标签:osi 存储 i++ 头结点 image 迭代器 属性 oar java集合
Java中LinkedList的部分源码(本文针对1.7的源码)
jdk1.7之后,node节点取代了 entry ,带来的变化是,将1.6中的环形结构优化为了直线型链表结构,从双向循环链表变成了双向链表

在LinkedList中,我们把链子的“环”叫做“节点”,每个节点都是同样的结构。节点与节点之间相连,构成了我们LinkedList的基本数据结构,也是LinkedList的核心。
我们再来看一下LinkedList在jdk1.6和1.7之间结构的区别
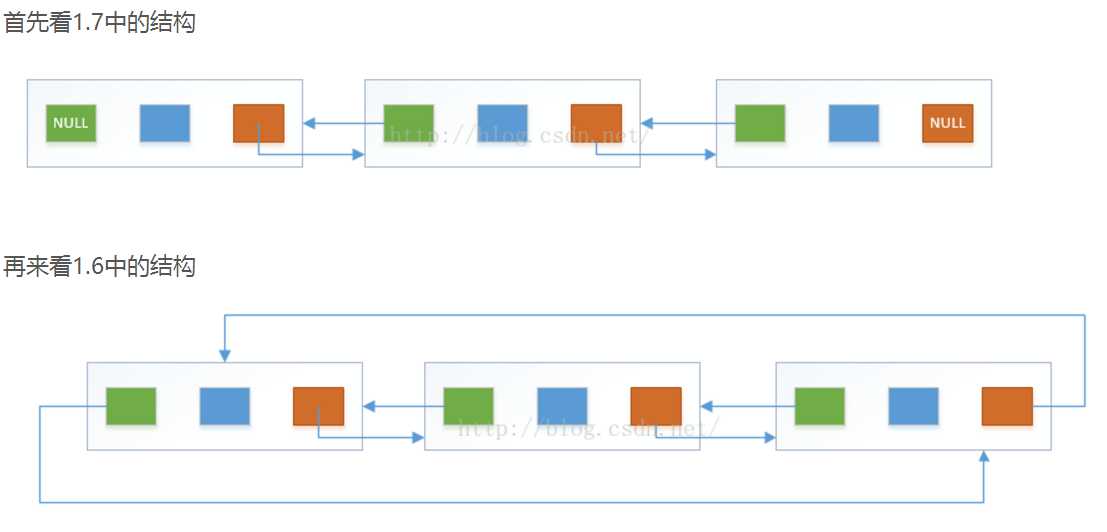
LinkedList包含3个全局参数,size存放当前链表有多少个节点。
first为指向链表的第一个节点的引用
last为指向链表的最后一个节点的引用

LinkedList的构造方法有两个,一个是无参构造,一个是传入Collection对象的构造
1 // 什么都没做,是一个空实现 2 public LinkedList() { 3 } 4 5 public LinkedList(Collection<? extends E> c) { 6 this(); 7 addAll(c); 8 } 9 10 public boolean addAll(Collection<? extends E> c) { 11 return addAll(size, c); 12 } 13 14 public boolean addAll(int index, Collection<? extends E> c) { 15 // 检查传入的索引值是否在合理范围内 16 checkPositionIndex(index); 17 // 将给定的Collection对象转为Object数组 18 Object[] a = c.toArray(); 19 int numNew = a.length; 20 // 数组为空的话,直接返回false 21 if (numNew == 0) 22 return false; 23 // 数组不为空 24 Node<E> pred, succ; 25 if (index == size) { 26 // 构造方法调用的时候,index = size = 0,进入这个条件。 27 succ = null; 28 pred = last; 29 } else { 30 // 链表非空时调用,node方法返回给定索引位置的节点对象 31 succ = node(index); 32 pred = succ.prev; 33 } 34 // 遍历数组,将数组的对象插入到节点中 35 for (Object o : a) { 36 @SuppressWarnings("unchecked") E e = (E) o; 37 Node<E> newNode = new Node<>(pred, e, null); 38 if (pred == null) 39 first = newNode; 40 else 41 pred.next = newNode; 42 pred = newNode; 43 } 44 45 if (succ == null) { 46 last = pred; // 将当前链表最后一个节点赋值给last 47 } else { 48 // 链表非空时,将断开的部分连接上 49 pred.next = succ; 50 succ.prev = pred; 51 } 52 // 记录当前节点个数 53 size += numNew; 54 modCount++; 55 return true; 56 }
注:Node是LinkedList的内部私有类,也是我们的核心节点类
1 private static class Node<E> { 2 E item; 3 Node<E> next; 4 Node<E> prev; 5 6 Node(Node<E> prev, E element, Node<E> next) { 7 this.item = element; 8 this.next = next; 9 this.prev = prev; 10 } 11 }
addFirst/addLast分析
1 public void addFirst(E e) { 2 linkFirst(e); 3 } 4 5 private void linkFirst(E e) { 6 final Node<E> f = first; 7 final Node<E> newNode = new Node<>(null, e, f); // 创建新的节点,新节点的后继指向原来的头节点,即将原头节点向后移一位,新节点代替头结点的位置。 8 first = newNode; 9 if (f == null) 10 last = newNode; 11 else 12 f.prev = newNode; 13 size++; 14 modCount++; 15 }
加入一个新的节点,看方法名就能知道,是在现在的链表的头部加一个节点,既然是头结点,那么头结点的前继必然为null,所以这也是Node<E> newNode = new Node<>(null, e, f);这样写的原因。
之后将first指向了newNode ,指定这个节点以后就就是我们的头结点
之后对原来头节点进行了判断,若在插入元素之前头结点为null,则当前加入的元素就是第一个几点,也就是头结点,所以当前的状况就是:头结点=刚刚加入的节点=尾节点。
若在插入元素之前头结点不为null,则证明之前的链表是有值的,那么我们只需要把新加入的节点的后继指向原来的头结点,而尾节点则没有发生变化。这样一来,原来的头结点就变成了第二个节点了。达到了我们的目的。
addLast方法在实现上是个addFirst是一致的,这里就不在赘述了。有兴趣的朋友可以看看源代码。
其实,LinkedList中add系列的方法都是大同小异的,都是创建新的节点,改变之前的节点的指向关系。仅此而已。
getFirst/getLast方法分析
1 public E getFirst() { 2 final Node<E> f = first; 3 if (f == null) 4 throw new NoSuchElementException(); 5 return f.item; 6 } 7 8 public E getLast() { 9 final Node<E> l = last; 10 if (l == null) 11 throw new NoSuchElementException(); 12 return l.item; 13 }
