标签:输出 from xxx 服务 英语 赋值 优化 解释器 logs
一、Python前世今生
python的创始人为吉多·范罗苏姆(Guido van Rossum)。1989年的圣诞节期间,吉多·范罗苏姆为了在阿姆斯特丹打发时间,决心开发一个新的脚本解释程序,作为ABC语言的一种继承。
最新的TIOBE排行榜,Python赶超PHP占据第五!!!
Python可以应用于众多领域,如:数据分析、组件集成、网络服务、图像处理、数值计算和科学计算等众多领域。目前业内几乎所有大中型互联网企业都在使用Python,如:Youtube、Dropbox、BT、Quora(中国知乎)、豆瓣、知乎、Google、Yahoo!、Facebook、NASA、百度、腾讯、汽车之家、美团等。互联网公司广泛使用Python来做的事一般有:自动化运维、自动化测试、大数据分析、爬虫、Web 等。
注视:上述重点字体表示该公司主
Python的种类
要使用Python语言开发
第一句Python代码
在 /home/dev/ 目录下创建 hello.py 文件,内容如下:
print "hello,world"
python内部执行过程如下:
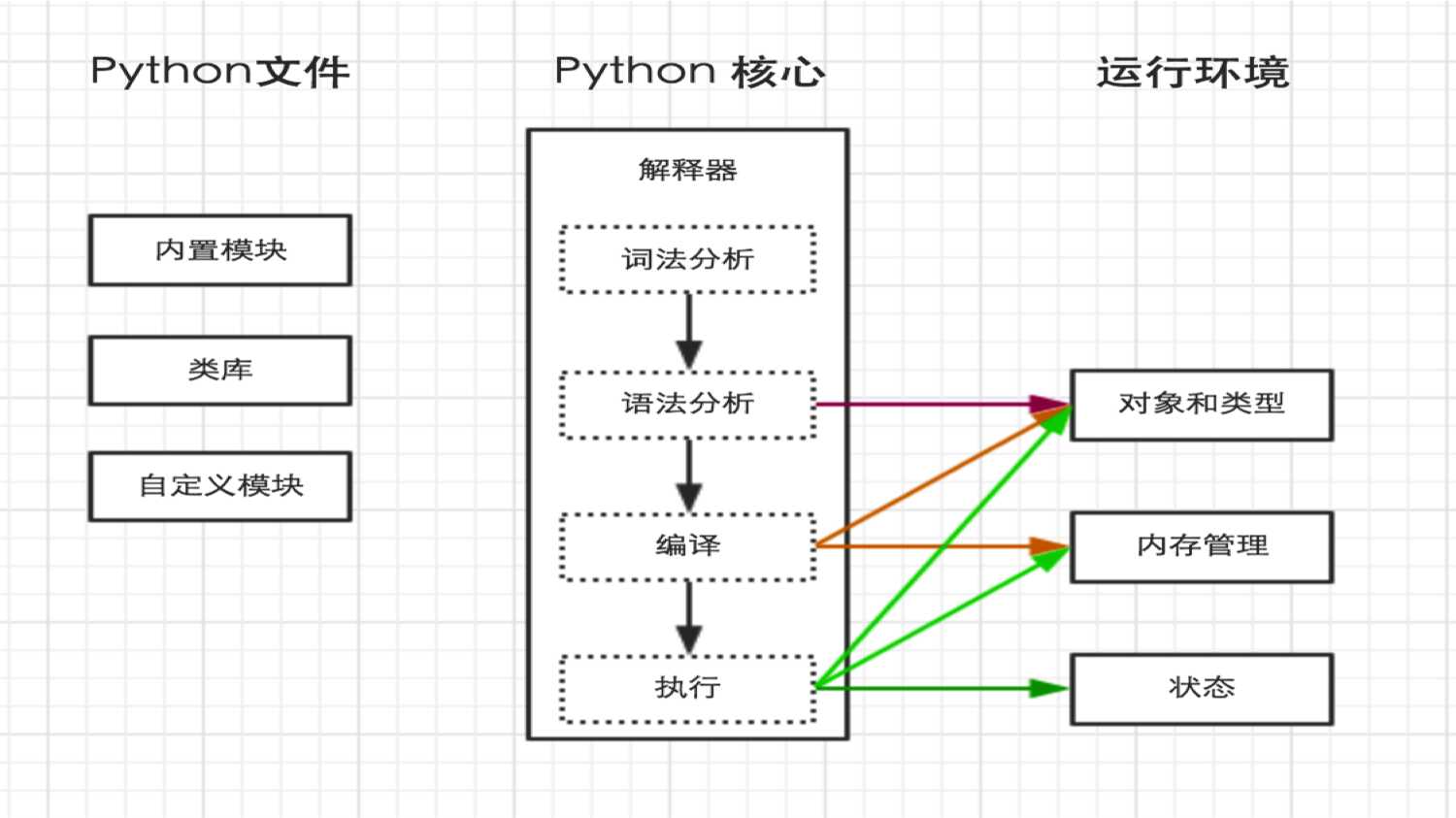
二、解释器
上一步中执行 python /home/dev/hello.py 时,明确的指出 hello.py 脚本由 python 解释器来执行。
如果想要类似于执行shell脚本一样执行python脚本,例: ./hello.py ,那么就需要在 hello.py 文件的头部指定解释器,如下:
#!/usr/bin/env python print "hello,world"
三、内容编码
python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill)
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号。
