标签:写入文件 分析 特殊 集合 纽约 大于 读取 读取excel 作用
股票:
股票的面值与市值
上市/IPO:
股票的作用:
股票的分类
股票按业绩分类:
股票按上市地区分类:
股票市场的构成
交易所
影响股价的因素
股票买卖(A股)
金融分析
基本面分析
技术面分析:各项技术指标
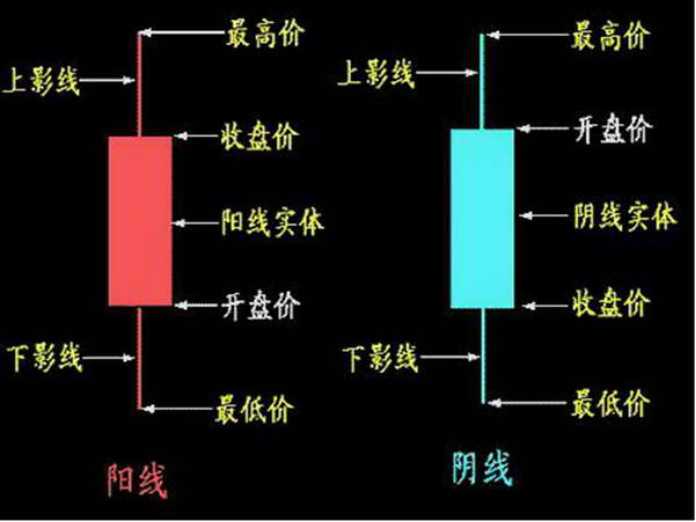
K线
金融量化投资
量化策略
量化投资与Python
Ipython:交互式的Python命令行
Ipython常用的魔术命令


Python调试器命令


Ipython快捷键

NumPy:数组计算
NumPy:ndarray-多维数组对象
NumPy:ndarray-多维数组对象
NumPy:索引和切片
NumPy:布尔型索引
NumPy:花式索引*
NumPy:通用函数
NumPy:数学和统计方法
NumPy:随机数生成
pandas:数据分析
pandas:Series
pandas:Series特性
pandas:整数索引
pandas:Series数据对齐
pandas:Series缺失数据
pandas:DataFrame
pandas:DataFrame查看数据
pandas:DataFrame索引和切片
pandas:DataFrame数据对齐与缺失数据
pandas:其他常用方法
*pandas:层次化索引
pandas:时间对象处理
pandas:时间序列
pandas:从文件读取
pandas:写入到文件
Matplotlib:绘图和可视化
Matplotlib:plot函数
*Matplotlib:画布与图
标签:写入文件 分析 特殊 集合 纽约 大于 读取 读取excel 作用
原文地址:http://www.cnblogs.com/liyongsan/p/7472697.html