get方法分析(node方法的调用)
1 public E get(int index) { 2 // 校验给定的索引值是否在合理范围内 3 checkElementIndex(index); 4 return node(index).item; 5 } 6 7 Node<E> node(int index) { 8 if (index < (size >> 1)) { 9 Node<E> x = first; 10 for (int i = 0; i < index; i++) 11 x = x.next; 12 return x; 13 } else { 14 Node<E> x = last; 15 for (int i = size - 1; i > index; i--) 16 x = x.prev; 17 return x; 18 } 19 }
注:关键在于,判断给定的索引值,若索引值大于整个链表长度的一半,则从后往前找,若索引引用值小于整个链表长度的一半,则从前往后找。这样就可以保证,不管链表的长度有多大,搜索的时候最多只搜索链表长度的一半就可以找打,大大提升了效率
removeFirst/removeLast方法分析
1 public E get(int index) { 2 // 校验给定的索引值是否在合理范围内 3 checkElementIndex(index); 4 return node(index).item; 5 } 6 7 Node<E> node(int index) { 8 if (index < (size >> 1)) { 9 Node<E> x = first; 10 for (int i = 0; i < index; i++) 11 x = x.next; 12 return x; 13 } else { 14 Node<E> x = last; 15 for (int i = size - 1; i > index; i--) 16 x = x.prev; 17 return x; 18 } 19 }
摘掉头结点,将原来的第二个节点变为头结点,改变first的指向,若之前仅剩一个节点,移除之后全部置为null
对于LinkList的其他方法,大致上都是包装了以上这几个方法
关于集合的一个小补充:
在ArrayList,LinkedList,HashMap等等的增、删、改方法中,我们总能看到modCount的身影,modCount字面意思就是修改次数,但为什么要记录modCount的修改次数呢?
大家发现一个公共特点没有,所有使用modCount属性的集合全是线程不安全的,这是为什么呢?说明modCount 可能和线程安全有关
阅读源码,发现这玩意只有在本数据结构对应的迭代器中才使用,以HashMap为例:
1 private abstract class HashIterator<E> implements Iterator<E> { 2 Entry<K,V> next; // next entry to return 3 int expectedModCount; // For fast-fail 4 int index; // current slot 5 Entry<K,V> current; // current entry 6 7 HashIterator() { 8 expectedModCount = modCount; 9 if (size > 0) { // advance to first entry 10 Entry[] t = table; 11 while (index < t.length && (next = t[index++]) == null) 12 ; 13 } 14 } 15 16 public final boolean hasNext() { 17 return next != null; 18 } 19 20 final Entry<K,V> nextEntry() { 21 if (modCount != expectedModCount) 22 throw new ConcurrentModificationException(); 23 Entry<K,V> e = next; 24 if (e == null) 25 throw new NoSuchElementException(); 26 27 if ((next = e.next) == null) { 28 Entry[] t = table; 29 while (index < t.length && (next = t[index++]) == null) 30 ; 31 } 32 current = e; 33 return e; 34 } 35 36 public void remove() { 37 if (current == null) 38 throw new IllegalStateException(); 39 if (modCount != expectedModCount) 40 throw new ConcurrentModificationException(); 41 Object k = current.key; 42 current = null; 43 HashMap.this.removeEntryForKey(k); 44 expectedModCount = modCount; 45 } 46 }
由以上代码可以看出,在一个迭代器初始的时候会赋予它调用这个迭代器的对象的mCount,如果在迭代器遍历的过程中,一旦发现这个对象的mcount和迭代器存储的mcount 不一样,那就抛出异常
下面详细解释:
Fail-Fast机制
我们知道java.util.HashMap不是线程安全的,因此如果在使用迭代器的过程中有其他线程修改了map,那么将抛出ConcurrentModificationException,这就是所谓的fail-fast策略。这一策略在源码中的实现是通过 modCount 域,modCount顾名思义就是修改次数,对HashMap内容的修改都将增加这个值,那么在迭代器初始化过程中会将这个值赋给迭代器的expectedModCount。在迭代过程中,判断 modCount跟expectedModCount是否相等,如果不相等就表示,我还在迭代呢,就有其他线程对Map进行了修改,注意到 modCount 声明为 volatile,保证线程之间修改的可见性。
所以在这里和大家建议,当大家遍历那些非线程安全的数据结构时,尽量使用迭代器
标签:osi 存储 i++ 头结点 image 迭代器 属性 oar java集合
原文地址:http://www.cnblogs.com/xuzekun/p/7462477.html