标签:实用 opera map stat ima operator put 工厂 方法
在这之前,我们用过了collect终端操作了,当时主要是用来把Stream中所有的元素结合成一个List。在这里,你会发现collect是一个归约操作,就像reduce一样可以接收各种做法作为参数,将流中的累积成汇总结果。具体的做法是通过定义新的Collector接口来定义的,因此区分Collection、Collector和collect是很重要的。
激动吗?很好,我们先来看一个例利用收集器的例子。想象一下,你有一个Transaction的构成的List,并且想按照货币种类进行分组。在没有Lambda的java里面,哪怕像这种简单的用例实现起来都是非常的啰嗦,就像下面这样。
1 Map<Currency, List<Transaction>> transactionsByCurrencies = new HashMap<>(); 2 List<Transaction> transactions = new ArrayList<>(); 3 for(Transaction t : transactions){ 4 Currency currency = t.getCurrency(); 5 List<Transaction> transactions2 = transactionsByCurrencies.get(currency); 6 if(transactions2 == null){ 7 transactions2 = new ArrayList<>(); 8 transactionsByCurrencies.put(currency, transactions2); 9 } 10 transactions2.add(t); 11 }
如果你是一位经验丰富的Java程序员,写这种东西可能挺顺手的,不过你必须承认,做这么简单的一件事就得写很多代码。更糟糕的是,读起来比写起来更费劲!代码的目的并不容易看出来,尽管换做白活的话是直截了当的:“把列表中的交易按货币分组!”。在这里,你会学到,用Stream中collect方法的一个更通用的Collector参数,你就可以用一句话实现完全相同的结果,而用不着之前使用的toList的特殊情况了:
1 Map<Currency, List<Transaction>> transactionsByCurrencies = transactions.stream().collect(Collectors.groupingBy(Transaction::getCurrency));
这一比差的还真多,对吧?
1.收集器简介
前一个例子清楚地展示了函数式编程相对于指令式编程的一个主要优势:你只需要指出希望的结果--"做什么",而不用操心执行的步骤--“如何做”。在上一个例子中,传递给collect方法的参数是Collector接口的一个实现,也就是给Stream中元素做汇总的方法。之前说的toList只是说"按顺序给每个元素生成一个列表";在这里,groupingBy说的是“生成一个Map”,它的键值是(货币)桶,值则是桶中那些元素的列表。
要是多级分组,指令式和函数式编程之间的区别就会更加明显:由于需要好多层嵌套循环和条件,指令式代码很快就变得更难阅读、更难维护、更难修改。相比之下,函数式版本只要再加上一个收集器就可以轻松地增强功能了。
(1).收集器用作高级归约
刚刚的结论有引出了优秀的函数式API设计的另一个好处:更容易复合和重用。收集器非常有用,因为用它可以简洁而灵活地定义collect用来生成结果集合的标准。更加具体的说,对流调用collect方法将对流中的元素触发一个归约操作(由Collect来参数化)。如图所示,它遍历流中每个元素,并让Collector进行处理。
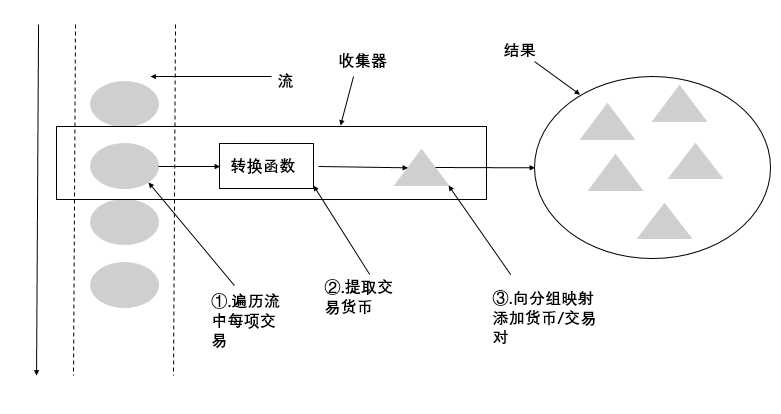
一般来说,Collector会对元素应用一个函数(很多时候是不体现任何效果的恒等变换,例如toList),并将结果累积在一个数据接口中,从而产生这一过程的最终输出。例如,在前面所示的交易分组的例子中,转换函数提取了眉笔交易的货币,随后使用货币作为键,将交易本身累积在生成的Map中。
如货币的例子所示,Collector接口中方法的实现决定了如何对流执行归约操作。我们会之后研究如何创建自定义收集器。但是Collectors实用类提供了很多静态方法,可以方便地常见收集器的实例,只要拿来用就可以了。最直接和最常用的收集器是toList静态方法,它会把流中的所有元素收集到一个List中:
1 List<Transaction> transactions = transactionStream.collect(Collectors.toList());
(2),预定义收集器
接下来,我们主要探讨预定义收集器的功能,也就是可以从Collectors类提供的工厂方法(groupingBy)创建的收集器。它们主要提供了三大功能:
A.将流元素归约和汇总为一个值
B.元素分组
C.元素分区
我们先来看看可以进行归约和汇总的收集器。它们在很多场合下都很方便,比如前面的例子中提到的求一系列交易的总交易额。
然后你将看到如何对流中的元素进行分组,同时把前一个例子推广到多层次分组,或把不同点的收集器结合起来,对每个子组进一步归约操作。我们还将谈到分组的特殊情况“分区”,即使用谓词(返回一个boolean值的单参数函数)作为分组函数。
2.归约和汇总
为了说明从Collectors工厂类中能够创建出来多少种收集器实例,我们重用一下前一章的例子:包含一张佳肴列表!
