标签:整数 浮点 就会 标准 names 一个 pytho name 切片
Numpy是高性能科学计算和数据分析的基础包。功能如下:
numpy本身并没有提供多么高级的数据分析功能,理解numpy数组以及面向数组的计算将有助于更加高效地使用诸如pandas之类的工具
关注的功能集中在:
1、Numpy的ndarray
一种多维数组对象
Numpy最重要的一个特点就是其N维数据对象,该对象是一个快速而灵活的大数据集容器。
数组创建函数
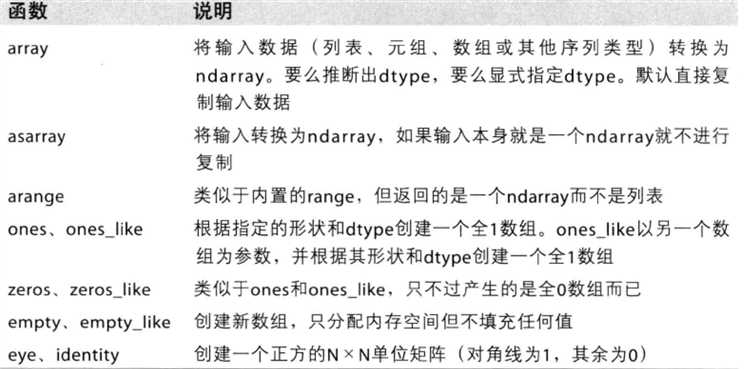
注意:
#代码测试
import numpy as np data = [6, 7.5, 8, 0, 1] arr1 = np.array(data) arr1 arr1.dtype
输出结果
arr1 Out[8]: array([ 6. , 7.5, 8. , 0. , 1. ]) arr1.dtype Out[9]: dtype(‘float64‘)
2、ndarray的数据类型
dtype是一个特殊的对象,它含有ndarray将一块内存解释为特定数据类型所需的信息
arr1 = np.array([1,2,3],dtype = np.float64) arr2 = np.array([1,2,3],dtype = np.int32) arr1.dtype,arr2.dtype
Out[15]: (dtype(‘float64‘), dtype(‘int32‘)
dytpe是numpy如此强大和灵活的原因之一。多数情况下,它们直接映射到相应的机器表示,这使得“读写磁盘上的二进制数据流”以及“集成低级语言代码”(如C)等工作变得更加简单
数据型dtype的命名方式相同:一个类别名(如float或int),后面跟一个用于表示各元素位长的数字。
注意:不用全部记住,通过只需要知道你所处理的数据的大致类型是浮点数、复数、整数、布尔值、字符串,还是普通的python对象即可。
NumPy的数据类型


特别注意object为python的普通对象类型,不同类型的的定义可能会导致计算错误
你可以通过ndarray的astype方法显式地转换其dtype:
arr = np.array([1,2,3,4,5]) arr.dtype float_arr = arr.astype(np.float64) float_arr.dtype
dtype(‘float64‘)
#整数被转换成了浮点数,如果将浮点数转换成整数,则小数部分将会被截断
arr = np.array([1.1,2.3,3.5,-4.7,5.8])
arr.dtype, arr.astype(np.int32)
Out[22]: (dtype(‘float64‘), array([ 1, 2, 3, -4, 5]))
如果某字符串数组表示的全是数字,也可以用astype将其转换为数值形式,这里不再演示
如果某个不能转换为float64的字符串,就会引发一个TypeError。
数组的dtype还有另外一个用法:
int_array = np.arange(10) calibers = np.array([.22, .270, .357, .380, .44, .50], dtype = np.float64) int_array.astype(calibers.dtype) Out[34]: array([ 0., 1., 2., 3., 4., 5., 6., 7., 8., 9.])
#这里直接调用calibers 的数据类型
注意:调用astype无论如何都会创建出一个新的数组(原始数组的拷贝),即使新dtype跟老dtype相同也是如此
另外:注意,浮点数(float64或float32)只能表示近似的分数值。在复杂计算中,由于可能会积累一些浮点错误,因此比较操作只能在一定小数位以内有效
3、数组和标量之间的运算
数组很重要,因为它使你不用编写循环即可对数据执行批量运算。这通常就叫做矢量化vectorization。大小相等的数组之间的任何算术运算都 会将运算应用到元素级:
arr = np.array([[1., 2., 3.], [4., 5., 6.]]) arr Out[37]: array([[ 1., 2., 3.], [ 4., 5., 6.]])
