标签:原因 使用 显示 inter 一个 next 平均值 成员类 contract
本篇文章讲解数组的使用,先是介绍下几种不同的数组,在说明下各自的区别和使用场景,然后注意细节,废话不多说,赶紧上代码。
在.Net 3.5之中,我们常用的数组基本就是如下的几种方式(词典Dictionary<TKey,TValue>比较特殊,下面单独解释):
ArrayList:
简单的说,ArrayList是一个微软早期提供的数组类型,在那个时代还没有泛型的时候,我们需要一个可变数组的时候,就会采用这个数组,现在来说,已经很少使用了,不排除有些场景特别适用这个数组,如果要说这个数组的优点,恐怕只有一个,还是最大的一个优点就是对数组成员类型不确定,所以我们可以这么写代码:
1 private void button1_Click(object sender, EventArgs e) 2 { 3 ArrayList arrayList = new ArrayList(); 4 arrayList.Add(false); 5 arrayList.Add(5); 6 arrayList.Add(5.3); 7 arrayList.Add("测试数据"); 8 arrayList.Add(Guid.NewGuid()); 9 arrayList.Add(DateTime.Now); 10 11 12 foreach(var m in arrayList) 13 { 14 textBox1.AppendText(m.GetType().ToString() + Environment.NewLine); 15 } 16 17 }
显示结果为:
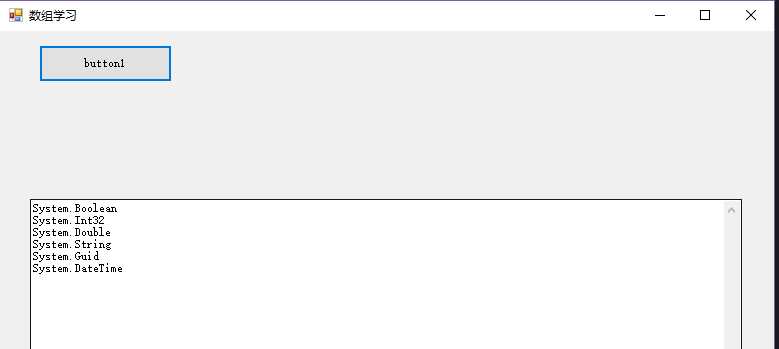
这种方式和我们的一般思维不太一样,我们一般定义一组数据时,肯定是一样的类型的呀,如果按照ArrayList类型来看,我们每次调用中间一个成员的时候,还得判断下什么类型,因为它很可能不是简单的Object,如果我们在代码中都是Add同一种类型,那么是否就意味着使用的时候不需要进行类型判定了吗?肯定不行,因为你一旦在代码的其他地方使用了Add方法,并添加了一个不是你期望的类型对象(编译器根本不会提示错误),这会对以后你查找问题产生极大的阻碍。
这种数组还有巨大的缺陷。就是频繁的拆箱装箱,如果只有100长度以内的数据,对性能的损耗也许会看不出来,但是数组长度达上万的时候,绝对会成为性能的瓶颈,关于拆箱装箱的描述,在其他很多的书上都会有描述,如果需要说清楚,又得回到区分值类型和引用类型的区别,又会扯出线程栈和托管堆的区别,暂时就不深入了。所以基本不选择这个数组。
T[] 数组
这是一个最常用的数组类型了,其实这种数组非常的好用和扩展功能,我们非常习惯于下面的定义方式:
1 private void button2_Click(object sender, EventArgs e) 2 { 3 int[] temp = new int[100]; 4 Button[] buttones = new Button[100]; 5 6 // 正常访问 7 foreach (var m in temp) 8 { 9 textBox1.AppendText(m.ToString() + Environment.NewLine); 10 } 11 12 // 异常,抛出NullReferenceException 13 foreach (var m in buttones) 14 { 15 textBox1.AppendText(m.Text + Environment.NewLine); 16 } 17 18 }
在上述的例子中,存在一个细微的差别,如果你定义的是非空的值类型数据,会自动的赋初值,也即是default(int),也即是0,而引用类型的初值是NULL,但无论怎么说,buttones确实一个长度为100的数组,只是里面的数据都为空罢了,所以我们可以这么写:
1 Button[] buttones = new Button[100]; 2 buttones[99] = new Button();
这样我们只实例化数组的最后一个对象。
List<T> 数组对象
这个数组对象厉害了,这个数组自从C#引入了泛型以来就立即被广泛引用,它继承了ArrayList的优良传统,又解决掉了ArrayList留下来的所有弊端,基本上可以说一劳永逸了,它甚至更强大的是带来了Lambada表达式,这真是一个巨大的进步,下面就来详细的介绍下C#中大名鼎鼎的List<T>数组了,先从实例化开始好了,List<T>的数组实例化小个小细节,如果我们要实例化一个包含了100万个int的数组,应该怎做,和int[] 初始化有什么区别:
1 private void button3_Click(object sender, EventArgs e) 2 { 3 int[] list1 = new int[1000000]; 4 // 可以直接按下面这么用 5 list1[10000] = 10; 6 7 List<int> list = new List<int>(1000000); 8 // 下面的代码会引发异常ArgumentOutOfRangeException 9 list[10000] = 10; 10 }
如下两种方式实例化一个长度1000000个0的List<int>实例:
1 private void button5_Click(object sender, EventArgs e) 2 { 3 // 方式一 4 List<int> list1 = new List<int>(); 5 for(int i=0;i<1000000;i++) 6 { 7 list1.Add(0); 8 } 9 10 // 方式二 11 List<int> list2 = new List<int>(new int[1000000]); 12 }
以下展示一个Lambada表达式的巨大好处,假设有个List<int>数组,包含了10000个数据,我们需要筛选出里面所有大于100的数据并重新生成一个数组,以下展示2中写法,你就能明白中间的区别在哪里了
1 private void button6_Click(object sender, EventArgs e) 2 { 3 // 生成一万个随机数据(0-200)的数组 4 List<int> list = new List<int>(); 5 Random r = new Random(); 6 for(int i=0;i<10000;i++) 7 { 8 list.Add(r.Next(200)); 9 } 10 11 // 方式一 12 List<int> result1 = new List<int>(); 13 for (int i = 0; i < list.Count; i++) 14 { 15 if (list[i] > 100) 16 { 17 result1.Add(list[i]); 18 } 19 } 20 21 // 方式二 22 List<int> result2 = list.Where(m => m > 100).ToList(); 23 }
无论从代码的工作量上来说还是理解度来说,都是第二种方式完胜,而且两者的性能相差无几,所以极度推荐大家学好委托和Lambada表达式。
讲完了List<T>类型的几种用法,来说说原理的东西,我刚学习并用了一段时间的List<T>后,就特别好奇微软怎么实现了List<T>对象,所谓的动态长度的数组原理是什么,为什么可以使用Add方法来新增Item,带着这些疑问,后来看到了微软开源出来的代码,List<T>的开源地址为http://referencesource.microsoft.com/#mscorlib/system/collections/generic/list.cs,2765070d40f47b98
源代码非常的长,这里就不全复制了,有兴趣的可以看看,上面有很多细节可以学习,我就大致讲一下List<T>的根本原理,有助于大家理解,首先List<T>内部使用的底层数据仍然是T[]类型的,并且声明了一个初始容量4,在执行了List<int> list = new List<int>(1000000)这段代码后,部分真的有一个 _items 为int[10000]的对象,但是我们为什么在使用list[10000]=10的时候异常了呢?因为里面还有个数据容量 _size,在初始化的时候并没有赋值;而当你使用list[10000]时,下面的代码足以说明问题:
1 // Sets or Gets the element at the given index. 2 // 3 public T this[int index] { 4 get { 5 // Following trick can reduce the range check by one 6 if ((uint) index >= (uint)_size) { 7 ThrowHelper.ThrowArgumentOutOfRangeException(); 8 } 9 Contract.EndContractBlock(); 10 return _items[index]; 11 } 12 13 set { 14 if ((uint) index >= (uint)_size) { 15 ThrowHelper.ThrowArgumentOutOfRangeException(); 16 } 17 Contract.EndContractBlock(); 18 _items[index] = value; 19 _version++; 20 } 21 }
源代码里还有细节值得注意,当我们调用了Add(1000)方法时,发生了什么事情,如下的源代码来源于微软
1 public void Add(T item) { 2 if (_size == _items.Length) EnsureCapacity(_size + 1); 3 _items[_size++] = item; 4 _version++; 5 } 6 private void EnsureCapacity(int min) { 7 if (_items.Length < min) { 8 int newCapacity = _items.Length == 0? _defaultCapacity : _items.Length * 2; 9 // Allow the list to grow to maximum possible capacity (~2G elements) before encountering overflow. 