标签:rom 原则 logs 源代码 lte image 表达 append update
目标:获取股票上交所和深交所所有股票的名称和交易信息,保存在文件中
使用到的技术:requests+bs4+re
网站的选择(选取原则:股票信息静态存在HTML页面,非js代码生成没哟robot协议限制)
1. 获取股票列表:http://quote.eastmoney.com/stocklist.html (因为东方财富网站的有全部股票信息的列表,百度股票网站只要个股信息)
2. 获取个股信息:
百度股票:https://gupiao.baidu.com/stock/
单个股票:https://gupiao.baidu.com/stock/sz002939.html
程序的设计结构:
步骤1:从东方财富获取股票列表
步骤2:根据股票列表逐个到百度股票获取个股信息
步骤3:将结果存储到文件
【步骤1】
通过发送请求获取到东方财富网站股票列表信息,查看页面源代码,如下:
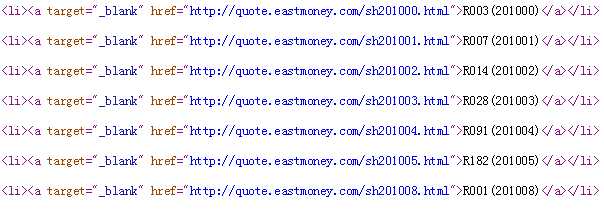
发现股票代码存储在<a>的href属性中,且上交和深交的股票代码前分别为“sh”和"sz",接下来可以利用这个规律进行解析和匹配。
首先使用BeautifulSoup4获取所有<a>:
soup = BeautifulSoup(html, ‘html.parser‘)
a = soup.find_all(‘a‘)
然后配合正则表达式提取的股票代码,并存储在lst列表中:
for i in a:
try:
href = i.attrs[‘href‘]
lst.append(re.findall(r"[s][hz]\d{6}", href)[0])
except:
continue
此时列表 lst = [‘sh201000‘ , ‘sh201001‘ , ‘sh201002‘ ...]
【步骤2】
接下来根据获取的股票代码列表,逐个在百度股票获取个股信息。
百度股票个股信息的url:https://gupiao.baidu.com/stock/sz002939.html
因此,先进行url的拼接,然后发送请求获取页面
for stock in lst:
url = ‘https://gupiao.baidu.com/stock/‘ + stock + ".html"
html = getHTMLText(url)
然后进行页面解析,查看源代码

发现所有的股票信息都存在的<dt><dd>中,然后使用BeautifulSoup进行一步一步的解析
soup = BeautifulSoup(html, ‘html.parser‘)
stockInfo = soup.find(‘div‘,attrs={‘class‘:‘stock-bets‘})
if stockInfo:
name = stockInfo.find_all(attrs={‘class‘:‘bets-name‘})[0]
infoDict.update({‘股票名称‘: name.text.split()[0]})
else:
print(‘stockInfo is null‘)
break
keyList = stockInfo.find_all(‘dt‘)
valueList = stockInfo.find_all(‘dd‘)
for i in range(len(keyList)):
key = keyList[i].text
val = valueList[i].text
infoDict[key] = val
此时,infoDict = {"成交量":"31.07万手" , "最高":"9.89", "涨停":"10.86" ...}
【步骤3】
最后,把结果输出到文件中:
with open(fpath, ‘a‘, encoding=‘utf-8‘) as f:
f.write( str(infoDict) + ‘\n‘ )
完整代码如下:
#CrawBaiduStocksA.py import requests from bs4 import BeautifulSoup import traceback import re #获取页面的公共方法 def getHTMLText(url): try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "get fail" #获取股票代码列表 def getStockList(lst, stockURL): html = getHTMLText(stockURL) soup = BeautifulSoup(html, ‘html.parser‘) a = soup.find_all(‘a‘) for i in a: try: href = i.attrs[‘href‘] lst.append(re.findall(r"[s][hz]\d{6}", href)[0]) except: continue #获取个股信息并输出到文件中 def getStockInfo(lst, stockURL, fpath): for stock in lst: url = stockURL + stock + ".html" html = getHTMLText(url) try: if html=="": continue infoDict = {} soup = BeautifulSoup(html, ‘html.parser‘) stockInfo = soup.find(‘div‘,attrs={‘class‘:‘stock-bets‘}) if stockInfo: name = stockInfo.find_all(attrs={‘class‘:‘bets-name‘})[0] infoDict.update({‘股票名称‘: name.text.split()[0]}) else: print(‘stockInfo is null‘) break keyList = stockInfo.find_all(‘dt‘) valueList = stockInfo.find_all(‘dd‘) for i in range(len(keyList)): key = keyList[i].text val = valueList[i].text infoDict[key] = val with open(fpath, ‘a‘, encoding=‘utf-8‘) as f: f.write( str(infoDict) + ‘\n‘ ) except: traceback.print_exc() continue def main(): stock_list_url = ‘http://quote.eastmoney.com/stocklist.html‘ #东放财富股票列表 stock_info_url = ‘https://gupiao.baidu.com/stock/‘ #百度股票信息 output_file = ‘D:/BaiduStockInfo.txt‘ #结果存储的文件 slist=[] getStockList(slist, stock_list_url) getStockInfo(slist, stock_info_url, output_file) main()
标签:rom 原则 logs 源代码 lte image 表达 append update
原文地址:http://www.cnblogs.com/wyfighting/p/7497985.html