标签:矩阵 取数 类型 模块 其他 shuffle 路径 __init__ 快速
摘要:pandas是一个强大的Python数据分析工具包,pandas的两个主要数据结构Series(一维)和DataFrame(二维)处理了金融,统计,社会中的绝大多数典型用例科学,以及许多工程领域。在Spark中,python程序可以方便修改,省去java和scala等的打包环节,如果需要导出文件,可以将数据转为pandas再保存到csv,excel等。
pandas是一个强大的Python数据分析工具包,是一个提供快速,灵活和表达性数据结构的python包,旨在使“关系”或“标记”数据变得简单直观。它旨在成为在Python中进行实用的真实世界数据分析的基本高级构建块。此外,它的更广泛的目标是成为最强大和最灵活的任何语言的开源数据分析/操作工具。
这里使用pip包管理器安装(python版本为2.7.13)。在windows中,cmd进入python的安装路径下的Scripts目录,执行:
pip install pandas
即可安装pandas,安装完成后提示如下:
说明已成功安装pandas.这里同时安装了numpy等。
pandas非常适合许多不同类型的数据:
这里简单学习Pandas的基础,以命令模式为例,首先需要导入pandas包与numpy包,numpy这里主要使用其nan数据以及生成随机数:
import pandas as pd import numpy as np
4.1 pandas之Series
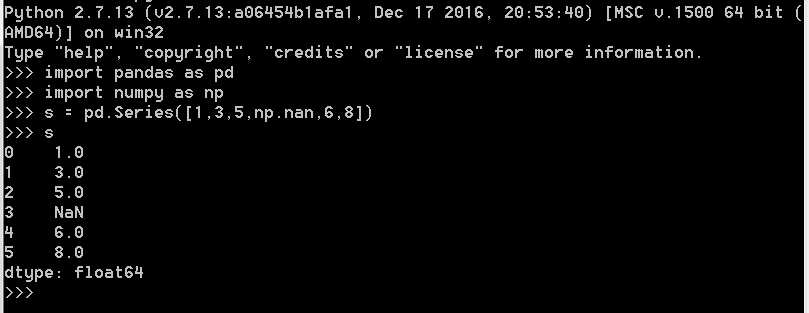
通过传递值列表创建Series,让pandas创建一个默认整数索引:
4.2 pandas之DataFrame
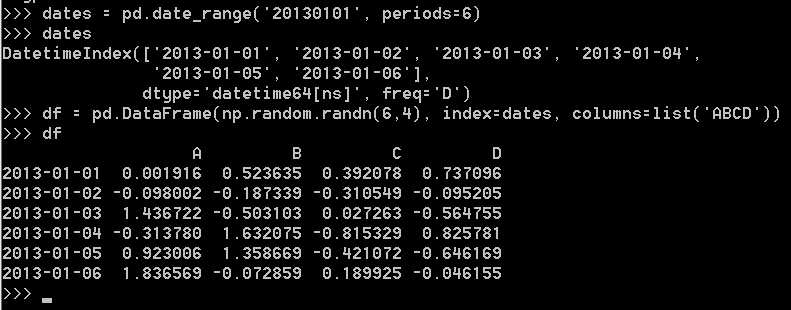
通过传递numpy数组,使用datetime索引和标记的列来创建DataFrame:
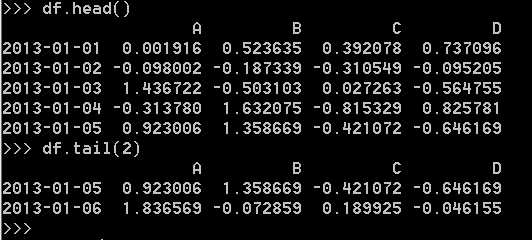
查看DataFrame的头部和尾部数据:
显示索引,列和基础numpy数据:
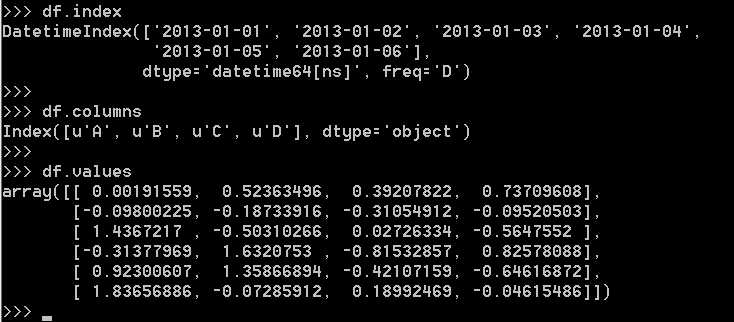
显示数据的快速统计摘要:
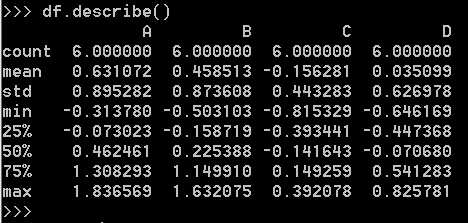
按值排序:
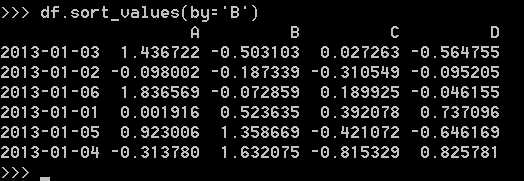
选择单个列,产生Series:
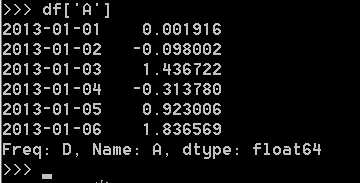
通过[]选择,通过切片选择行:
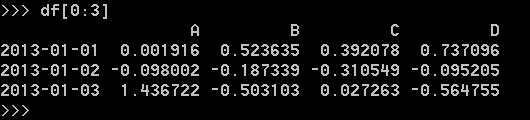
4.2.1 DataFrame读写csv文件
保存DataFrame数据到csv文件:
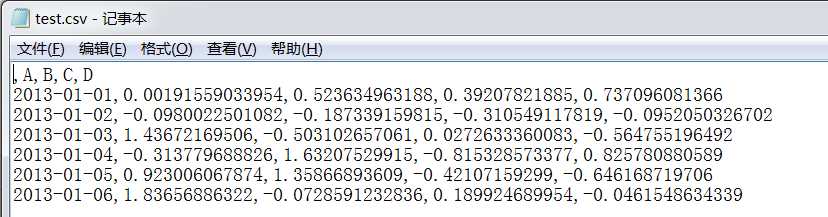
这里保存到c盘下,可以查看文件内容:
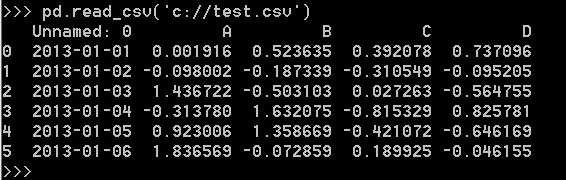
从csv文件读取数据:
4.2.2 DataFrame读写excel文件
保存数据到excel文件:

这里保存到c盘下,可以查看文件内容:
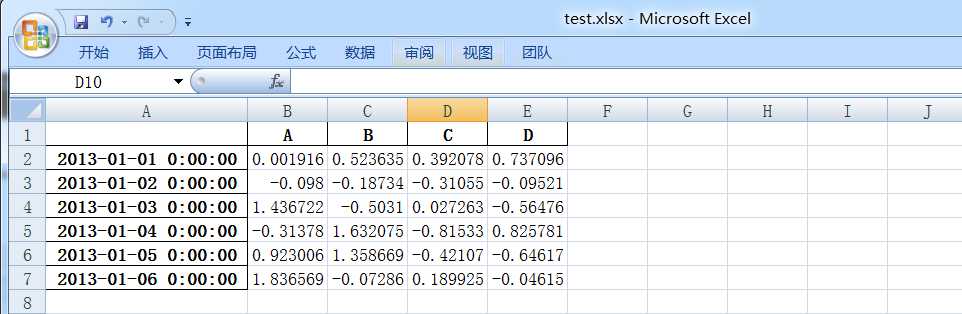
注:此处需要安装openpyxl,同pandas安装相同,pip install openpyxl.
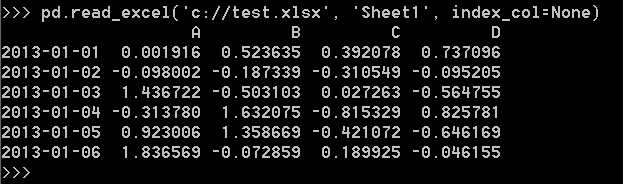
从excel文件读取:
注:因为Excel需要单独的模块支持,所以需要安装xlrd,同pandas安装相同,pip install xlrd.
这里测试读取一个已存在的parquet文件,目录为/data/parquet/20170901/,这里读取该目录下名字为part-r-00000开始的文件。将文件内容中的两列数据读取并保存到文件。代码如下:
#coding=utf-8 import sys from pyspark import SparkContext from pyspark import SparkConf from pyspark.sql import SQLContext class ReadSpark(object): def __init__(self, paramdate): self.parquetroot = ‘/data/parquet/%s‘ # 这里是HDFS路径 self.thedate = paramdate self.conf = SparkConf() self.conf.set("spark.shuffle.memoryFraction", "0.5") self.sc = SparkContext(appName=‘ReadSparkData‘, conf=self.conf) self.sqlContext = SQLContext(self.sc) def getTypeData(self): basepath = self.parquetroot % self.thedate parqFile = self.sqlContext.read.option("mergeSchema", "true").option(‘basePath‘, basepath).parquet( ‘%s/part-r-00000*‘ % (basepath)) resdata = parqFile.select(‘appId‘, ‘os‘) respd = resdata.toPandas() respd.to_csv(‘/data/20170901.csv‘) #这里是Linux系统目录 print("--------------------data count:" + str(resdata.count())) if __name__ == "__main__": reload(sys) sys.setdefaultencoding(‘utf-8‘) rs = ReadSpark(‘20170901‘) rs.getTypeData()
将代码命名为TestSparkPython.py,在集群提交,这里使用的命令为(参数信息与集群环境有关):
spark-submit --master yarn --driver-memory 6g --deploy-mode client --executor-memory 9g --executor-cores 3 --num-executors 50 /data/test/TestSparkPython.py
执行完成后,查看文件前五行内容,head -5 /data/20170901.csv:
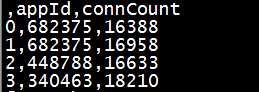
总结:python编写spark程序还是非常方便的,pandas包在数据处理中的优势也很明显。在python越来越火的当下,值得深入学好python,就像python之禅写的那样……
标签:矩阵 取数 类型 模块 其他 shuffle 路径 __init__ 快速
原文地址:http://www.cnblogs.com/wonglu/p/7465064.html