标签:boot error: 不用 将不 example type 3.2 pre 过程
保存和提取python运算完的结果
首先import pickle模块
定义一个字典:
a_dict={‘da‘:111,2:[23,1,4],‘23‘:{1:2,‘d‘:‘sad‘}}
首先打开一个file,后缀名用pickle代替即可,以二进制形式打开
接着用dump,把a_dict放入到file中,并关闭文件
pickle.dump(a_dict,file)
file.close()
接着读取我们存储的文件
首先打开文件,打开方式为‘rb’,使用pickle的load下载内容,最后关闭文件
file=open(‘pickle_example.pickle‘,‘rb‘)
a_dict1=pickle.load(file)
file.close()
print(a_dict1)
运行结果如下所示:
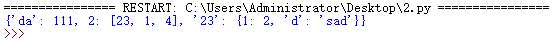
上述过程可简化,使用with语句,不用考虑到关闭文件,只要运行完会自动将文件关闭
with open(‘pickle_example.pickle‘,‘rb‘)as file:
a_dict1=pickle.load(file)
print(a_dict1)
写入也可以用with语句简化
使用set可以去除对象中的重复元素
char_list=[‘a‘,‘b‘,‘c‘,‘c‘,‘d‘,‘d‘,‘d‘]
print(set(char_list))
运行结果如下所示:
返回的是一个类似于字典的内容,但不是字典,字典有key和value,但是该内容只有value
使用type来输出类型:
print(type(set(char_list)))
print(type({1:2}))
结果如下所示:

定义一个句子,set同样能去掉重复的内容:
sentence=‘Welcome Back to This Tutorial‘
print(set(sentence))
运行结果如下所示:
set区分大小写、空格
能否直接比较char_list和sentence的不同?
print(set([sentence,char_list]))
运行报错,不能在set中传入list,出现错误:TypeError: unhashable type: ‘list‘
可以通过add增加内容,如果set中已有的内容则不重复添加
unique_char=set(char_list)
unique_char.add(‘x‘)
print(unique_char)
运行结果如下,增加了‘x’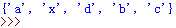
同样add不能传入list,需要一个一个添加
还可以通过clear清除内容
unique_char.clear()
运行结果为:
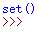
可以通过remove去除某一内容,返回值为None
print(unique_char.remove(‘x‘))
print(unique_char)
运行结果为: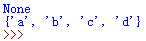
如果remove的内容是对象中没有的,则运行将会报错,为了避免这种情况,可使用discard,运行将不会报错,返回None
使用difference和intersection来寻找两个序列中不同和相同的内容,代码如下所示:
set1=unique_char
set2={‘a‘,‘e‘,‘i‘}
print(set1)
print(set2)
print(set1.difference(set2))
print(set1.intersection(set2))
运行结果如下所示: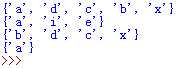
标签:boot error: 不用 将不 example type 3.2 pre 过程
原文地址:http://www.cnblogs.com/wwf828/p/7460809.html