10 // Note that this check works even when _items.Length overflowed thanks to the (uint) cast 11 if ((uint)newCapacity > Array.MaxArrayLength) newCapacity = Array.MaxArrayLength; 12 if (newCapacity < min) newCapacity = min; 13 Capacity = newCapacity; 14 } 15 } 16 public int Capacity { 17 get { 18 Contract.Ensures(Contract.Result<int>() >= 0); 19 return _items.Length; 20 } 21 set { 22 if (value < _size) { 23 ThrowHelper.ThrowArgumentOutOfRangeException(ExceptionArgument.value, ExceptionResource.ArgumentOutOfRange_SmallCapacity); 24 } 25 Contract.EndContractBlock(); 26 27 if (value != _items.Length) { 28 if (value > 0) { 29 T[] newItems = new T[value]; 30 if (_size > 0) { 31 Array.Copy(_items, 0, newItems, 0, _size); 32 } 33 _items = newItems; 34 } 35 else { 36 _items = _emptyArray; 37 } 38 } 39 } 40 }
源代码中的两个方法加一个属性已经表示的很清楚了,假设list原来初始容量为4,我们刚好add了4个值,当我们add第五个值的时候,就会发生很多事情
所以这个操作还是非常恐怖的,假设这时候数组的长度已经100万了,再新增一个数据,将要生成200万长度的数据,再挪一百万长度的数据,虽然说挪一次的性能还是非常高的,这里为什么要按两倍扩充呢,估计也是为了性能考虑,假设你的list使用Add方法调用了100万次,实际只是扩充了19次(可能18次,没具体算),所以这么看下来如果确定数组的长度是固定的情况,使用 T[] 的性能最好。
Queue<T> 数组类型
这个数组对象和List<T>非常的像,在绝大多数情况下都可以用List<T>来替代实现,如下的代码演示了同时添加一个数据,和移除一个数据时的操作:
1 private void button7_Click(object sender, EventArgs e) 2 { 3 Queue<int> queue = new Queue<int>(); 4 List<int> list = new List<int>(); 5 6 // 两者等同 7 queue.Enqueue(1000); 8 list.Add(1000); 9 10 // 两者有一点微小的区别 11 int i = queue.Dequeue(); 12 int j = list[0]; 13 list.RemoveAt(0); 14 }
如果此处不需要获取被移除数据的数值的话,这里的代码就几乎等同了,所以这里适用的场景其实也很明显了,比如我们有一个消息队列,存放了消息对象,每个对象包含了发送人,发送时间,接收人,发送内容等等,来自各个地方的消息统一压入队列,专门由一个线程出处理这些消息,处理的模型就是拿一个处理一个,肯定是先发先处理了,这种情况就特别适合使用Queue<T>队列了。但是这时候又该考虑另一个问题了,那就是同步,在本篇下面将介绍。
Stack<T> 数组类型
不得不说,这个对象和List<T>, Queue<T> 都是非常的像,无非就是先入后出罢了,只要前两个理解了,这个就什么难度,至于实际中的应用场景,暂时还没想到,不过有一个技术真的超级适合先入后出的方式,就是指针,指针在执行到调用方法时,会将当前的位置压入堆栈,然后跳转到其他方法执行,执行完毕后,取出堆栈的值,跳到相应的地址继续执行。即使方法里再跳方法,方法里再跳方法,执行的步骤也不会乱。
使用注意:
ArrayList妙用:
如果你获取到一个数据Object 对象,但是知道它是一个数组,可能是bool[], 也可能是int[], double[], sting[]等等,现在要在表格中显示,就特别适合使用ArrayList类型
1 private void button8_Click(object sender, EventArgs e) 2 { 3 // 获取到的对象 4 Object obj = new object(); 5 6 if(obj is ArrayList list) 7 { 8 foreach(object m in list) 9 { 10 // 可以进行显示一些操作 11 } 12 } 13 }
排序性能:
有时候我们需要对一个数组进行排序,从小到大也好,从大到小也好,大学里教的都是冒泡法之类的,其实根本不要去使用,性能超差。
