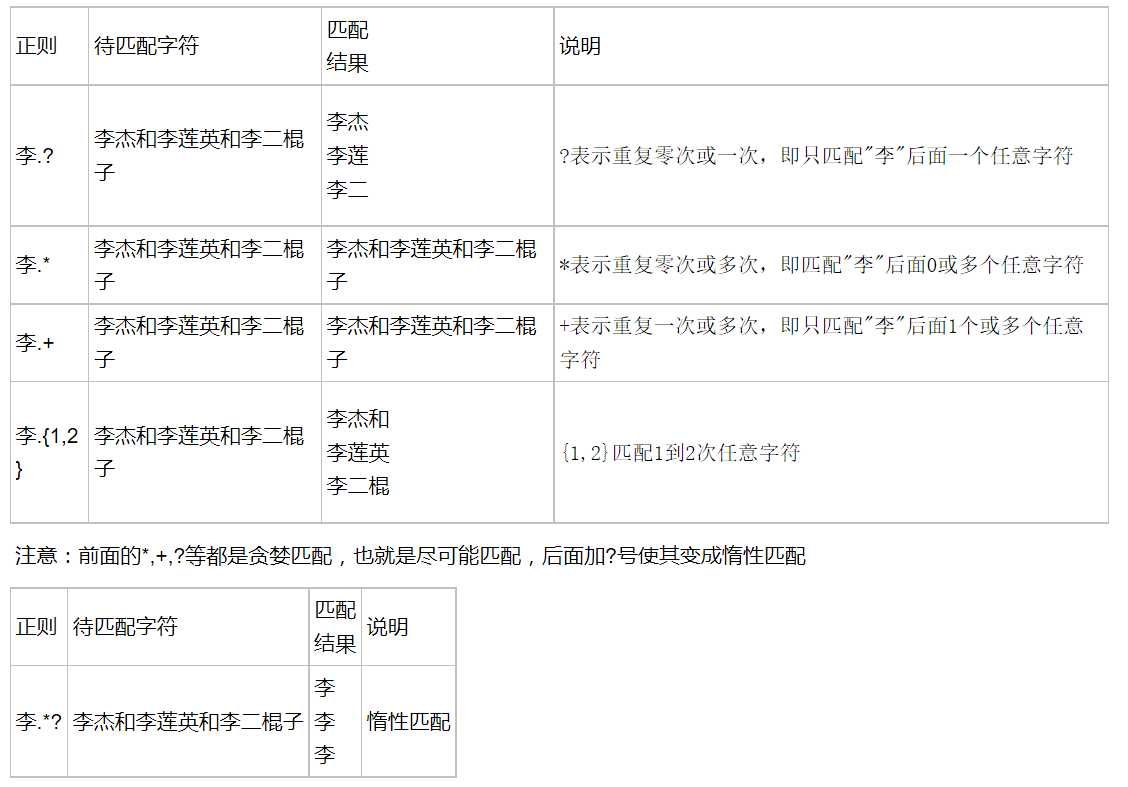
标签:起名字 and 区分大小写 独立 分组 oldboy inf zab mil
正则表达式并不是python中的一部分,正则表达式适用于处理字符串的强大工具,拥有自己独特的语法,以及独立的处理引擎.在提供了正则表达式的语言中都它的语法是都一样的
re模块本质上和正则表达式没有一毛钱的关系,re模块是python提供给我们方便操作正则的工具而已
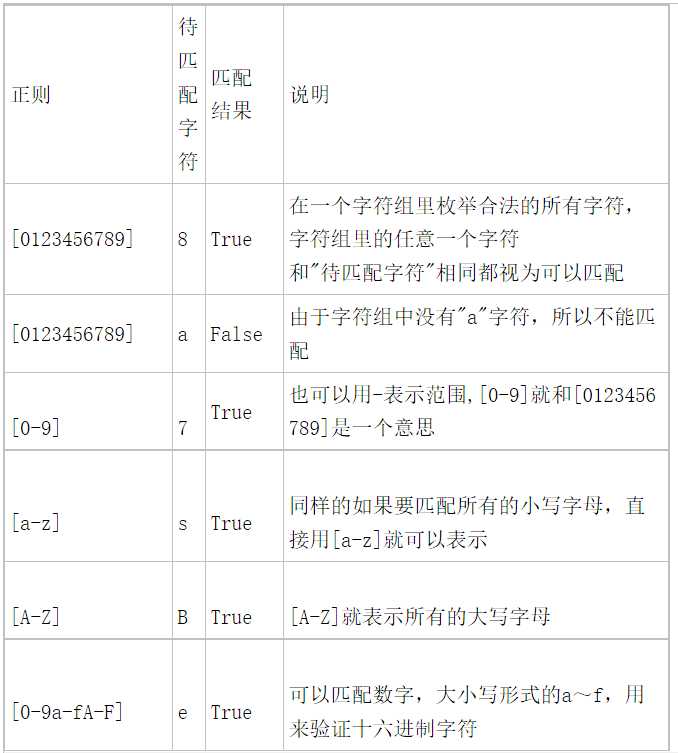
字符组 : [字符组]
在同一个位置可能出现的各种字符组成了一个字符组,在正则表达式中用[]表示
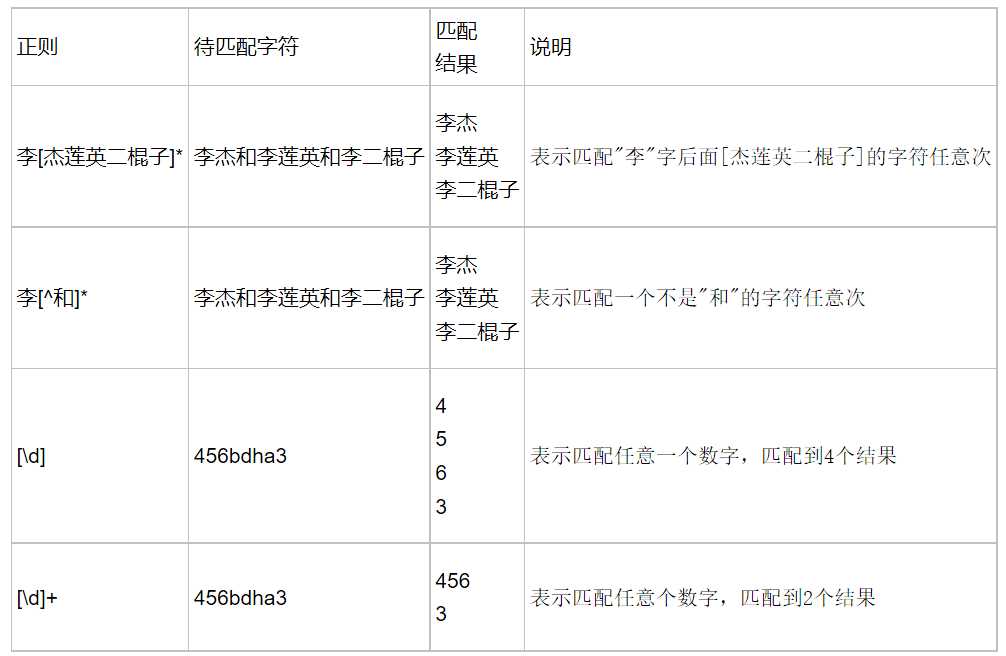
字符分为很多类,比如数字、字母、标点等等。
假如你现在要求一个位置"只能出现一个数字",那么这个位置上的字符只能是0、1、2...9这10个数之一。
字符匹配
打天下必备 神器 , 学不了吃亏学不了上当
跟在元字符后面,只定义它(量词)之前的元字符匹配数量
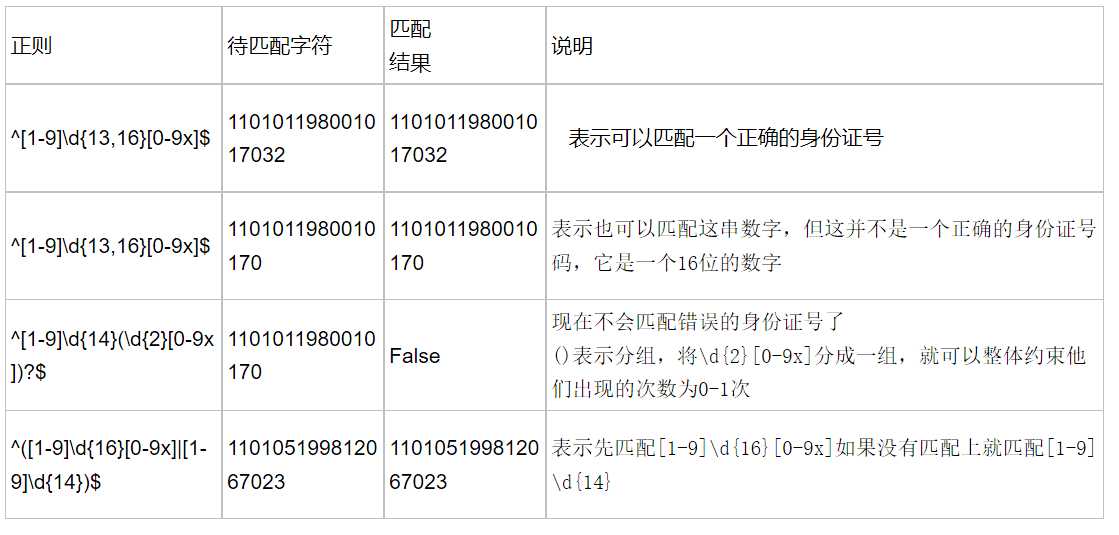
身份证号码是一个长度为15或18个字符的字符串,如果是15位则全部???数字组成,首位不能为0;如果是18位,则前17位全部是数字,末位可能是数字或x,下面我们尝试用正则来表示:
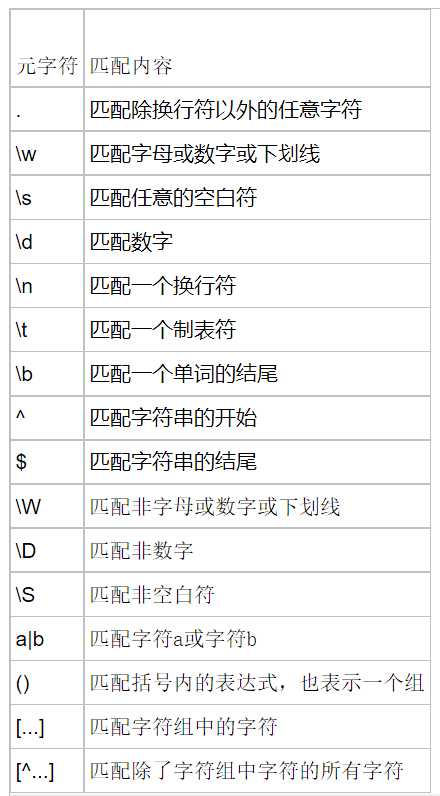
在正则表达式中,有很多有特殊意义的是元字符,比如\d和\s等,如果要在正则中匹配正常的"\d"而不是"数字"就需要对"\"进行转义,变成‘\\‘。
在python中,无论是正则表达式,还是待匹配的内容,都是以字符串的形式出现的,在字符串中\也有特殊的含义,本身还需要转义。所以如果匹配一次"\d",字符串中要写成‘\\d‘,那么正则里就要写成"\\\\d",这样就太麻烦了。这个时候我们就用到了r‘\d‘这个概念,此时的正则是r‘\\d‘就可以了。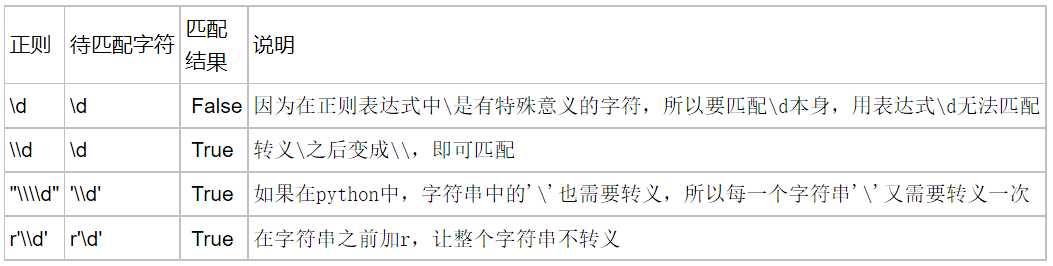
*? 重复任意次,但尽可能少重复
+? 重复1次或更多次,但尽可能少重复
