标签:logistic 有一个 es2017 eve 方法 style 应该 平均值 数值
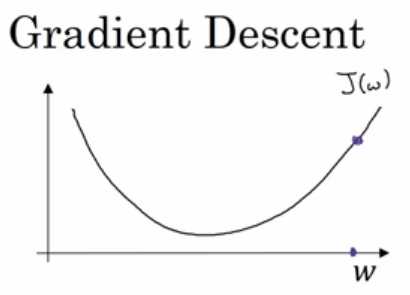
2.4 梯度下降算法(非常重要,重点理解)
原文地址:http://www.cnblogs.com/yangzsnews/p/7496645.html
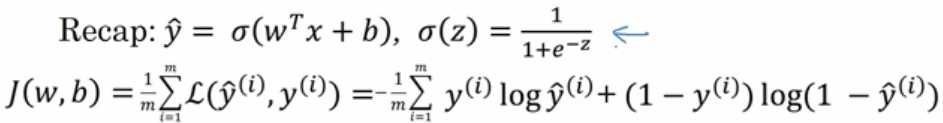
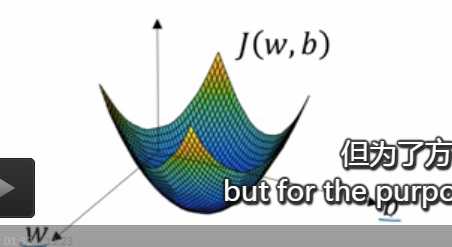
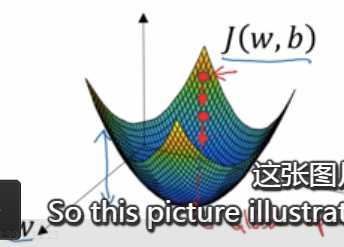
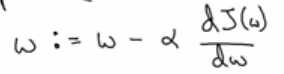
 ,我们使用dw作为导数的变量名,
,我们使用dw作为导数的变量名,