不同大小的数组之间的运算叫做广播(broadcasting),如
1/arr arr * arr arr - arr arr * 0.5
4、基本的索引与切片
numpy 数组的索引主题是内容非常丰富,因为选取数据子集或单个元素的方式有限多
示例,一维数组很简单
arr = np.arange(10) arr Out[38]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) arr[5] Out[39]: 5 arr[5:8] Out[40]: array([5, 6, 7]) arr[5:8] =12 arr Out[42]: array([ 0, 1, 2, 3, 4, 12, 12, 12, 8, 9])
当你将一个标题值赋值给一个切片时,该值会自动传播到整个选区
跟列表最重要的区别在于,数组切片是原始数组的视图。这意味着数据不会被复制,视图上的任何修改都会直播反映到源数组上:
警告(特别注意):如果你想要得到的是ndarray切片的一份副本而非视图,就需要显式地进行复制操作,例如arr[5:8].copy()
对于高维度数组,能做的事情更多。在一个二级数组中,各索引位置上的元素不再是标量而是一维数组:
arr3d = np.array([[[1, 2, 3], [4, 5, 6]],[[7, 8, 9], [10, 11, 12]]]) arr3d arr3d[0] old_values = arr3d[0].copy() arr3d[0] = 42 arr3d arr3d[0] = old_values arr3d
注意,在上面所有这些选取数组子集的例子中,返回的数组都是视图
(1)切片索引:
ndarray的切片语法跟python列表这样的一维对象差不多:
切片是沿着第0轴(即第一个轴)切片的,也就是说,切片是沿着一个轴向选取元素的。
arr2d = np.array([[1, 2, 3], [4, 5, 6],[7, 8, 9]]) arr2d Out[54]: array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) arr2d[:2, 1:] Out[55]: array([[2, 3], [5, 6]]) arr2d[:2] Out[56]: array([[1, 2, 3], [4, 5, 6]]) arr2d[1:] Out[57]: array([[4, 5, 6], [7, 8, 9]])
注意:“只有冒号”表示选取整个轴
arr2d[1, :2],arr2d[2, :1]
Out[58]: (array([4, 5]), array([7]))
arr2d[:, :1] Out[59]: array([[1], [4], [7]])
对切片表达式的赋值操作也会被扩散到整个选区
arr2d[:2, 1:] = 0 arr2d Out[61]: array([[1, 0, 0], [4, 0, 0], [7, 8, 9]])
下面示意图非常好,比较直观,看一看,方便理解
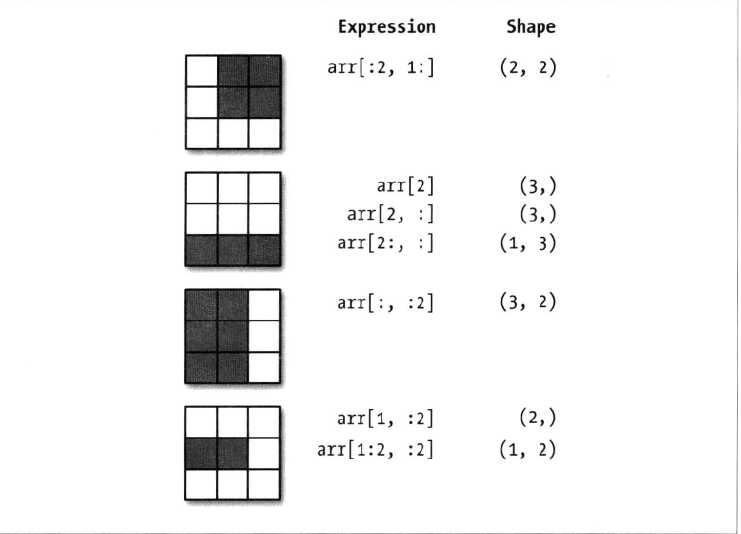
(2)布尔型索引:
将使用numpy.random中的randn函数生成一些正态分布的随机数据
from numpy import random names = np.array([‘Bob‘, ‘Joe‘, ‘Will‘, ‘Bob‘, ‘Will‘, ‘Joe‘, ‘Joe‘]) data =random.randn(7, 4) names Out[66]: array([‘Bob‘, ‘Joe‘, ‘Will‘, ‘Bob‘, ‘Will‘, ‘Joe‘, ‘Joe‘], dtype=‘<U4‘) data Out[67]: array([[ 1.78685856, -0.67304512, 0.32355692, -1.83041628], [ 0.55780668, 1.33059472, 0.35288959, 0.21261696], [ 0.40565134, -0.44896943, -0.05346766, 1.14335673], [ 0.09889879, 1.96735612, -0.5174042 , 1.330155 ], [-0.46393905, -0.55061404, 0.32650597, 0.5289268 ], [-1.72569259, -0.75332871, 0.66816964, -0.54942557], [ 1.26826507, -0.54054629, 0.27376279, -1.1878763 ]])