?? 重复0次或1次,但尽可能少重复
{n,m}? 重复n到m次,但尽可能少重复
{n,}? 重复n次以上,但尽可能少重复
*? 重复任意次,但尽可能少重复
+? 重复1次或更多次,但尽可能少重复
?? 重复0次或1次,但尽可能少重复
{n,m}? 重复n到m次,但尽可能少重复
{n,}? 重复n次以上,但尽可能少重复
*******************************************我是华丽丽的分割线********************************************************************
字符匹配
字符匹配
匹配任意一个字符
# 匹配字符串abc,.代表b
>>> re.match(‘a.c‘,‘abc‘).group()
‘abc‘
数字与非数字
# 匹配任意一数字
>>> re.match(‘\d‘,‘1‘).group()
‘1‘
# 匹配任意一个非数字
>>> re.match(‘\D‘,‘a‘).group()
‘a‘
空白与非空白字符
# 匹配任意一个空白字符
>>> re.match("\s"," ").group()
‘ ‘
# 匹配任意一个非空白字符
>>> re.match("\S","1").group()
‘1‘
>>> re.match("\S","a").group()
‘a‘
单词字符与非单词字符
单词字符即代表[a-zA-Z0-9]
# 匹配任意一个单词字符
>>> re.match("\w","a").group()
‘a‘
>>> re.match("\w","1").group()
‘1‘
# 匹配任意一个非单词字符
>>> re.match("\W"," ").group()
‘ ‘
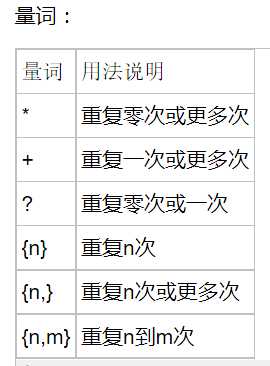
次数匹配
匹配前一个字符0次或者无限次
>>> re.match(‘[A-Z][a-z]*‘,‘Aaa‘).group()
‘Aaa‘
>>> re.match(‘[A-Z][a-z]*‘,‘Aa‘).group()
‘Aa‘
>>> re.match(‘[A-Z][a-z]*‘,‘A‘).group()
