标签:[1] dict table search join instance .com quit user
1.
对于Firefox,需要我们设置其Profile:
browser.download.dir:指定下载路径browser.download.folderList:设置成 2 表示使用自定义下载路径;设置成 0 表示下载到桌面;设置成 1 表示下载到默认路径browser.download.manager.showWhenStarting:在开始下载时是否显示下载管理器browser.helperApps.neverAsk.saveToDisk:对所给出文件类型不再弹出框进行询问2.实例。
需求:公司里面总是需要在OSS,根据OSS num下载相应的文件。
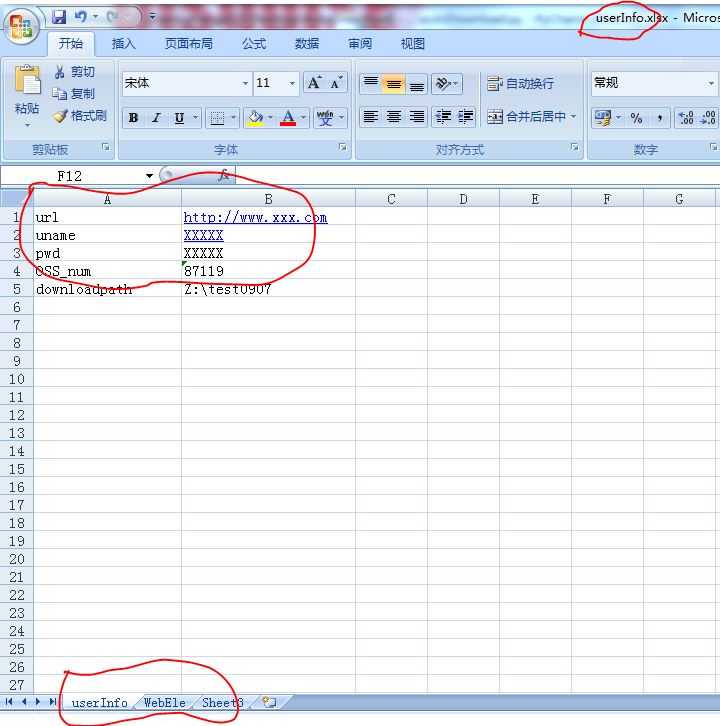
一共写了三部分:autoDownload.py,getUserInfo.py,userInfo.xlsx
#!/usr/bin/env python3 # -*- coding:utf-8 -*- import xlrd class XlUserInfo(object): def __init__(self,path=‘‘): self.path = path self.xl = xlrd.open_workbook(self.path) def get_sheet_info(self): all_info = [] info0 = [] info1 = [] for row in range(0,self.sheet.nrows): info = self.sheet.row_values(row) info0.append(info[0]) info1.append(info[1]) temp = zip(info0,info1) all_info.append(dict(temp)) return all_info.pop(0) def get_sheetinfo_by_name(self,name): self.name = name self.sheet = self.xl.sheet_by_name(self.name) return self.get_sheet_info() if __name__ == ‘__main__‘: xl = XlUserInfo(‘userInfo.xlsx‘) userinfo = xl.get_sheetinfo_by_name(‘userInfo‘) webinfo = xl.get_sheetinfo_by_name(‘WebEle‘) print(userinfo) print(webinfo)
主要用来从userInfo.xlsx中读取用户信息,web的元素。
#!/usr/bin/env python3 # -*- coding:utf-8 -*- from selenium import webdriver from getUserInfo import XlUserInfo import threading class AutoDownload(object): def __init__(self,file_type,args, args2): self.file_type = file_type self.args = args self.args2 = args2 def openBrower(self): self.profile = webdriver.FirefoxProfile() self.profile.accept_untrusted_certs = True if self.args2[‘downloadpath‘] is None: self.profile.set_preference(‘browser.download.dir‘, ‘c:\\‘) else: self.profile.set_preference(‘browser.download.dir‘, self.args2[‘downloadpath‘]) print(self.args2[‘downloadpath‘]) self.profile.set_preference(‘browser.download.folderList‘, 2) self.profile.set_preference(‘browser.download.manager.showWhenStarting‘, False) if self.file_type == ‘xml‘: self.profile.set_preference(‘browser.helperApps.neverAsk.saveToDisk‘, ‘application/xml‘) elif self.file_type == ‘uxz‘: self.profile.set_preference(‘browser.helperApps.neverAsk.saveToDisk‘, ‘application/xml‘) elif self.file_type == ‘txt‘: self.profile.set_preference(‘browser.helperApps.neverAsk.saveToDisk‘, ‘text/plain‘) else: self.profile.set_preference(‘browser.helperApps.neverAsk.saveToDisk‘, ‘text/plain‘) #3,6 xml,tml file # profile.set_preference(‘browser.helperApps.neverAsk.saveToDisk‘, ‘application/xml‘) #2,4 txt,chg file # profile.set_preference(‘browser.helperApps.neverAsk.saveToDisk‘, ‘text/plain‘) self.driver = webdriver.Firefox(firefox_profile=self.profile) self.driver.implicitly_wait(30) return