fri Sep 1 17:08:44 2017 - [info] Replicating from MHA-S1(10.180.2.164:3306) Fri Sep 1 17:08:44 2017 - [info] MHA-S2(10.180.2.165:3306) Version=5.7.18-log (oldest major version between slaves) log-bin:enabled Fri Sep 1 17:08:44 2017 - [info] GTID ON Fri Sep 1 17:08:44 2017 - [info] Replicating from MHA-S1(10.180.2.164:3306) Fri Sep 1 17:08:44 2017 - [info] The oldest binary log file/position on all slaves is 3306-binlog.000003:61948894 Fri Sep 1 17:08:44 2017 - [info] Retrieved Gtid Set: 1c2dc99f-7b57-11e7-a280-005056b665cb:4 Fri Sep 1 17:08:44 2017 - [info] Oldest slaves: Fri Sep 1 17:08:44 2017 - [info] MHA-M1(10.180.2.163:3306) Version=5.7.18-log (oldest major version between slaves) log-bin:enabled Fri Sep 1 17:08:44 2017 - [info] GTID ON Fri Sep 1 17:08:44 2017 - [info] GTID ON Fri Sep 1 17:08:44 2017 - [info] Replicating from MHA-S1(10.180.2.164:3306) Fri Sep 1 17:08:44 2017 - [info] Fri Sep 1 17:08:44 2017 - [info] Searching new master from slaves.. Fri Sep 1 17:08:44 2017 - [info] Candidate masters from the configuration file: Fri Sep 1 17:08:44 2017 - [info] Non-candidate masters: Fri Sep 1 17:08:44 2017 - [info] New master is MHA-M1(10.180.2.163:3306) Fri Sep 1 17:08:44 2017 - [info] Starting master failover.. Fri Sep 1 17:08:44 2017 - [info] From: MHA-S1(10.180.2.164:3306) (current master) +--MHA-M1(10.180.2.163:3306) +--MHA-S2(10.180.2.165:3306) To: MHA-M1(10.180.2.163:3306) (new master) +--MHA-S2(10.180.2.165:3306) Fri Sep 1 17:08:44 2017 - [info] Fri Sep 1 17:08:44 2017 - [info] * Phase 3.3: New Master Recovery Phase.. Fri Sep 1 17:08:44 2017 - [info] Fri Sep 1 17:08:44 2017 - [info] Waiting all logs to be applied.. Fri Sep 1 17:08:44 2017 - [info] 3306-binlog.000005:4162 Fri Sep 1 17:08:44 2017 - [info] Master Recovery succeeded. File:Pos:Exec_Gtid_Set: 3306-binlog.000005, 4162, 1c2dc99f-7b57-11e7-a280-005056b665cb:1-4, a5757eae-7981-11e7-82c7-005056b662d3:1-32225 Fri Sep 1 17:08:44 2017 - [info] Executing master IP activate script: Unknown option: new_master_user Unknown option: new_master_password IN SCRIPT TEST====/sbin/ifconfig eth1:1 down==/sbin/ifconfig eth1:1 10.180.2.168/24=== Enabling the VIP - 10.180.2.168/24 on the new master - MHA-M1 Fri Sep 1 17:08:44 2017 - [info] OK. Fri Sep 1 17:08:44 2017 - [info] Setting read_only=0 on MHA-M1(10.180.2.163:3306).. Fri Sep 1 17:08:44 2017 - [info] ok. Fri Sep 1 17:08:44 2017 - [info] ** Finished master recovery successfully. Fri Sep 1 17:08:44 2017 - [info] * Phase 3: Master Recovery Phase completed. Fri Sep 1 17:08:44 2017 - [info] Fri Sep 1 17:08:44 2017 - [info] * Phase 4: Slaves Recovery Phase.. Fri Sep 1 17:08:44 2017 - [info] Fri Sep 1 17:08:44 2017 - [info] Fri Sep 1 17:08:44 2017 - [info] * Phase 4.1: Starting Slaves in parallel.. Fri Sep 1 17:08:44 2017 - [info] Fri Sep 1 17:08:46 2017 - [info] Fri Sep 1 17:08:46 2017 - [info] Log messages from MHA-S2 ... Fri Sep 1 17:08:46 2017 - [info] Fri Sep 1 17:08:44 2017 - [info] Resetting slave MHA-S2(10.180.2.165:3306) and starting replication from the new master MHA-M1(10.180.2.163:3306).. Fri Sep 1 17:08:44 2017 - [info] Executed CHANGE MASTER. Fri Sep 1 17:08:46 2017 - [info] Slave started. Fri Sep 1 17:08:46 2017 - [info] gtid_wait(1c2dc99f-7b57-11e7-a280-005056b665cb:1-4, a5757eae-7981-11e7-82c7-005056b662d3:1-32225) completed on MHA-S2(10.180.2.165:3306). Executed 0 events. Fri Sep 1 17:08:46 2017 - [info] End of log messages from MHA-S2. Fri Sep 1 17:08:46 2017 - [info] -- Slave on host MHA-S2(10.180.2.165:3306) started. Fri Sep 1 17:08:46 2017 - [info] All new slave servers recovered successfully. Fri Sep 1 17:08:46 2017 - [info] Fri Sep 1 17:08:46 2017 - [info] * Phase 5: New master cleanup phase.. Fri Sep 1 17:08:46 2017 - [info] Fri Sep 1 17:08:46 2017 - [info] Resetting slave info on the new master.. Fri Sep 1 17:08:46 2017 - [info] MHA-M1: Resetting slave info succeeded. Fri Sep 1 17:08:46 2017 - [info] Master failover to MHA-M1(10.180.2.163:3306) completed successfully. Fri Sep 1 17:08:46 2017 - [info] Deleted server2 entry from /etc/mha/app1.cnf . Fri Sep 1 17:08:46 2017 - [info] ----- Failover Report ----- app1: MySQL Master failover MHA-S1(10.180.2.164:3306) to MHA-M1(10.180.2.163:3306) succeeded Master MHA-S1(10.180.2.164:3306) is down! Check MHA Manager logs at MHA-S2:/var/log/masterha/app1/manager.log for details. Started automated(non-interactive) failover. Invalidated master IP address on MHA-S1(10.180.2.164:3306) Selected MHA-M1(10.180.2.163:3306) as a new master. MHA-M1(10.180.2.163:3306): OK: Applying all logs succeeded. MHA-M1(10.180.2.163:3306): OK: Activated master IP address. MHA-S2(10.180.2.165:3306): OK: Slave started, replicating from MHA-M1(10.180.2.163:3306) MHA-M1(10.180.2.163:3306): Resetting slave info succeeded. Master failover to MHA-M1(10.180.2.163:3306) completed successfully. Fri Sep 1 17:08:46 2017 - [info] Sending mail..