‘A‘
匹配前一个字符1次或者无限次
# 匹配前一个字符至少一次,如果一次都没有就会报错
>>> re.match(‘[A-Z][a-z]+‘,‘A‘).group()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: ‘NoneType‘ object has no attribute ‘group‘
>>> re.match(‘[A-Z][a-z]+‘,‘Aa‘).group()
‘Aa‘
>>> re.match(‘[A-Z][a-z]+‘,‘Aaaaaaa‘).group()
‘Aaaaaaa‘
匹配前一个字符0次或者1次
>>> re.match(‘[A-Z][a-z]?‘,‘A‘).group()
‘A‘
# 只匹配出一个a
>>> re.match(‘[A-Z][a-z]?‘,‘Aaaa‘).group()
‘Aa‘
匹配前一个字符m次或者N次
#匹配前一个字符至少5次
>>> re.match(‘\w{5}‘,‘asd234‘).group()
‘asd23‘
# 匹配前面的字符6-10次
>>> re.match(‘\w{6,10}‘,‘asd234‘).group()
‘asd234‘
# 超过的字符就匹配不出来
>>> re.match(‘\w{6,10}‘,‘asd2313qeadsd4‘).group()
‘asd2313qea‘
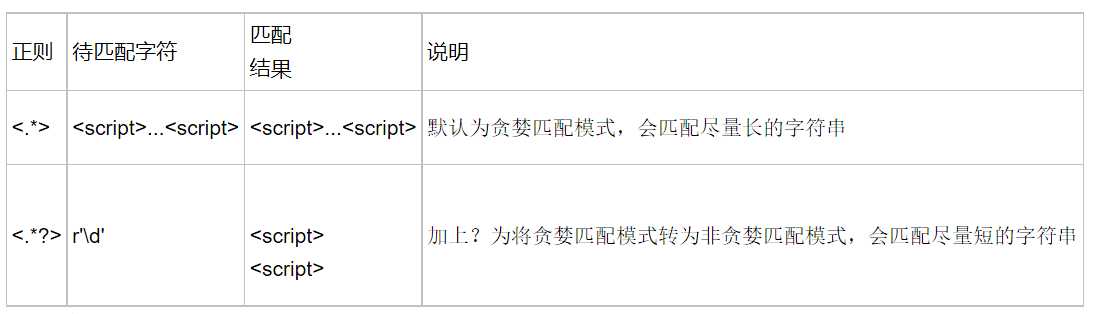
贪婪匹配
匹配模式变为贪婪模式
>>> re.match(r‘[0-9][a-z]*‘,‘1bc‘).group()
‘1bc‘
# *?匹配0次或者多次
>>> re.match(r‘[0-9][a-z]*?‘,‘1bc‘).group()
‘1‘
# +?匹配一次或者多次,但是只匹配了一次
>>> re.match(r‘[0-9][a-z]+?‘,‘1bc‘).group()
‘1b‘
# ??匹配0次或者一次
>>> re.match(r‘[0-9][a-z]??‘,‘1bc‘).group()
‘1‘
贪婪匹配和非贪婪匹配
边界匹配