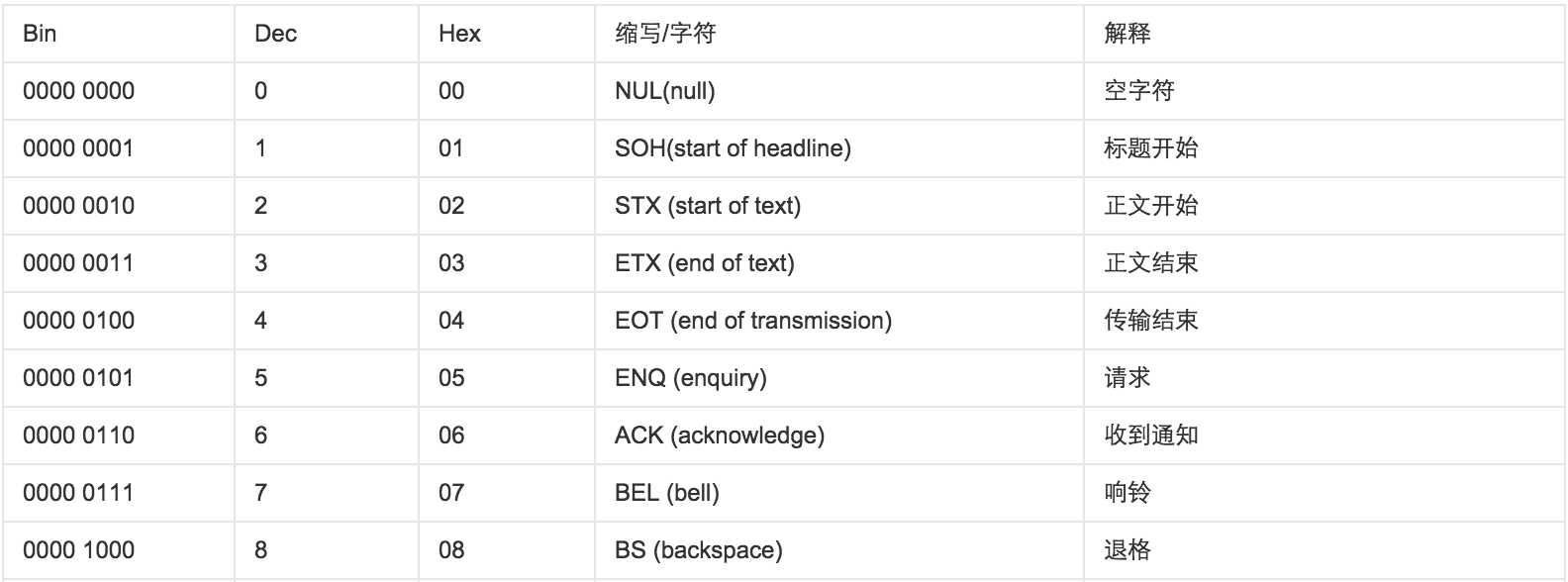
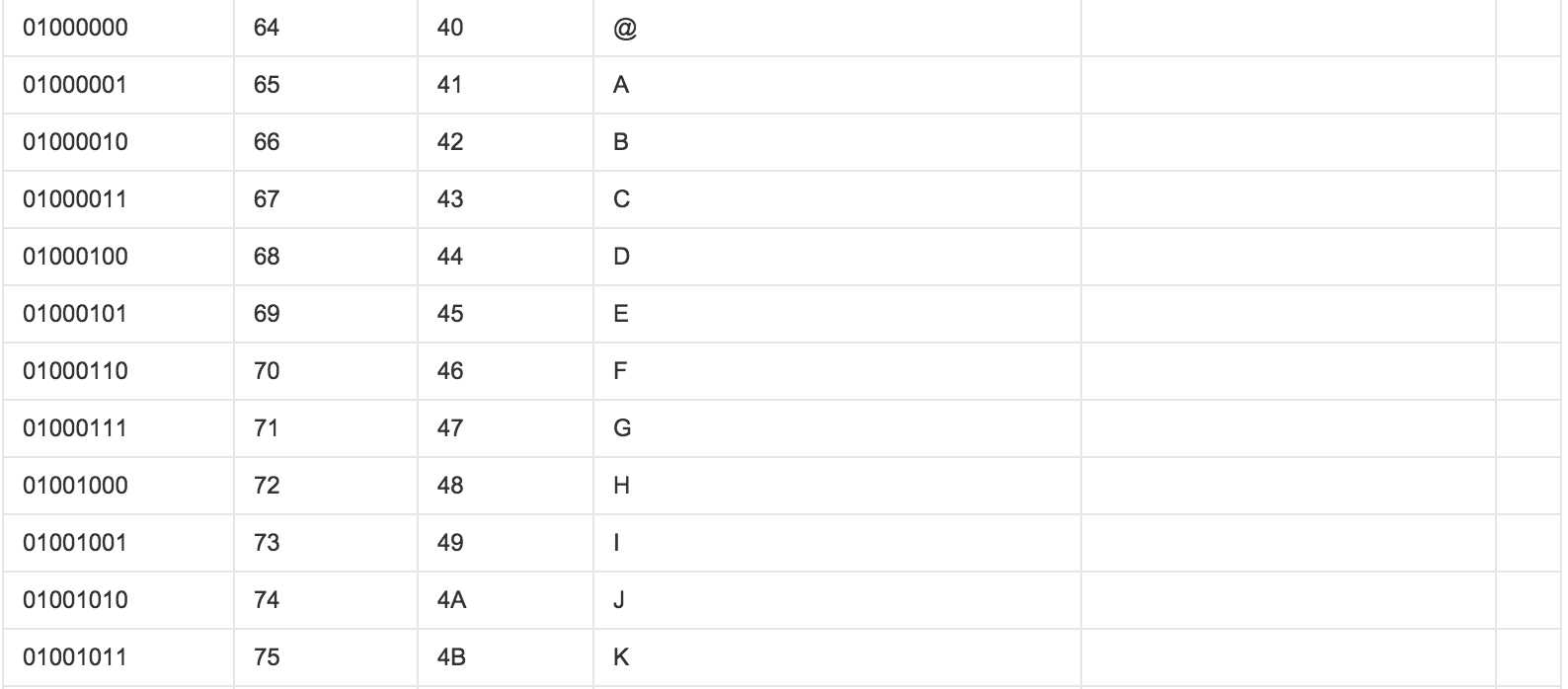
显然ASCII码无法将世界上的各种文字和符号全部表示,所以,就需要新出一种可以代表所有字符和符号的编码,即:Unicode
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536,
注:此处说的的是最少2个字节,可能更多
UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存...
所以,python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill),如果是如下代码的话:
报错:ascii码无法表示中文
#!/usr/bin/env python print "你好,世界"
改正:应该显示的告诉python解释器,用什么编码来执行源代码,即:
#!/usr/bin/env python # -*- coding: utf-8 -*- print "你好,世界"
如此一来,执行: ./hello.py 即可。
ps:执行前需给予 hello.py 执行权限,chmod 755 hello.py
四、注释
当行注视:# 被注释内容
多行注释:""" 被注释内容 """
五、执行脚本传入参数
Python有大量的模块,从而使得开发Python程序非常简洁。类库有包括三中:
Python内部提供一个 sys 的模块,其中的 sys.argv 用来捕获执行执行python脚本时传入的参数
#!/usr/bin/env python # -*- coding: utf-8 -*- import sys print sys.argv
六、 pyc 文件
执行Python代码时,如果导入了其他的 .py 文件,那么,执行过程中会自动生成一个与其同名的 .pyc 文件,该文件就是Python解释器编译之后产生的字节码。