self.driver def openUrl(self): try: self.driver.get(self.args2[‘url‘]) self.driver.maximize_window() except: print("Failed to get {}".format(self.args2[‘url‘])) return self.driver def login(self): ‘‘‘ user_name pwd_name logIn_name ‘‘‘ self.driver.find_element_by_name(self.args[‘user_name‘]).send_keys(self.args2[‘uname‘]) if isinstance(self.args2[‘pwd‘],float): self.driver.find_element_by_name(self.args[‘pwd_name‘]).send_keys(int(self.args2[‘pwd‘])) else: self.driver.find_element_by_name(self.args[‘pwd_name‘]).send_keys(self.args2[‘pwd‘]) self.driver.find_element_by_name(self.args[‘logIn_name‘]).click() self.driver.implicitly_wait(10) return self.driver def download(self): self.driver.implicitly_wait(15) self.driver.find_element_by_link_text(self.args[‘Search_Forms_text‘]).click() self.driver.implicitly_wait(30) self.driver.find_element_by_id(self.args[‘OSS_Num_type_id‘]).send_keys(int(self.args2[‘OSS_num‘])) self.driver.find_element_by_id(self.args[‘Search_button_id‘]).click() self.driver.implicitly_wait(10) self.driver.find_element_by_link_text(str(int(self.args2[‘OSS_num‘]))).click() self.driver.implicitly_wait(20) # Attachments_text self.driver.find_element_by_link_text(self.args[‘Attachments_text‘]).click() self.driver.implicitly_wait(10) if self.file_type == ‘xml‘: self.driver.find_element_by_xpath(‘//table[4]//tr[3]/td[1]/a‘).click() self.driver.implicitly_wait(30) self.driver.find_element_by_xpath(‘//table[4]//tr[6]/td[1]/a‘).click() elif self.file_type == ‘uxz‘: self.driver.find_element_by_xpath(‘//table[4]//tr[5]/td[1]/a‘).click() elif self.file_type == ‘txt‘: self.driver.find_element_by_xpath(‘//table[4]//tr[2]/td[1]/a‘).click() # driver.find_element_by_xpath(‘//table[4]//tr[6]/td[1]/a‘).click() self.driver.implicitly_wait(30) self.driver.find_element_by_xpath(‘//table[4]//tr[4]/td[1]/a‘).click() else: self.driver.quit() def quit(self): self.driver.quit() def Run(self): self.openBrower() self.openUrl() self.login() self.download() self.quit() if __name__ == ‘__main__‘: xl = XlUserInfo(‘userInfo.xlsx‘) userinfo = xl.get_sheetinfo_by_name(‘userInfo‘) webinfo = xl.get_sheetinfo_by_name(‘WebEle‘) print(userinfo) print(webinfo) down_txt = AutoDownload(‘txt‘,webinfo,userinfo) down_xml = AutoDownload(‘xml‘,webinfo,userinfo) threads = [] t1 = threading.Thread(target=down_txt.Run) t2 = threading.Thread(target=down_xml.Run) threads.append(t1) threads.append(t2) for t in threads: t.start() for i in threads: i.join()
Python selenium 文件自动下载 (自动下载器)
标签:[1] dict table search join instance .com quit user
原文地址:http://www.cnblogs.com/william126/p/7495238.html