跟算法运算一样,数组的比较运算(如==)也是矢量化的。
因此,对names和字符串‘Bob’的比较运算将会产生一个布尔型数组:
names == ‘Bob‘ Out[68]: array([ True, False, False, True, False, False, False], dtype=bool)
这个布尔型数组可用于数组索引:
names == ‘Bob‘ Out[68]: array([ True, False, False, True, False, False, False], dtype=bool) data[names == ‘Bob‘] Out[69]: array([[ 1.78685856, -0.67304512, 0.32355692, -1.83041628], [ 0.09889879, 1.96735612, -0.5174042 , 1.330155 ]])
布尔型数组的长度必须跟被索引的轴长度一致。
data[names == ‘Bob‘, 2:] Out[70]: array([[ 0.32355692, -1.83041628], [-0.5174042 , 1.330155 ]])
data[names == ‘Bob‘, 3]
Out[71]: array([-1.83041628, 1.330155 ])
要选择除‘Bob’以外的其他值,既可以使用不等于符号(!=),也可以通过负号(-)
对条件进行否定:
names != ‘Bob‘, Out[77]: (array([False, True, True, False, True, True, True], dtype=bool),) data[~(names == ‘Bob‘)] Out[78]: array([[ 0.55780668, 1.33059472, 0.35288959, 0.21261696], [ 0.40565134, -0.44896943, -0.05346766, 1.14335673], [-0.46393905, -0.55061404, 0.32650597, 0.5289268 ], [-1.72569259, -0.75332871, 0.66816964, -0.54942557], [ 1.26826507, -0.54054629, 0.27376279, -1.1878763 ]])
选择这三个名字中的两个需要组合应用多个布尔条件,使用& | 之类的布尔算术运算符即可
mask = (names == ‘Bob‘) | (names == ‘Will‘) mask Out[79]: array([ True, False, True, True, True, False, False], dtype=bool)
通过布尔型索引选取数组中的数据,将总是创建数据的副本,即使返回一模一样的数组也是如此
注意:python关键字and 和 or 在布尔型数组中无效
通过布尔型数组设置值是一种经常用到的手段。
为了将data 中的所有负值都设置为0,只需
data[data < 0] = 0 data Out[82]: array([[ 1.78685856, 0. , 0.32355692, 0. ], [ 0.55780668, 1.33059472, 0.35288959, 0.21261696], [ 0.40565134, 0. , 0. , 1.14335673], [ 0.09889879, 1.96735612, 0. , 1.330155 ], [ 0. , 0. , 0.32650597, 0.5289268 ], [ 0. , 0. , 0.66816964, 0. ], [ 1.26826507, 0. , 0.27376279, 0. ]])
(3)花式索引:
花式索引(Fancy indexing)是一个numpy术语,它指的是利用整数数组进行索引
arr = np.empty((8,4)) for i in range(8): arr[i] = i arr Out[85]: array([[ 0., 0., 0., 0.], [ 1., 1., 1., 1.], [ 2., 2., 2., 2.], [ 3., 3., 3., 3.], [ 4., 4., 4., 4.], [ 5., 5., 5., 5.], [ 6., 6., 6., 6.], [ 7., 7., 7., 7.]])
