标签:可变 符号 消失 nbsp strong 美国 传输 class 语言
一、字符编码的分类:
计算机由美国人发明,最早的字符编码为ASCII,只规定了英文字母数字和一些特殊字符与数字的对应关系。最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号
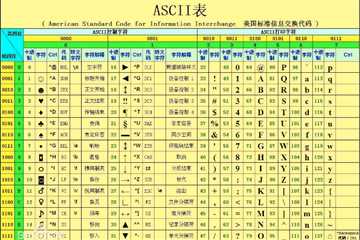
当然我们编程语言都用英文没问题,ASCII够用,但是在处理数据时,不同的国家有不同的语言,日本人会在自己的程序中加入日文,中国人会加入中文。
而要表示中文,单拿一个字节表表示一个汉子,是不可能表达完的(连小学生都认识两千多个汉字),解决方法只有一个,就是一个字节用>8位2进制代表,位数越多,代表的变化就多,这样,就可以尽可能多的表达出不通的汉字
所以中国人规定了自己的标准gb2312编码,规定了包含中文在内的字符->数字的对应关系。
日本人规定了自己的Shift_JIS编码
韩国人规定了自己的Euc-kr编码(另外,韩国人说,计算机是他们发明的,要求世界统一用韩国编码)
这时候问题出现了,精通18国语言的小周同学谦虚的用8国语言写了一篇文档,那么这篇文档,按照哪国的标准,都会出现乱码(因为此刻的各种标准都只是规定了自己国家的文字在内的字符跟数字的对应关系,如果单纯采用一种国家的编码格式,那么其余国家语言的文字在解析时就会出现乱码)
所以迫切需要一个世界的标准(能包含全世界的语言)于是unicode应运而生(韩国人表示不服,然后没有什么卵用)
ascii用1个字节(8位二进制)代表一个字符
unicode常用2个字节(16位二进制)代表一个字符,生僻字需要用4个字节
例:
字母x,用ascii表示是十进制的120,二进制0111 1000
汉字中已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。
字母x,用unicode表示二进制0000 0000 0111 1000,所以unicode兼容ascii,也兼容万国,是世界的标准
这时候乱码问题消失了,所有的文档我们都使用但是新问题出现了,如果我们的文档通篇都是英文,你用unicode会比ascii耗费多一倍的空间,在存储和传输上十分的低效
本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
| 字符 | ASCII | Unicode | UTF-8 |
|---|---|---|---|
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | x | 01001110 00101101 | 11100100 10111000 10101101 |
从上面的表格还可以发现,UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
标签:可变 符号 消失 nbsp strong 美国 传输 class 语言
原文地址:http://www.cnblogs.com/MouseCat/p/7530794.html