标签:编写 efault vector remove arrays 索引 技术 each 技术分享
使用接口类型存放集合的引用
如果需要实现自己的集合类,可以扩展一组以Abstract开头的类,扩展这些类比实现接口中所有方法轻松的多。
两个基本方法
public interface Collection<E>
{
boolean add(E element);
Iterator<E> iterator();
...
}public interface Iterator<E>{
E next();
boolean hasNext();
void remove();
default void forEachRemaining(Conseumer<? super E> action);
}有序集合,访问方式:迭代器和整数索引
数组的有序集合可以快速随机访问,链表随机访问很慢,最好使用迭代器遍历
集:add方法不允许增加重复的元素
集的equals方法需要保证两个集包含相同的元素就认为是相等的,不要求顺序.
hashcode()方法也要保证拥有相同元素的两个集得到相同的散列码.
会提供用于排序的比较器对象,定义了可以得到集合子集视图的方法
同上.
包含一些用于搜索和遍历有序集和映射的方法.
同上.
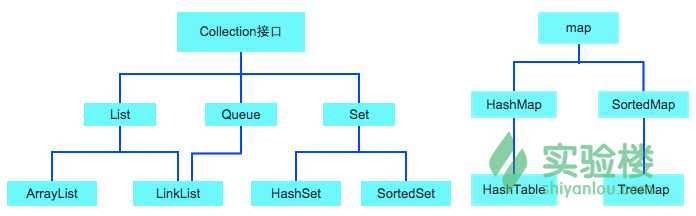
除了以Map结尾的类都实现了Collection接口,Map结尾的类实现了Map接口
| 集合类型 | 描述 |
|---|---|
| arrayList | 动态增长和缩减的索引序列 |
| Linkedlist | 在任意位置高效插入和删除的有序序列 |
| ArrayDeque | 循环数组实现的双端队列 |
| HashSet | 没有重复元素的无序集合 |
| TreeSet | 有序集 |
| EnumSet | 包含枚举类型的集 |
| LinkedHashSet | 记住元素插入顺序的集 |
| PriorityQueue | 允许高效删除最小元素的集合 |
| HashMap | 存储键值对的数据结构 |
| TreeMap | 键值有序排列的映射表 |
| EnumMap | 键值属于枚举类型的映射表 |
| Lindedhashmap | 记住键值项8添加次序的映射表 |
| weakHashMap | 其值无用武之地后被回收的映射表 |
| identityHashMap | 用==而不是equals比较键值的映射表 |
linkedList.add()将元素添加到链表尾部.
contains()方法检测元素是否存在于链表中.
get(n)返回第n个元素.效率不高不建议使用.
索引大于n/2时从尾端开始搜索
依赖位置的add方法由迭代器负责.iterator的子接口ListIterator包含add方法和prevous和hasprevious方法用于反向遍历链表.
add方法依赖于迭代器的位置.remove方法依赖于迭代器的状态,不能多次调用remove方法.
nextIndex和previousIndex返回下一次调用next返回元素的整数索引,pre返回下一次previous返回元素的整数索引,效率很高因为迭代器保持着当前位置的计数值
数组列表,实现了动态再分配的对象动态数组,实现了list接口
与vector对比,vector所有方法都是同步的,可以多线程安全访问一个vector对象,但是如果只有一个线程访问,代码需要在同步操作上耗费大量时间.而arraylist不是同步的
建议不需要同步是用arraylist,需要同步时使用vector
散列表为每一个对象计算一个整数,称为散列码(hashcode).
java中散列表用链表数组实现,每个列表称为桶,要查找表中对象的位置,先计算散列码然后与桶数取余就是保存这个元素的桶的索引
桶被占满的情况称为散列冲突,需要新对象与桶中所有对象进行比较查看是否已经存在.
java se8中桶满时会从链表变为平衡二叉树,选择的散列函数不当会产生很多冲突,或者有恶意代码试图在散列表中填充多个相同散列码的值,这样可以提高性能.
有人认为最好将桶数设置为素数,防止键的集聚.标准库使用的桶数是2的幂,默认值为16,为表大小提供的值会自动转换为下一个2的幂.
装填因子,默认0.75.表中超过装填因子的位置已经填入元素则会以双倍的桶数进行再散列.
树集是一个有序集合,任意顺序插入后,遍历时都是自动按照排序后的顺序呈现.
排序使用树结构完成,当前是红黑树.
将元素添加到树中会比添加到散列表慢,但是会比检查重复的数组和链表快很多.树中包含n个元素,插入元素大概要比较log 2 n次
java se 6 开始 treeSet实现了NavigabnleSet接口 增加了定位元素以及反向遍历的方法
scores.forEach((k,v)->System.out.println("key="+k+"value="+v));集合框架不认为映射是一种集合,但是可以获得键,值,键值对的集合.
set接口扩展了collection接口所以可以像使用集合一样使用keyset
weakhashMap:由于映射一直活动导致垃圾回收器无法回收已经没有引用的值,所以需要程序自身对其进行回收,所以设计了weakHashMap.
LinkedHashSet和LinkedHashmap记住插入元素项的顺序.
EnumSet是枚举类型元素集的高效实现
EnumMap是键类型为枚举类型的映射,直接且高效的使用值数组实现,使用时,需在构造器中指定键类型
IdentityHashMap
泛型集合接口的很大一个优点就是,算法只需要实现一次.
如
public static <T extens Comparable> T Max (Collection<T> c){
...
}就可任意使用一个方法计算链表,数组列表或数组中的最大元素了.
java中的排序将列表所有元素转入数组,然后对数组排序再将排序后的序列复制回列表
集合框架使用的排序算法为归并排序,慢于快排但是稳定,不需要交换相同值对象.
collections类提供了复制列表到另一个,常量值填充容器,逆置列表的元素排序,获取最大等简单的算法.调用这些方法有益于代码可读性.
数组转为集合
string [] values=...;
HashSet<String> staff=new HashSet<>(Arrays.asList(values));从集合得到数组
object[] values=staff.toArray();这样获得是对象数组
想获得字符串数组需要
string[] values = staff.toArray(new String[0]);最好使用接口而不是具体的实现
标签:编写 efault vector remove arrays 索引 技术 each 技术分享
原文地址:http://www.cnblogs.com/renluxiang/p/cf407b85b5c9dc5f0f30fc0a1a9db1f6.html