标签:coding es2017 lib ase col rand pre project img
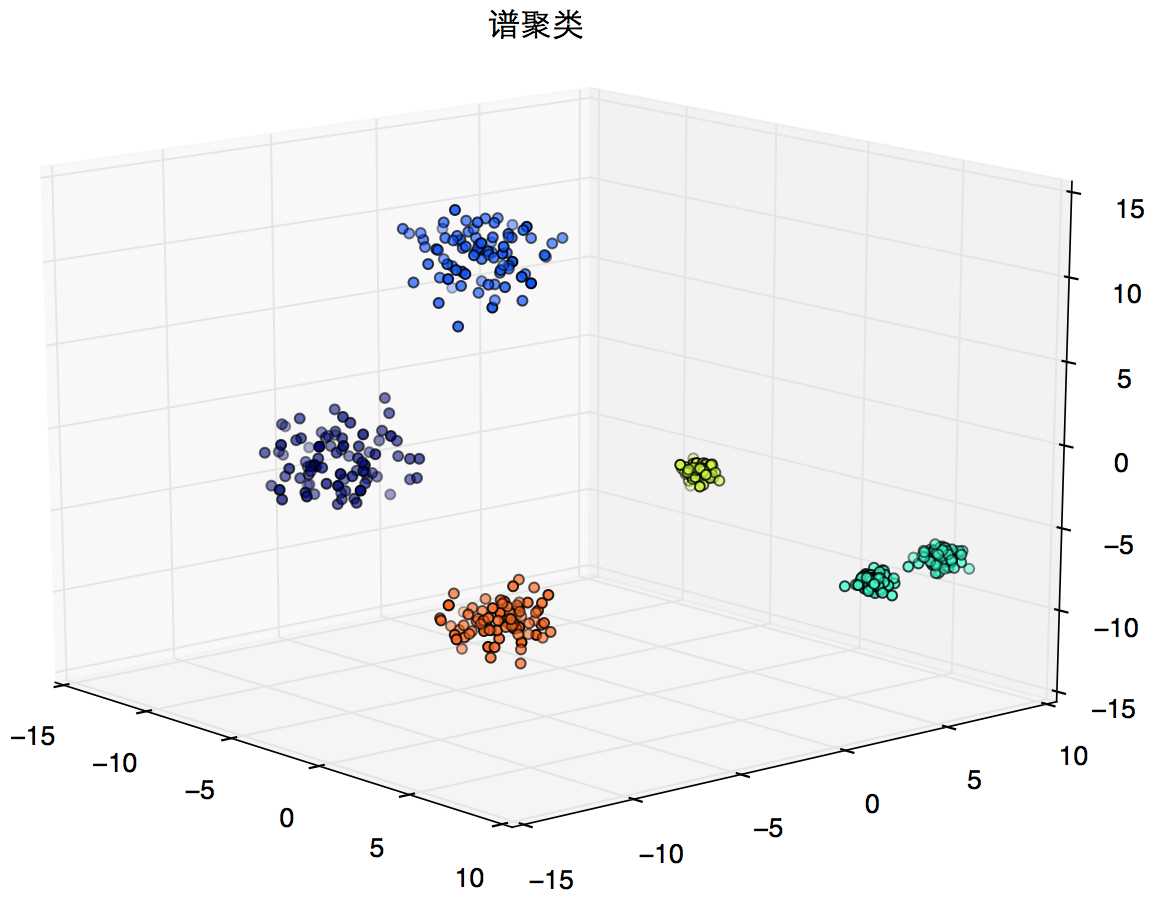
聚类后:
# -*- coding: utf-8 -*-
"""
Created on 09 05 2017
@author: similarface
"""
import numpy as np
import matplotlib.pyplot as plt
import mpl_toolkits.mplot3d.axes3d as p3
from sklearn import datasets
from sklearn import metrics
from sklearn.cluster import SpectralClustering
#500 个样本 3个特征 6个中心 方差数据的离散程度
X, y = datasets.make_blobs(n_samples=500, n_features=3, centers=6, cluster_std=[1.4, 0.3, 1.4, 0.3, 0.4, 0.9],random_state=11)
xx, yy, zz = X[:, 0], X[:, 1], X[:, 2]
# 创建一个三维的绘图工程
ax = plt.subplot(111, projection=‘3d‘)
# 将数据点分成三部分画,在颜色上有区分度
# 绘制数据点
ax.scatter(xx, yy, zz, c=‘y‘)
# 坐标轴
ax.set_zlabel(‘Z‘)
ax.set_ylabel(‘Y‘)
ax.set_xlabel(‘X‘)
plt.show()
#为了区分 聚类成5个类
y_pred = SpectralClustering(n_clusters=5, gamma=0.1).fit_predict(X)
fig = plt.figure()
ax = p3.Axes3D(fig)
ax.view_init(7, -80)
for l in np.unique(y_pred):
ax.scatter(X[y_pred == l, 0], X[y_pred == l, 1], X[y_pred == l, 2],color=plt.cm.jet(float(l) / np.max(y_pred + 1)),s=20, edgecolor=‘k‘)
plt.title(u‘谱聚类‘)
plt.show()
#交叉计算 簇个数 以及RBF的 参数值 最后的max(Calinski-Harabasz Score) 为最佳
# for index, gamma in enumerate((0.01,0.1,1,10)):
# for index, k in enumerate((3,4,5,6)):
# y_pred = SpectralClustering(n_clusters=k, gamma=gamma).fit_predict(X)
# print "Calinski-Harabasz Score with gamma=", gamma, "n_clusters=", k,"score:", metrics.calinski_harabaz_score(X, y_pred)
‘‘‘
http://www.cnblogs.com/pinard/p/6221564.html
‘‘‘
标签:coding es2017 lib ase col rand pre project img
原文地址:http://www.cnblogs.com/similarface/p/7481501.html