就像你刚刚看到的,在需要将流项目重组成集合时,一般会使用收集器(Stream方法collect的参数)。再宽泛一点来说,但凡要把流中所有的项目合并成一个结果就可以用。这个结果可以是任何类型,可以复杂如代表一棵树的多级映射,或是简单如一个整数--也许代表了菜单的热量总和。这两种结果类型我们都会讨论。
我们先来一个简单的例子,利用counting工厂方法返回的收集器,数一数菜单里面有多少种菜。
1 long howManyDishes = menu.stream().collect(Collectors.counting());
这还可以写的更加直接:
1 long howManyDishes = menu.stream().count();
counting收集器在和其他收集器联合使用的时候特别有用,后面会谈到这一点。在以后的内容中,我们假定你已经导入了Collectors类的所有静态工厂方法:
import static java.util.stream.Collectors.*;
这样你就不用写counting()而用不着Collectors.counting()之类的了。
让我们来继续探讨简单的预定义收集器,看看如何找到流中的最大值和最小值。
(1).查找流中的最小值和最大值
假设你想要找出菜单中热量最高的菜。你可以使用两个收集器,Collectors.maxBy和Collectors.minBy,来计算流中的最大或者最小值。这两个收集器接收一个Comparator参数来比较流中的元素。你可以创建一个COmparator来根据对菜肴进行比较,并把它传递给Collectors.maxBy:
1 Comparator<Dish> dishCaloriesComparator = Comparator.comparing(Dish::getCalories); 2 Optional<Dish> mostCalorieDish = 3 menu.stream() 4 .collect(maxBy(dishCaloriesComparator));
你可能会在想Optional<Dish>是怎么回事。要回答这个问题,我们需要问:“要是menu为空怎么办”。那就没有要返回的菜了!JAVA 8引入了Optional,他是一个容器,可以包含也可以不含值。这里它完美地代表了可能也不可能返回菜肴的情况。之前,我们说过findAny方法的时候简要的提到过它。
另一个常见的返回单个值归约操作是对流中对象的一个数字字段求和,或者你可能想要求平均数。这种操作称为汇总操作。我们来看看 如何使用收集器来表达汇总操作。
(2).汇总
Collectors类专门为汇总提供了一个工厂方法:Collectors.summingInt。它可以接收一个把对象映射到和所需int的函数,并且返回一个收集器;该收集器在传递给普通的collect方法后即执行我们需要的汇总操作。举个例子来说,你可以这样求出菜单列表的总热量。
1 int tltalCalories = menu.stream().collect(summingInt(Dish::getCalories));
这里的收集过程如图所示。在遍历流时,会把每一单才都映射为其热量,然后把这个数字累加到累加器(这里的初始值是0)。
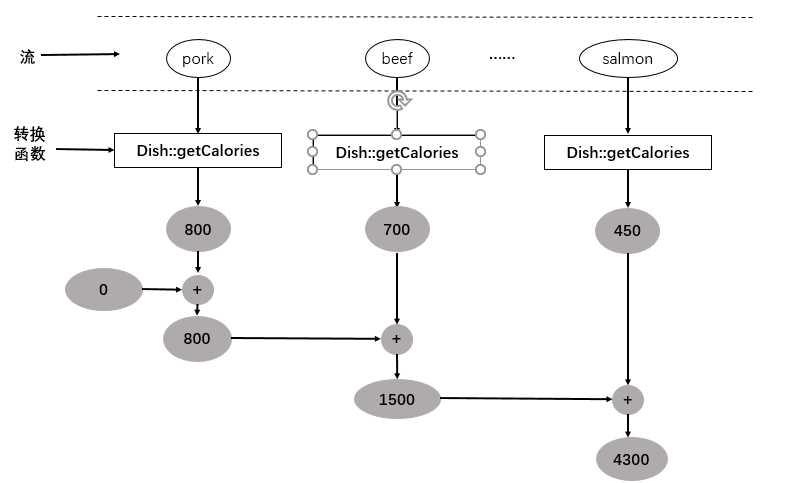
Collectors.summingLong和Collectors.summingDouble方法的作用完全一样,可以用于求和字段为long或者double的情况。
但是汇总不仅仅是求和;还有Collectors.averagingInt,连同对应的averagingLong和averagingDouble可以计算数值的平均数:
1 double tltalCalories = menu.stream().collect(averagingInt(Dish::getCalories));
到目前为止,你已经看到了如何使用收集器来给流中的元素计数,找到这些元素数值属性的最大值和最小值,以及计算其总和和平均值。不过很多时候,你可能想要得到两个或者更多这样的结果,而且你希望只需要一次操作就可以完成。在这种情况下,你可以使用summarizingInt工厂返回的收集器。例如,通过一次summarizing操作你可以就算数出菜单中元素的个数,并得到菜肴热量总和、平均值、最大值和最小值。
1 IntSummaryStatistics menuStatistics = 2 menu.stream().collect(summarizingInt(Dish::getCalories));
这个收集器会把所有这些信息收集到一个叫做IntSummryStatistics的类里面,它提供了方便的取值方法(getter)来访问结果。打印menuStatistic对象会得到以下输出:
1 IntSummaryStatistics{count=9, sum=4200, min=120, average=466.666667, max=800}
