标签:windows har image 英文 name 不同 python3 环境 解决
为什么要进行编码和转码
由于每个国家电脑的字符编码格式不统一(列中国:GBK),同一款软件放到不同国家的电脑上会出现乱码的情况,出现这种情况如何解决呢?! 当然由于所有国家的电脑都支持Unicode万国码,那么我们可以把Unicode为跳板,先把字符编码转换为Unicode,在把Unicode转换为另一个国家的字符编码(例韩国),则不会出现乱码的情况。当然这里只是转编码集并不是翻译成韩文不要弄混了。
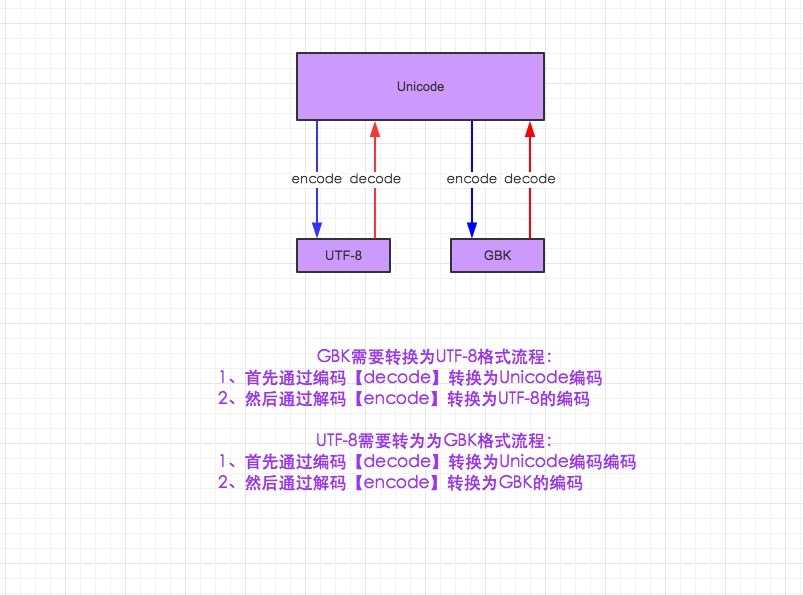
Python3.0进行编码转换
# __author__:"ShengXin" # __date__:2017/9/9 #Python3.0环境 import sys,chardet print (sys.getdefaultencoding()) #获取默认编码(UTF-8) name = "盛欣" #此时name为Unicode编码 name_utf8 = name.encode("utf-8") #转为UTF-8编码 print(name_utf8) print(chardet.detect(name_utf8)) #注:Unicode编码无法用chardet查看编码格式 print(name_utf8.decode("utf-8")) #编码为UTF-8后再转码为Unicode name_gbk = name.encode("gbk") #转为GBK编码 print(name_gbk) print(chardet.detect(name_gbk)) #查看当前的字符编码格式 print(name_gbk.decode("gbk")) #编码为GBK后再转码为Unicode #utf-8 #b‘\xe8\xbf\x9e\xe5\xbf\x97\xe9\x9b\xb7‘ #{‘confidence‘: 0.87625, ‘encoding‘: ‘utf-8‘} #盛欣 #b‘\xc1\xac\xd6\xbe\xc0\xd7‘ #{‘confidence‘: 0.73, ‘encoding‘: ‘windows-1252‘} #盛欣
Python2.0中的编码转换
① 声明字符编码(utf-8)
# __author__:"ShengXin" # __date__:2017/9/9 #Python2.0环境 默认编码ascii import sys name = "你好" #ascii码里是没有字符“你好”的,此时的name为uft-8 print (sys.getdefaultencoding()) #获取默认编码 print(name.decode("utf-8")) #把uft-8码解码为Unicode name_unicode=name.decode("utf-8") print (name_unicode,type(name.decode("utf-8"))) #查看当前的字符编码 name_gbk=name_unicode.encode("gbk") #把字符有Unicode转换为gbk print(name_gbk) #ascii #你好 #(u‘\u4f60\u597d‘, <type ‘unicode‘>) #???
② 使用默认字符编码(ascii)
# __author__:"ShengXin" # __date__:2017/9/9 import sys name = "nihao" #英文字符,且第二行字符声明去掉,此刻name为ascii码 print (sys.getdefaultencoding()) #获取系统编码 name_unicode = name.decode("ascii") #ascii码转换为unicode print(name_unicode,type(name_unicode)) name_utf8=name_unicode.encode("utf-8") #unicode转换为utf-8 print(name_utf8,type(name_utf8)) name_gbk=name_unicode.encode("gbk") #unicode转换为gbk print(name_gbk,type(name_gbk)) #ascii #(u‘nihao‘, <type ‘unicode‘>) #(‘nihao‘, <type ‘str‘>) #(‘nihao‘, <type ‘str‘>)
总结:Python2.x里默认字符编码为ascii,如果不声明编码格式,则输入的字符格式都是ascii码(中文不在ascii里面,输入报错);如果要输入中文字符,则需要声明编码格式,此时中文字符的编码格式不跟随默认字符编码格式,而是与声明的编码格式一致(上面实例为utf-8),这些都需谨记。
标签:windows har image 英文 name 不同 python3 环境 解决
原文地址:http://www.cnblogs.com/SHENGXIN/p/7497131.html