1 private void button9_Click(object sender, EventArgs e) 2 { 3 // 生成100000个数据长度的数组 4 int[] data = new int[100000]; 5 // 随机赋值 6 Random r = new Random(); 7 for (int i = 0; i < data.Length; i++) 8 { 9 data[i] = r.Next(1000000); 10 } 11 12 DateTime start = DateTime.Now; 13 14 // 开始排序 15 for (int i = 0; i < data.Length; i++) 16 { 17 for (int j = i + 1; j < data.Length; j++) 18 { 19 if (data[j] < data[i]) 20 { 21 int temp = data[j]; 22 data[j] = data[i]; 23 data[i] = temp; 24 } 25 } 26 } 27 28 textBox1.AppendText((DateTime.Now - start).TotalMilliseconds + Environment.NewLine); 29 30 // 重新赋值 31 for (int i = 0; i < data.Length; i++) 32 { 33 data[i] = r.Next(1000000); 34 } 35 36 start = DateTime.Now; 37 // 第二种从小到大的排序 38 Array.Sort(data); 39 40 textBox1.AppendText((DateTime.Now - start).TotalMilliseconds + Environment.NewLine); 41 ; 42 }
实际消耗的时间差别巨大,冒泡法居然用了整整34秒钟,而系统自带排序算法只用了15毫秒,整个时间竟然差了2200倍以上。
同步问题:
这个问题算是最难也是最容易出问题的地方,而且很多问题还出的莫名其妙,有时出问题,有时又不出,关键的是在于对多线程的理解错误,在绝大多数的单线程应用程序中,几乎没有同步问题,比如你在窗口类中定义了一个数组,在窗口类中其他地方可以随意的使用数组,更改值也好,取出数值也好,求取平均值也好。程序都可以很好的工作,但是对于多线程的应用程序,我们很容易想到这样的处理模型。
我们建一个缓存的中间对象,比如int[] temp=new int[100],然后有一个线程从其他对方获取数据,可能来自设备,可能来自数据库,网络等等,获取数据后,对数组进行更新数据,然后其他地方对数组数据进行处理,获取值进行显示,计算平均数显示等等,所以我们很容易这么写代码:
1 private int[] arrayData = new int[100]; // 缓存数组 2 System.Windows.Forms.Timer timer = null; // 定时器 3 private void button10_Click(object sender, EventArgs e) 4 { 5 // 开线程更新数据 6 Thread thread = new Thread(UpdateArray); 7 thread.IsBackground = true; 8 thread.Start(); 9 10 // 在主界面开定时器访问数组显示或计算等等 11 timer = new System.Windows.Forms.Timer(); 12 timer.Tick += Timer_Tick; 13 timer.Interval = 1000; // 每秒更新一次 14 timer.Start(); // 启动定时器 15 } 16 17 18 private void UpdateArray() 19 { 20 // 每隔200ms更新一次数据,先全部置1,然后全部置2 21 int jj = 1; 22 while (true) 23 { 24 Thread.Sleep(200); 25 for (int i = 0; i < arrayData.Length; i++) 26 { 27 arrayData[i] = jj; 28 } 29 jj++; 30 } 31 } 32 33 34 private void Timer_Tick(object sender, EventArgs e) 35 { 36 textBox1.Text = "总和:" + arrayData.Sum() + " 平均值:" + arrayData.Average(); 37 }
咋一看,没什么问题,然后运行调试,也没什么问题,就可以让它一直在现场跑程序,24小时不间断,然后突然有一天就挂了,抛出了异常,这个异常是新手经常忽略的地方,也比较难以找到。究其根本原因是,Sum()和Average()操作是需要对数组进行迭代的,而在迭代操作的同时是不允许更改数组的,那我们可以绕过迭代吗?,答案当然是可以的:
1 private void Timer_Tick(object sender, EventArgs e) 2 { 3 textBox1.Text = "总和:" + SumArrayData() + " 平均值:" + AverageArrayData(); 4 } 5 6 private int SumArrayData() 7 { 8 int sum = 0; 9 for (int i = 0; i < arrayData.Length; i++) 10 { 11 sum += arrayData[i]; 12 } 13 return sum; 14 } 15 16 private double AverageArrayData() 17 { 18 int sum = SumArrayData(); 19 return sum * 1.0 / arrayData.Length; 20 }
将需要迭代的代码改用for循环来获取计算,这样就不会发生异常了,即时24运行程序,也不会抛出异常,但是回过头来思考,为什么迭代会抛出异常?