为了以特定顺序选取行子集,只需传入一个用于指定顺序的整数列表或ndarray即可:
arr[[4, 3, 0, 6]] Out[86]: array([[ 4., 4., 4., 4.], [ 3., 3., 3., 3.], [ 0., 0., 0., 0.], [ 6., 6., 6., 6.]])
使用负数索引将会从末尾开始选取行:
arr[[-3, -5, -7]] Out[87]: array([[ 5., 5., 5., 5.], [ 3., 3., 3., 3.], [ 1., 1., 1., 1.]])
#一次传入多个索引数组会有一点特别。它返回的是一个数组,其中的元素对应各个索引元组:
arr = np.arange(32).reshape((8, 4)) arr Out[89]: array([[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11], [12, 13, 14, 15], [16, 17, 18, 19], [20, 21, 22, 23], [24, 25, 26, 27], [28, 29, 30, 31]]) arr[[1, 5, 7, 2], [0, 3, 1, 2]] Out[90]: array([ 4, 23, 29, 10])
#最终选取的元素(1,0),(5,3),(7,1),(2,2),这花式索引的行为跟预期不一样
arr[[1, 5, 7, 2]][:, [0, 3, 1, 2]]
Out[91]:
array([[ 4, 7, 5, 6],
[20, 23, 21, 22],
[28, 31, 29, 30],
[ 8, 11, 9, 10]])
#另一个办法是使用np.ix_函数,它可以将两个一维整数数组转换为一个用于选取方形区域的索引器
arr[np.ix_([1, 5, 7, 2], [0, 3, 1, 2])]
Out[92]:
array([[ 4, 7, 5, 6],
[20, 23, 21, 22],
[28, 31, 29, 30],
[ 8, 11, 9, 10]])
记住,花式索引跟切片不一样,它总是将数据复制到新数组中
(4)数组转置和轴对换
转置是重塑的一种特殊形式,它返回的是源数据的视图(不会进行任何复制操作)。数组不仅有transpose方法,还有一个特殊的T属性
arr = np.arange(15).reshape((3, 5)) arr Out[94]: array([[ 0, 1, 2, 3, 4], [ 5, 6, 7, 8, 9], [10, 11, 12, 13, 14]]) arr.T Out[95]: array([[ 0, 5, 10], [ 1, 6, 11], [ 2, 7, 12], [ 3, 8, 13], [ 4, 9, 14]])
在进行矩阵计算时,经常需要用到该操作,比如利用np.dot计算矩阵内积XTX:
arr = np.random.randn(6, 3) np.dot(arr.T, arr) Out[97]: array([[ 6.11959567, 4.05155542, -1.57177392], [ 4.05155542, 4.35617388, -1.7878248 ], [-1.57177392, -1.7878248 , 4.4350867 ]])
对于高维数组,转置需要得到一个由编号组成的元组才能对这些轴进行转置
arr = np.arange(16).reshape((2, 2, 4)) arr Out[99]: array([[[ 0, 1, 2, 3], [ 4, 5, 6, 7]], [[ 8, 9, 10, 11], [12, 13, 14, 15]]]) arr.transpose((1, 0, 2)) Out[100]: array([[[ 0, 1, 2, 3], [ 8, 9, 10, 11]], [[ 4, 5, 6, 7], [12, 13, 14, 15]]])
简单的转置可以使用.T,它其实就是进行轴对换而已。ndarray还有一个swapaxes方法, 它需要接受一对轴编号
arr = np.arange(16).reshape((2, 2, 4)) arr Out[107]: array([[[ 0, 1, 2, 3], [ 4, 5, 6, 7]], [[ 8, 9, 10, 11], [12, 13, 14, 15]]]) arr.swapaxes(1, 2) Out[108]: array([[[ 0, 4], [ 1, 5], [ 2, 6], [ 3, 7]], [[ 8, 12], [ 9, 13], [10, 14], [11, 15]]])
swapaxes也是返回源数据的视图(不会进行任何复制操作)
标签:整数 浮点 就会 标准 names 一个 pytho name 切片
原文地址:http://www.cnblogs.com/yizhenfeng/p/7475957.html