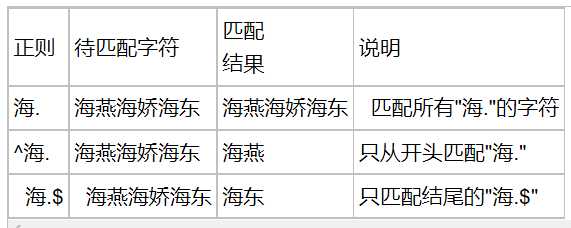
匹配字符串开头
# 必须以指定的字符串开头,结尾必须是@163.com
>>> re.match(‘^[\w]{4,6}@163.com$‘,‘asdasd@163.com‘).group()
‘asdasd@163.com‘
匹配字符串结尾
# 必须以.me结尾
>>> re.match(‘[\w]{1,20}.me$‘,‘ansheng.me‘).group()
‘ansheng.me‘
指定的字符串必须出现在开头/结尾
>>> re.match(r‘\Awww[\w]*\me‘,‘wwwanshengme‘).group()
‘wwwanshengme‘
分组匹配
匹配左右任意一个表达式
>>> re.match("www|me","www").group()
‘www‘
>>> re.match("www|me","me").group()
‘me‘
(ab) 括号中表达式作为一个分组
# 匹配163或者126的邮箱
>>> re.match(r‘[\w]{4,6}@(163|126).com‘,‘asdasd@163.com‘).group()
‘asdasd@163.com‘
>>> re.match(r‘[\w]{4,6}@(163|126).com‘,‘asdasd@126.com‘).group()
‘asdasd@126.com‘
(?P) 分组起一个别名
>>> re.search("(?P<zimu>abc)(?P<shuzi>123)","abc123").groups()
(‘abc‘, ‘123‘)
引用别名为name的分组匹配字符串
>>> res.group("shuzi")
‘123‘
>>> res.group("zimu")
‘abc‘
代码体现
re.match()
语法格式:
match(pattern, string, flags=0)
释意:
Try to apply the pattern at the start of the string, returning a match object, or None if no match was found.