为了数据安全!
假设我们需要计算总和,我们需要将数组的项目一个个相加,当我加到一半的时候,更改了数据,然后我们相加得到的总和中就会有一半的数据是旧的,另一半的数据是新的,最终获取到的数据就不是一次正常的数据,如果你的程序仅仅用来显示,那么问题不大,如果用来处理一些重要的逻辑业务,那么问题就大了,会直接带来安全漏洞。带来数据的不准确,以至于后面根据该数据做出的决策全部都错误,比如说根据平均值进行报警,操作设备。所以进行迭代操作抛出异常是合情合理的。
这是一个多么值得深思的问题,这个问题不仅仅是针对T[] 数组类型的,还针对了上述所有的数组类型,因为他们都不是线程安全的。
所以,但凡碰到一个数组需要进行多线程操作的时候,必然加锁,来进行线程间的同步问题,一般我们比较能想到的就是lock语法糖,更高级的锁我们以后的文章再提及,所以上述的代码,我们可以将数组改造成线程安全的方式:
1 private int[] arrayData = new int[100]; // 缓存数组 2 System.Windows.Forms.Timer timer = null; // 定时器 3 private object lock_array = new object(); // 添加的锁 4 private void button10_Click(object sender, EventArgs e) 5 { 6 // 开线程更新数据 7 Thread thread = new Thread(UpdateArray); 8 thread.IsBackground = true; 9 thread.Start(); 10 11 // 在主界面开定时器访问数组显示或计算等等 12 timer = new System.Windows.Forms.Timer(); 13 timer.Tick += Timer_Tick; 14 timer.Interval = 1000; // 每秒更新一次 15 timer.Start(); // 启动定时器 16 } 17 18 19 private void UpdateArray() 20 { 21 // 每隔200ms更新一次数据,先全部置1,然后全部置2 22 int jj = 1; 23 while (true) 24 { 25 Thread.Sleep(200); 26 lock (lock_array) 27 { 28 for (int i = 0; i < arrayData.Length; i++) 29 { 30 arrayData[i] = jj; 31 } 32 jj++; 33 } 34 } 35 } 36 37 38 private void Timer_Tick(object sender, EventArgs e) 39 { 40 textBox1.Text = "总和:" + SumArrayData() + " 平均值:" + AverageArrayData(); 41 } 42 43 private int SumArrayData() 44 { 45 lock (lock_array) 46 { 47 return arrayData.Sum(); 48 } 49 } 50 51 private double AverageArrayData() 52 { 53 lock (lock_array) 54 { 55 return arrayData.Average(); 56 } 57 }
如果你定义的数组多了,锁多了,就显得代码比较乱,可以将数组,锁,和数组提供的访问接口提炼成一个安全的数组类,这样的话你的代码也会变得好看很多,自己的能力也上去了。如果你只是对一个单线程的数组进行操作,那么可以随意的进行迭代。
微软在.Net 4.X中提供了上述数组的线程安全版本,当然,我们在.Net 3.5中也是可以自己扩充实现的,有兴趣的小伙伴可以去尝试尝试。
Dictionary<TKey,TValue> 类型数据
怎么说呢,总感觉词典类型和数组很相似,都可以用来存储一组数据,当然里面的存储机制肯定完全不一致。它和数组最大的区别在于,词典不是基于索引访问的,不存在你直接访问第100个数据,然后MoveNext访问,(不过词典仍然支持迭代遍历),而数组基本支持索引访问的(先入先出和后入先出只支持头尾访问),所以词典的使用场景就是针对不是索引访问的情况,而是根据唯一的键来访问的,故名思议,词典是最适合的,比如我们需要有一堆的文本,“Find”, "AAAA", "BBBB"之类,每个数据关联了一个对象,那我们想要快速直达对象最好的方式就是词典了。
这么点东西一个晚上居然还没写好。。。。。下次想到再补充吧。
标签:原因 使用 显示 inter 一个 next 平均值 成员类 contract
原文地址:http://www.cnblogs.com/dathlin/p/7528930.html