ps:代码经过编译可以产生字节码;字节码通过反编译也可以得到代码。
七、变量
1、声明变量
#!/usr/bin/env python # -*- coding: utf-8 -*- name = "wupeiqi"
上述代码声明了一个变量,变量名为: name,变量name的值为:"wupeiqi"
变量的作用:昵称,其代指内存里某个地址中保存的内容
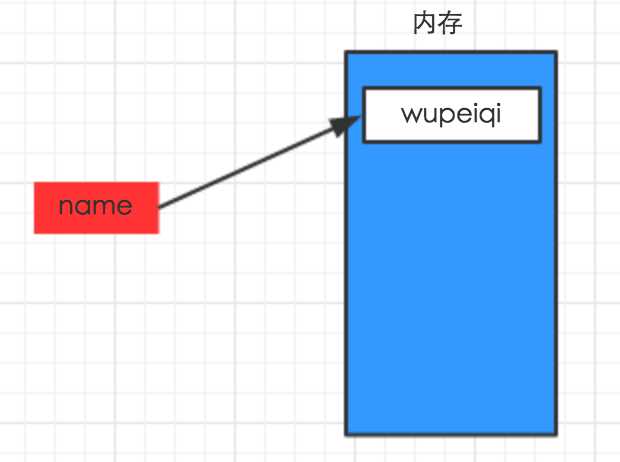
变量定义的规则:
2、变量的赋值
#!/usr/bin/env python # -*- coding: utf-8 -*- name1 = "wupeiqi" name2 = "alex"
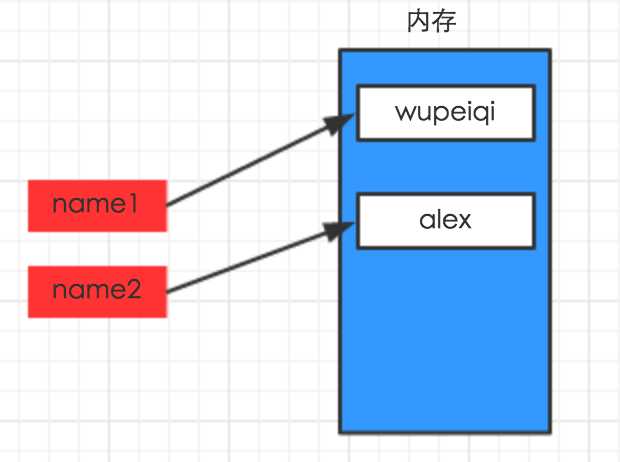
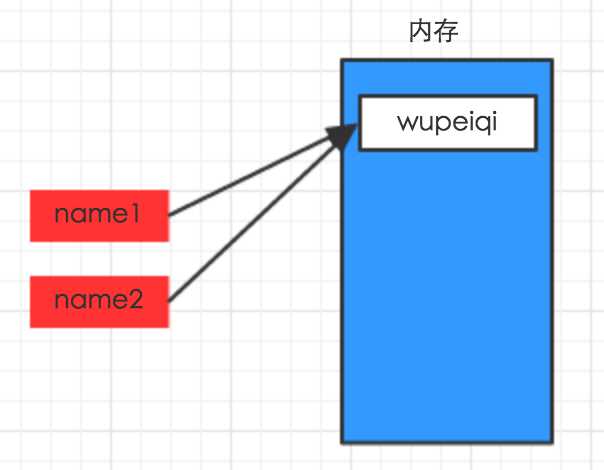
#!/usr/bin/env python # -*- coding: utf-8 -*- name1 = "wupeiqi" name2 = name1
#!/usr/bin/env python # -*- coding: utf-8 -*- # 将用户输入的内容赋值给 name 变量 name = raw_input("请输入用户名:") # 打印输入的内容 print name
输入密码时,如果想要不可见,需要利用getpass 模块中的 getpass方法,即:
#!/usr/bin/env python # -*- coding: utf-8 -*- import getpass # 将用户输入的内容赋值给 name 变量 pwd = getpass.getpass("请输入密码:") # 打印输入的内容 print pwd
九、流程控制和缩进
需求一、用户登陆验证