实例:
# 从头开始匹配,匹配成功则返回匹配的对象
>>> re.match("abc","abc123def").group()
‘abc‘
# 从头开始匹配,如果没有匹配到对应的字符串就报错
>>> re.match("\d","abc123def").group()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: ‘NoneType‘ object has no attribute ‘group‘
re.search()
语法格式:
search(pattern, string, flags=0)
释意:
Scan through string looking for a match to the pattern, returning a match object, or None if no match was found.
实例:
# 匹配整个字符串,匹配到第一个的时候就返回匹配到的对象
>>> re.search("\d","abc1123def").group()
‘1‘
re.findall()
语法格式:
findall(pattern, string, flags=0)
释意:
Return a list of all non-overlapping matches in the string.
实例:
# 匹配字符串所有的内容,把匹配到的字符串以列表的形式返回
>>> re.findall("\d","abc123def456")
[‘1‘, ‘2‘, ‘3‘, ‘4‘, ‘5‘, ‘6‘]
re.split
语法格式:
split(pattern, string, maxsplit=0)
释意:
Split the source string by the occurrences of the pattern, returning a list containing the resulting substrings.
实例:
# 指定以数字进行分割,返回的是一个列表对象
>>> re.split("\d+","abc123def4+-*/56")
[‘abc‘, ‘def‘, ‘+-*/‘, ‘‘]
# 以多个字符进行分割
>>> re.split("[\d,]","a,b1c")
[‘a‘, ‘b‘, ‘c‘]
re.sub()
语法格式:
sub(pattern, repl, string, count=0)
释意:
Return the string obtained by replacing the leftmost non-overlapping occurrences of the pattern in string by the replacement repl. repl can be either a string or a callable; if a string, backslash escapes in it are processed. If it is a callable, it’s passed the match object and must return a replacement string to be used.
实例:
# 把abc替换成def
>>> re.sub("abc","def","abc123abc")
‘def123def‘
# 只替换查找到的第一个字符串
>>> re.sub("abc","def","abc123abc",count=1)
‘def123abc‘
import re
ret = re.findall(‘a‘, ‘eva egon yuan‘) # 返回所有满足匹配条件的结果,放在列表里
print(ret) #结果 : [‘a‘, ‘a‘]
ret = re.search(‘a‘, ‘eva egon yuan‘).group()
print(ret) #结果 : ‘a‘
# 函数会在字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以
# 通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。
ret = re.match(‘a‘, ‘abc‘).group() # 同search,不过尽在字符串开始处进行匹配
print(ret)
#结果 : ‘a‘
ret = re.split(‘[ab]‘, ‘abcd‘) # 先按‘a‘分割得到‘‘和‘bcd‘,在对‘‘和‘bcd‘分别按‘b‘分割
print(ret) # [‘‘, ‘‘, ‘cd‘]
ret = re.sub(‘\d‘, ‘H‘, ‘eva3egon4yuan4‘, 1)#将数字替换成‘H‘,参数1表示只替换1个
print(ret) #evaHegon4yuan4
ret = re.subn(‘\d‘, ‘H‘, ‘eva3egon4yuan4‘)#将数字替换成‘H‘,返回元组(替换的结果,替换了多少次)
print(ret)
obj = re.compile(‘\d{3}‘) #将正则表达式编译成为一个 正则表达式对象,规则要匹配的是3个数字
ret = obj.search(‘abc123eeee‘) #正则表达式对象调用search,参数为待匹配的字符串
print(ret.group()) #结果 : 123
import re
ret = re.finditer(‘\d‘, ‘ds3sy4784a‘) #finditer返回一个存放匹配结果的迭代器
print(ret) # <callable_iterator object at 0x10195f940>
print(next(ret).group()) #查看第一个结果
print(next(ret).group()) #查看第二个结果
print([i.group() for i in ret]) #查看剩余的左右结果
注意:
1 findall的优先级查询:
import re
ret = re.findall(‘www.(baidu|oldboy).com‘, ‘www.oldboy.com‘)
print(ret) # [‘oldboy‘] 这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可
ret = re.findall(‘www.(?:baidu|oldboy).com‘, ‘www.oldboy.com‘)
print(ret) # [‘www.oldboy.com‘]
2 split的优先级查询
ret=re.split("\d+","eva3egon4yuan")
print(ret) #结果 : [‘eva‘, ‘egon‘, ‘yuan‘]
ret=re.split("(\d+)","eva3egon4yuan")