(3).连接字符串
joining工厂方法返回的收集器会把对流中每一个对象应用toString方法得到的所有字符串拼接成一个字符串。这意味着你把菜单中所有菜肴的名称拼接起来,如下所示:
1 String shortMenu = menu.stream().map(Dish::getName).collect(joining());
请注意,joining在内部使用了StringBuilder来把生成的字符串逐个追加起来。打印结果:
1 porkbeefchickenfrench friesriceseason fruitpizzaprawnssalmon
但是字符串的可读性不是很好。幸好,joining工厂方法有一个重载版本可以接收元素之间的分解符,这样你就可以得到逗号分隔菜肴名称列表:
1 String shortMenu = menu.stream().map(Dish::getName).collect(joining(", "));
正如我们预期的那样,它会生成:
1 pork, beef, chicken, french fries, rice, season fruit, pizza, prawns, salmon
到目前为止,我们已经探讨了各种将流归约到一个值的收集器。接下来,我们会展示为什么所有这种形式的归约过程,其实都是Collectors.reduce工厂方法提供得更加广义归约收集器的特殊情况。
(4).广义的归约汇总
事实上,我们已经讨论的所有收集器,都是一个可以用reducing工厂方法定义的归约过程的特殊情况而已。Collectors.redcuing工厂方法都是所有这些特殊情况的一般化。可以说,先前讨论的案例仅仅是为了方便程序员而已。(但是,请记得方便程序员和可读性是头等大事!)例如,可以用reducing方法创建的收集器来计算你菜单的总热量,如下所示:
1 int totalCalories = 2 menu.stream() 3 .collect(reducing(0, Dish::getCalories, (i, j) -> i + j));
它需要三个参数:
A.第一个参数是归约操作的起始值,也是流中没有元素时的返回值,所以很显然对于数值而言,0是一个合适的值。
B.第二个参数就是你在之前使用的函数--Function对象,将菜肴转换成一个表示其所含热量的int。
C.第三个参数是一个BinaryOperator,将两个项目累积成同一个类型的值。这里它就是对两个int求和。
同样,你可以使用下面这样单参数形式的reducing来找到热量最高的菜,如下所示:
1 Optional<Dish> mostCaloriesDish = menu.stream() 2 .collect(reducing((d1, d2) -> d1.getCalories() > d2.getCalories() ? d1 : d2));
你可以把单参数reducing工厂方法创建的收集器看作三参数方法的特殊情况,它把流中的第一个项目作为起点,把恒等函数(即一个函数仅仅是返回其输入参数)作为一个转换函数。它也意味着,要是把参数收集器传递给空流的collect方法,收集器就没有起点。
收集和归约:
到目前为止,我们谈论了很多有关归约的内容。你可能想知道,Stream接口的collect和reduce方法有何不同,因为两种方法通常会获得相同的结果。例如,你可以像下面这样使用reduce方法来实现toListCollector所做的工作:
1 Stream<Integer> stream = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8).stream(); 2 List<Integer> numbers = stream.reduce(new ArrayList<Integer>(), (List<Integer> l, Integer i) -> { 3 l.add(i); 4 return l; 5 }, (List<Integer> l1, List<Integer> l2) -> { 6 l1.addAll(l2); 7 return l1; 8 });
A.收集框架的灵活性:以不同的方法执行同样的操作
你还可以进一步简化前面reducing收集器的求和例子--引用Integer类的sum方法,而不用写一个表达同一操作的Lambda表达式。这会得到一下程序:
1 int totalCarories = menu.stream().collect(reducing(0, Dish::getCalories, Integer::sum));
标签:实用 opera map stat ima operator put 工厂 方法
原文地址:http://www.cnblogs.com/Stay-Hungry-Stay-Foolish/p/7466526.html