可以看到宕机的master 被踢出ProxySQL,设置为SHUNNED
admin@localhost:proxysql_admin.sock [(none)]>select * from runtime_mysql_servers; +--------------+--------------+------+---------+--------+-------------+-----------------+---------------------+---------+----------------+----------+ | hostgroup_id | hostname | port | status | weight | compression | max_connections | max_replication_lag | use_ssl | max_latency_ms | comment | +--------------+--------------+------+---------+--------+-------------+-----------------+---------------------+---------+----------------+----------+ | 3000 | 10.180.2.165 | 3306 | ONLINE | 5 | 0 | 1000 | 10 | 0 | 0 | proxysql | | 3000 | 10.180.2.163 | 3306 | ONLINE | 1 | 0 | 1000 | 10 | 0 | 0 | proxysql | | 3000 | 10.180.2.164 | 3306 | SHUNNED | 5 | 0 | 1000 | 10 | 0 | 0 | proxysql | | 300 | 10.180.2.163 | 3306 | ONLINE | 1 | 0 | 1000 | 10 | 0 | 0 | proxysql | +--------------+--------------+------+---------+--------+-------------+-----------------+---------------------+---------+----------------+----------+ 4 rows in set (0.00 sec)
读写测试依然是正常的
admin@localhost:proxysql_admin.sock [(none)]>select * from stats_mysql_query_digest; +-----------+------------+----------+--------------------+-----------------------------+------------+------------+------------+----------+----------+----------+ | hostgroup | schemaname | username | digest | digest_text | count_star | first_seen | last_seen | sum_time | min_time | max_time | +-----------+------------+----------+--------------------+-----------------------------+------------+------------+------------+----------+----------+----------+ | 3000 | sbtest | sbuser | 0x16D22096575C5170 | select count(?) from t1 | 1 | 1504257021 | 1504257021 | 29036 | 29036 | 29036 | | 300 | sbtest | sbuser | 0x02033E45904D3DF0 | show databases | 1 | 1504257010 | 1504257010 | 1195 | 1195 | 1195 | | 300 | sbtest | sbuser | 0xE07EF74E5090A618 | show create table t1 | 1 | 1504256708 | 1504256708 | 1135 | 1135 | 1135 | | 300 | sbtest | sbuser | 0x74A739578E179F19 | show processlist | 2 | 1504256702 | 1504257014 | 1219 | 537 | 682 | | 300 | sbtest | sbuser | 0x99531AEFF718C501 | show tables | 2 | 1504256697 | 1504257006 | 4568 | 1223 | 3345 | | 3000 | sbtest | sbuser | 0x3DCE919B79C9576C | select * from t1 where id=? | 8 | 1504248872 | 1504256695 | 17142 | 1267 | 3708 | | 3000 | sbtest | sbuser | 0x3765930C7143F468 | select * from t1 | 3 | 1504248861 | 1504256993 | 6772 | 1701 | 2686 | | 300 | sbtest | sbuser | 0xC67C49B8E6DB18A6 | show tables. | 1 | 1504257003 | 1504257003 | 784 | 784 | 784 | | 300 | sbtest | sbuser | 0x3C44D988579DAFFA | insert into t1 values(?) | 6 | 1504248850 | 1504256999 | 36009 | 4029 | 8445 | +-----------+------------+----------+--------------------+-----------------------------+------------+------------+------------+----------+----------+----------+ 9 rows in set (0.00 sec)
至此,ProxySQL的基本安装和简单配置实现读写分离已经分享完毕,想更深入了解的朋友可以详细参考一下博客:
http://www.cnblogs.com/zhoujinyi/p/6829983.html
http://www.cnblogs.com/zhoujinyi/p/6838685.html
http://seanlook.com/2017/04/10/mysql-proxysql-install-config/
标签:文件 roc lan 注意 负载 cal 写入 lag 表名
原文地址:http://www.cnblogs.com/rayment/p/7464590.html