print(ret) #结果 : [‘eva‘, ‘3‘, ‘egon‘, ‘4‘, ‘yuan‘]
#在匹配部分加上()之后所切出的结果是不同的,
#没有()的没有保留所匹配的项,但是有()的却能够保留了匹配的项,
#这个在某些需要保留匹配部分的使用过程是非常重要的。
string方法包含了一百个可打印的ASCII字符,大小写字母、数字、空格以及标点符号 >>> import string >>> printable = string.printable >>> printable ‘0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!"#$%&\‘()*+,-./:;<=>?@[\\]^_`{|}~ \t\n\r\x0b\x0c‘ >>> import re # 定义的字符串 >>> source = ‘‘‘I wish I may, I wish I migth ... Hava a dish of fish tonight.‘‘‘ # 在字符串中检索wish >>> re.findall(‘wish‘,source) [‘wish‘, ‘wish‘] # 对源字符串任意位置查询wish或者fish >>> re.findall(‘wish|fish‘,source) [‘wish‘, ‘wish‘, ‘fish‘] # 从字符串开头开始匹配wish >>> re.findall(‘^wish‘,source) [] # 从字符串开头匹配I wish >>> re.findall(‘^I wish‘,source) [‘I wish‘] # 从字符串结尾匹配fish >>> re.findall(‘fish$‘,source) [] # 从字符串结尾匹配fish tonight. >>> re.findall(‘fish tonight.$‘,source) [‘fish tonight.‘] # 查询以w或f开头,后面紧跟着ish的匹配 >>> re.findall(‘[wf]ish‘,source) [‘wish‘, ‘wish‘, ‘fish‘] # 查询以若干个w\s\h组合的匹配 >>> re.findall(‘[wsh]+‘,source) [‘w‘, ‘sh‘, ‘w‘, ‘sh‘, ‘h‘, ‘sh‘, ‘sh‘, ‘h‘] # 查询以ght开头,后面紧跟着一个非数字和字母的匹配 >>> re.findall(‘ght\W‘,source) [‘ght.‘] # 查询已以I开头,后面紧跟着wish的匹配 >>> re.findall(‘I (?=wish)‘,source) [‘I ‘, ‘I ‘] # 最后查询以wish结尾,前面为I的匹配(I出现次数尽量少) >>> re.findall(‘(?<=I) wish‘,source) [‘ wish‘, ‘ wish‘] 匹配时不区分大小写 >>> re.match(‘a‘,‘Abc‘,re.I).group() ‘A‘ r 源字符串,转义,如果要转义要加两个\n >>> import re >>> pa = re.compile(r‘ansheng‘) >>> pa.match("ansheng.me") <_sre.SRE_Match object; span=(0, 7), match=‘ansheng‘> >>> ma = pa.match("ansheng.me") >>> ma <_sre.SRE_Match object; span=(0, 7), match=‘ansheng‘> # 匹配到的值存到group内 >>> ma.group() ‘ansheng‘ # 返回字符串的所有位置 >>> ma.span() (0, 7) # 匹配的字符串会被放到string中 >>> ma.string ‘ansheng.me‘ # 实例放在re中 >>> ma.re re.compile(‘ansheng‘)
练习1
import re ret = re.search("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>") #还可以在分组中利用?<name>的形式给分组起名字 #获取的匹配结果可以直接用group(‘名字‘)拿到对应的值 print(ret.group(‘tag_name‘)) #结果 :h1 print(ret.group()) #结果 :<h1>hello</h1> ret = re.search(r"<(\w+)>\w+</\1>","<h1>hello</h1>") #如果不给组起名字,也可以用\序号来找到对应的组,表示要找的内容和前面的组内容一致 #获取的匹配结果可以直接用group(序号)拿到对应的值 print(ret.group(1)) print(ret.group()) #结果 :<h1>hello</h1>
练习2
import re
ret=re.findall(r"\d+","1-2*(60+(-40.35/5)-(-4*3))")
print(ret) #[‘1‘, ‘2‘, ‘60‘, ‘40‘, ‘35‘, ‘5‘, ‘4‘, ‘3‘]
ret=re.findall(r"-?\d+\.\d*|(-?\d+)","1-2*(60+(-40.35/5)-(-4*3))")
print(ret) #[‘1‘, ‘-2‘, ‘60‘, ‘‘, ‘5‘, ‘-4‘, ‘3‘]
ret.remove("")
print(ret) #[‘1‘, ‘-2‘, ‘60‘, ‘5‘, ‘-4‘, ‘3‘]
练习3
1、 匹配一段文本中的每行的邮箱
http://blog.csdn.net/make164492212/article/details/51656638
2、 匹配一段文本中的每行的时间字符串,比如:‘1990-07-12’;
分别取出1年的12个月(^(0?[1-9]|1[0-2])$)、
一个月的31天:^((0?[1-9])|((1|2)[0-9])|30|31)$
3、 匹配qq号。(腾讯QQ号从10000开始) [1,9][0,9]{4,}
4、 匹配一个浮点数。 ^(-?\d+)(\.\d+)?$ 或者 -?\d+\.?\d*
5、 匹配汉字。 ^[\u4e00-\u9fa5]{0,}$
6、 匹配出所有整数
练习4