#!/usr/bin/env python # -*- coding: encoding -*- # 提示输入用户名和密码 # 验证用户名和密码 # 如果错误,则输出用户名或密码错误 # 如果成功,则输出 欢迎,XXX! import getpass name = raw_input(‘请输入用户名:‘) pwd = getpass.getpass(‘请输入密码:‘) if name == "alex" and pwd == "cmd": print "欢迎,alex!" else: print "用户名和密码错误"
需求二、根据用户输入内容输出其权限
# 根据用户输入内容打印其权限 # alex --> 超级管理员 # eric --> 普通管理员 # tony,rain --> 业务主管 # 其他 --> 普通用户
name = raw_input(‘请输入用户名:‘) if name == "alex": print "超级管理员" elif name == "eric": print "普通管理员" elif name == "tony" or name == "rain": print "业务主管" else: print "普通用户"
十、while循环
1、基本循环
while 条件: # 循环体 # 如果条件为真,那么循环体则执行 # 如果条件为假,那么循环体不执行
2、break
break用于退出所有循环
while True: print "123" break print "456"
3、continue
continue用于退出当前循环,继续下一次循环
while True: print "123" continue print "456"
作业1、使用while循环输入 1 2 3 4 5 6 8 9 10
2、求1-100的所有数的和
3、输出 1-100 内的所有奇数
4、输出 1-100 内的所有偶数
5、求1-2+3-4+5 ... 99的所有数的和
6、用户登陆(三次机会重试)
标签:输出 from xxx 服务 英语 赋值 优化 解释器 logs
原文地址:http://www.cnblogs.com/cmpunk/p/7520208.html