标签:等于 uri 计算 fonts 利用 bsp 最大 ida 样本
决策树的定义
决策树(decision tree)是一个树结构(可以是二叉树或非二叉树)。其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。
树是由节点和边两种元素组成的结构。理解树,就需要理解几个关键词:根节点、父节点、子节点和叶子节点。
父节点和子节点是相对的,说白了子节点由父节点根据某一规则分裂而来,然后子节点作为新的父亲节点继续分裂,直至不能分裂为止。
而根节点是没有父节点的节点,即初始分裂节点,叶子节点是没有子节点的节点,如下图所示:
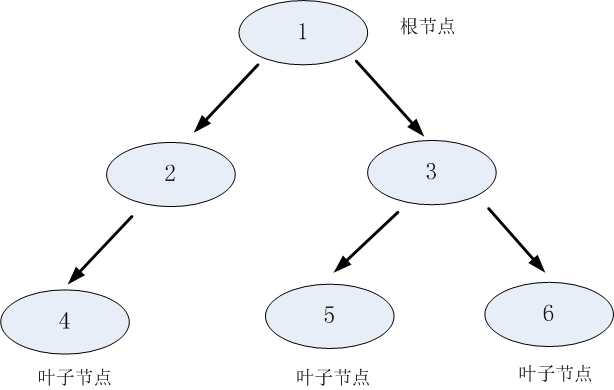
决策树利用如上图所示的树结构进行决策,每一个非叶子节点是一个判断条件,每一个叶子节点是结论。从跟节点开始,经过多次判断得出结论。
决策树如何做决策
案例:预测?明今天出不出门打球
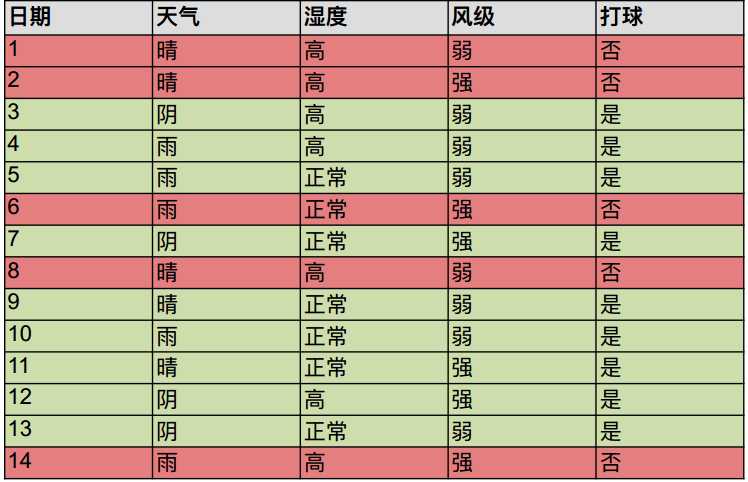
步骤1:将所有的数据看成是一个节点,进入步骤2;
步骤2:从所有的数据特征中挑选一个数据特征对节点进行分割,进入步骤3;
步骤3:生成若干孩子节点,对每一个孩子节点进行判断,如果满足停止分裂的条件,进入步骤4;否则,进入步骤2;
步骤4:设置该节点是子节点,其输出的结果为该节点数量占比最大的类别。
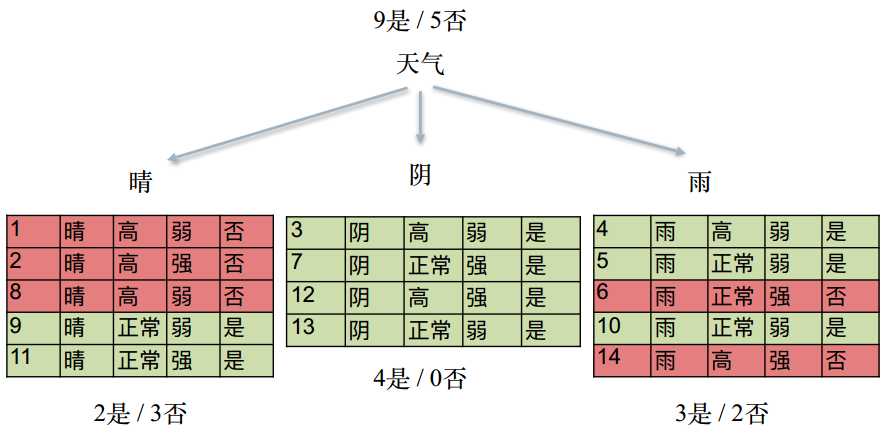
数据分割
分裂属性的数据类型分为离散型和连续性两种情况。
对于离散型的数据,按照属性值进行分裂,每个属性值对应一个分裂节点;
对于连续性属性,一般性的做法是对数据按照该属性进行排序,再将数据分成若干区间,如[0,10]、[10,20]、[20,30]…,一个区间对应一个节点,若数据的属性值落入某一区间则该数据就属于其对应的节点。
分裂属性的选择
决策树采用贪婪思想进行分裂,即选择可以得到最优分裂结果的属性进行分裂。
需要一个衡量Purity(纯洁度) 的 标准(metrics),这个标准需要是对称性的 ( 4是/0否 = 0是/4否 )
a)熵
熵描述了数据的混乱程度,熵越大,混乱程度越高,也就是纯度越低;反之,熵越小,混乱程度越低,纯度越高。
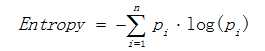 其中Pi 表示类i的数量占比。
其中Pi 表示类i的数量占比。
以二分类问题为例,如果两类的数量相同,此时分类节点的纯度最低,熵 等于1;如果节点的数据属于同一类时,此时节点的纯度最高,熵 等于0。
栗子:
H(S) = - P(是)logP(是) - P(否)logP(否)