import requests import re import json def getPage(url): response=requests.get(url) return response.text def parsePage(s): com=re.compile(‘<div class="item">.*?<div class="pic">.*?<em .*?>(?P<id>\d+).*?<span class="title">(?P<title>.*?)</span>‘ ‘.*?<span class="rating_num" .*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)评价</span>‘,re.S) ret=com.finditer(s) for i in ret: yield { "id":i.group("id"), "title":i.group("title"), "rating_num":i.group("rating_num"), "comment_num":i.group("comment_num"), } def main(num): url=‘https://movie.douban.com/top250?start=%s&filter=‘%num response_html=getPage(url) ret=parsePage(response_html) print(ret) f=open("move_info7","a",encoding="utf8") for obj in ret: print(obj) data=json.dumps(obj,ensure_ascii=False) f.write(data+"\n") if __name__ == ‘__main__‘: count=0 for i in range(10): main(count) count+=25
import re import json from urllib.request import urlopen def getPage(url): response = urlopen(url) return response.read().decode(‘utf-8‘) def parsePage(s): com = re.compile( ‘<div class="item">.*?<div class="pic">.*?<em .*?>(?P<id>\d+).*?<span class="title">(?P<title>.*?)</span>‘ ‘.*?<span class="rating_num" .*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)评价</span>‘, re.S) ret = com.finditer(s) for i in ret: yield { "id": i.group("id"), "title": i.group("title"), "rating_num": i.group("rating_num"), "comment_num": i.group("comment_num"), } def main(num): url = ‘https://movie.douban.com/top250?start=%s&filter=‘ % num response_html = getPage(url) ret = parsePage(response_html) print(ret) f = open("move_info7", "a", encoding="utf8") for obj in ret: print(obj) data = str(obj) f.write(data + "\n") count = 0 for i in range(10): main(count) count += 25 简化版
flags有很多可选值: re.I(IGNORECASE)忽略大小写,括号内是完整的写法 re.M(MULTILINE)多行模式,改变^和$的行为 re.S(DOTALL)点可以匹配任意字符,包括换行符 re.L(LOCALE)做本地化识别的匹配,表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境,不推荐使用 re.U(UNICODE) 使用\w \W \s \S \d \D使用取决于unicode定义的字符属性。在python3中默认使用该flag re.X(VERBOSE)冗长模式,该模式下pattern字符串可以是多行的,忽略空白字符,并可以添加注释 flags
练习5 计算器
import re def silmple_cal(mul_div): ‘‘‘计算最简单的表达式‘‘‘ if ‘/‘ in mul_div: val1,val2 = mul_div.split(‘/‘) ret_val = float(val1)/float(val2) return ret_val elif ‘*‘ in mul_div: val1, val2 = mul_div.split(‘*‘) ret_val = float(val1) * float(val2) return ret_val def modify_express(express): express = express.replace(‘--‘,‘+‘) express = express.replace(‘-+‘,‘-‘) express = express.replace(‘+-‘,‘-‘) express = express.replace(‘++‘,‘+‘) return express def express_cal(express_new): # 没有括号的表达式的计算 no_bracket_express = express_new.strip(‘()‘) # 去括号的表达式 9-2*5/3+7/3*99/4*2998+10*568/14 while re.search(r‘\d+\.?\d*[*/]\-?\d+\.?\d*‘, no_bracket_express): ret_mul_div = re.search(r‘\d+\.?\d*[*/]\-?\d+\.?\d*‘, no_bracket_express) mul_div = ret_mul_div.group() # 40/5 ret_val = silmple_cal(mul_div) # 8.0 no_bracket_express = no_bracket_express.replace(mul_div, str(ret_val), 1) no_bracket_express = modify_express(no_bracket_express) ret_lst = re.findall(r‘[+\-]?\d+\.?\d*‘, no_bracket_express) if ret_lst: total = 0 for item in ret_lst: total += float(item) return total return no_bracket_express #去括号 def remove_bracket(s): while re.search(r‘\([^()]+\)‘,s): express_new = re.search(r‘\([^()]+\)‘,s).group() #拿到第一个最里层的括号内的东西 ret_val = express_cal(express_new) express = s.replace(express_new,str(ret_val)) #整理算式中的+-号 s = modify_express(express) ret = express_cal(s) return ret s= ‘1-2*((60-30+(-40/5)*(9-2*5/3+7/3*99/4 *2998 +10* 568/14))-(-4*3)/(16-3*2))‘ #去空格 s = s.replace(‘ ‘,‘‘) ret = remove_bracket(s) print(‘result : ‘,ret)
