标签:tail 方式 logs 技术分享 ace .net 不能 src ima
普通的字符串在py2.7中都是以ASCII编码的,例如str=“abc”,若含有中文则会以gbk或者gb2312编码(GB2312是中国规定的汉字编码,也可以说是简体中文的字符集编码;GBK 是 GB2312的扩展 ,除了兼容GB2312外,它还能显示繁体中文,还有日文的假名)
但在字符串前加u,例如str=u“abc”,则可以将字符串定义成Unicode编码
系统自带的编码查看可通过 sys.getdefaultencoding() 获得,若要修改默认编码需要先 reload(sys) ,因为初始化后会删除 sys.setdefaultencoding 这个方法,我们需要重新载入,之后使用 sys.setdefaultencoding(‘utf-8‘) 即可修改
编辑py文件时在头部加上# -*- coding: utf-8 -*- 可以使这个py文件以utf-8编码,里面可以包含中文
decode的作用是将其他编码的字符串转换成unicode编码,如str1.decode(‘gb2312‘),表示将gb2312编码的字符串转换成unicode编码
encode的作用是将unicode编码转换成其他编码的字符串,如str2.encode(‘gb2312‘),表示将unicode编码的字符串转换成gb2312编码,
若原字符串不是unicode编码而直接encode,则以系统默认编码进行解码,再encode,即 str2.encode(‘gb2312‘) == str2.decode(sys.getdefaultencoding()).encode(‘gb2312‘)
如果是在utf-8的文件中,字符串就是utf-8编码,如果是在gb2312的文件中,则其编码为gb2312。这种情况下,要进行编码转换,都需要先用 decode方法将其转换成unicode编码,再使用encode方法将其转换成其他编码。通常,在没有指定特定的编码方式时,都是使用的系统默认编码创建的代码文件。
isinstance(str,unicode)可以判断一个字符串是否为unicode编码,是则返回True,不是返回False
如果直接解码一些包含特殊字符的编码,可能会抛出异常,可以用以下方法解决:
s.decode("utf-8", "ignore") 忽略其中有异常的编码,仅显示有效的编码
s.decode("utf-8", "replace") 替换其中异常的编码,这个相对来可能一眼就知道那些字符编码出问题了,但是会把原来的编码搞乱,多用于测试,不是很实用
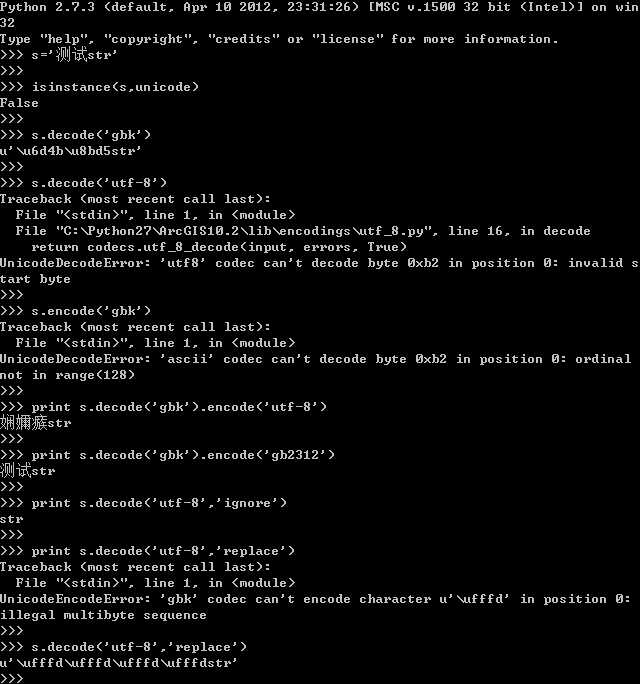
可以看到把gbk编码解码后要正确显示中文不能用utf-8来encode,还是只能用gbk或gbk2312,推测打开一些 txt 或 word 时的乱码应该就是把gbk的编码用utf-8显示了
各种编码常见编码参考:http://blog.csdn.net/shijing_0214/article/details/50908144
Python-2.7 : 编码问题及encode与decode
标签:tail 方式 logs 技术分享 ace .net 不能 src ima
原文地址:http://www.cnblogs.com/tccbj/p/7527211.html