计算3是/3否:H(S) = - 3/6log3/6 - 3/6logP3/6 = 1
计算4是/0否:H(S) = - 4/4log4/4 - 0/4logP0/4 = 0
b)信息增益
用信息增益表示分裂前后的数据复杂度和分裂节点数据复杂度的变化值,计算公式表示为:
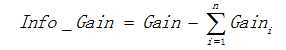
其中Gain表示节点的复杂度,Gain越高,说明复杂度越高。
信息增益就是分裂前的数据复杂度 减去 孩子节点的数据复杂度的和,信息增益越大,分裂后的复杂度减小得越多,分类的效果越明显。
常见算法
决策树的构建算法主要有ID3、C4.5、CART三种,其中ID3和C4.5是分类树,CART是分类回归树
ID3算法:
1)对当前样本集合,计算所有属性的信息增益;
2)选择信息增益最?的属性作为测试属性,把测试属性取值相同的样本划为同?个?样本集;
3)若?样本集的类别属性只含有单个属性,则分?为叶?节点,判断其属性值并标上相应的符号,然后返回调?处;否则对?样本集递归调?本算法。
过渡拟合(overfitting)
采用上面算法生成的决策树在事件中往往会导致过滤拟合。也就是该决策树对训练数据可以得到很低的错误率,但是运用到测试数据上却得到非常高的错误率。过渡拟合的原因有以下几点:
噪音数据:训练数据中存在噪音数据,决策树的某些节点有噪音数据作为分割标准,导致决策树无法代表真实数据。
缺少代表性数据:训练数据没有包含所有具有代表性的数据,如在日期这个条件下做分裂,导致某一类数据无法很好的匹配,这一点可以通过观察混淆矩阵(Confusion Matrix)分析得出。
多重比较:永远可以把N个数据分成100%纯洁的N组
优化方案:
1、减少不必要的分裂,规定分裂条件得到结果的随机性百分比,超过一定比例才作为分列条件
2、减枝Prune(根据ValidationSet 验证集)
如果数据集为14条,采用10条作为训练数据,4条为验证集,当决策树组合后,人为减少枝,使用验证集能否分出pure分裂,判断枝是否多余。
C4.5算法
ID3算法存在一个问题,就是偏向于多值属性。
例如,如果存在唯一标识属性ID,则ID3会选择它作为分裂属性,这样虽然使得划分充分纯净,但这种划分对分类几乎毫无用处。
ID3的后继算法C4.5使用增益率(Gain Ratio)的信息增益扩充,试图克服这个偏倚。
其中各符号意义与ID3算法相同,然后,增益率被定义为:
C4.5选择具有最大增益率的属性作为分裂属性,其具体应用与ID3类似,不再赘述。
标签:等于 uri 计算 fonts 利用 bsp 最大 ida 样本
原文地址:http://www.cnblogs.com/5poi/p/7471295.html