#!/usr/bin/env python # -*- coding:utf-8 -*- # Author:郑国栋 import re def del_bracket(data): r = re.search(r‘\(([^()]+)\)‘, data) if not r: res = jiajian(chengchu(data)) return res return del_bracket(data.replace(r.group(), str(jiajian(chengchu(re.split(‘[()]‘, r.group())[1]))))) def chengchu(data): r = re.search(r‘(\d+\.?\d*\*-?\d+\.?\d*)|(\d+\.?\d*/-?\d+\.?\d*)‘, data) if not r: return data if ‘*‘ in r.group(): n1, n2 = r.group().split(‘*‘) value = float(n1) * float(n2) else: n1, n2 = r.group().split(‘/‘) value = float(n1) / float(n2) return chengchu(data.replace(r.group(), str(value))) def jiajian(res): res = res.replace(‘+-‘, ‘-‘).replace(‘--‘, ‘+‘).replace(‘-+‘, ‘-‘).replace(‘++‘, ‘+‘) r = re.search(‘-?\d+\.*\d*[\+\-]{1}\d+\.*\d*‘, res) if not r: return res if ‘+‘ in r.group(): n1, n2 = r.group().split(‘+‘) value = float(n1) + float(n2) else: if r.group().startswith(‘-‘): _, n1, n2 = r.group().split(‘-‘) value = -(float(n2) + float(n1)) else: n1, n2 = r.group().split(‘-‘) value = float(n1) - float(n2) return jiajian(res.replace(r.group(), str(value))) # a = ‘1-2*((60-30+(-40.0/5)*(9-2*5/3+7/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2))‘ print(del_bracket(input(‘>>>>>>‘).strip().replace(‘ ‘, ‘‘)))
import re def math(dic): x, y = float(dic[‘x‘]), float(dic[‘y‘]) if dic[‘mark‘] == ‘+‘: return x + y elif dic[‘mark‘] == ‘-‘: return x - y elif dic[‘mark‘] == ‘*‘: return x * y else: return x / y def suansu(re_str): ret4 = re.search(r‘(?P<x>\d+\.?\d*)(?P<mark>[*/])(?P<y>[\-]?\d+\.?\d*)‘, re_str) try: while ret4.group(): re_str = re_str.replace(ret4.group(), str(math(ret4.groupdict()))) if ‘--‘ in re_str: re_str = re_str.replace(‘--‘, ‘+‘) if ‘++‘ in re_str: re_str = re_str.replace(‘++‘, ‘+‘) ret4 = re.search(r‘(?P<x>[\-]?\d+\.?\d*)(?P<mark>[*/])(?P<y>[\-]?\d+\.?\d*)‘, re_str) except AttributeError: pass ret4 = re.search(r‘(?P<x>[\-]?\d+\.?\d*)(?P<mark>[+\-])(?P<y>[\-]?\d+\.?\d*)‘, re_str) try: while ret4.group(): re_str = re_str.replace(ret4.group(), str(math(ret4.groupdict()))) ret4 = re.search(r‘(?P<x>[\-]?\d+\.?\d*)(?P<mark>[+\-])(?P<y>[\-]?\d+\.?\d*)‘, re_str) except AttributeError: return re_str def main(user_inp): while True: if not re.search(‘\([+*/\d.\-]*\)‘, user_inp): print(user_inp) return suansu(user_inp) else: for i in re.findall(‘\([+*/\d.\-]*\)‘, user_inp): user_inp = user_inp.replace(i, suansu(i.replace(‘(‘, ‘‘).replace(‘)‘, ‘‘))) while True: print(main(‘0+‘+input(‘>>>‘).replace(" ", "")))
Python全栈之路系列----之-----re模块(正则表达式)
标签:起名字 and 区分大小写 独立 分组 oldboy inf zab mil
原文地址:http://www.cnblogs.com/zgd1234/p/7506044.html
