标签:timeout 通过 efs 工作原理 针对 过程 路由 停止 instance
前面大家介绍了主从、主主复制以及他们的中间件mysql-proxy的使用,这一篇给大家介绍的是keepalived的搭建与使用!
Keepalived起初是为LVS设计的,专门用来监控集群系统中各个服务节点的状态,它根据TCP/IP参考模型的第三、第四层、第五层交换机制检测每个服务节点的状态,如果某个服务器节点出现异常,
或者工作出现故障,Keepalived将检测到,并将出现的故障的服务器节点从集群系统中剔除,这些工作全部是自动完成的,不需要人工干涉,需要人工完成的只是修复出现故障的服务节点。
后来Keepalived又加入了VRRP的功能,VRRP(Vritrual Router Redundancy Protocol,虚拟路由冗余协议)出现的目的是解决静态路由出现的单点故障问题,通过VRRP可以实现网络不间断稳定运行,
因此Keepalvied 一方面具有服务器状态检测和故障隔离功能,另外一方面也有HA cluster功能,下面介绍一下VRRP协议实现的过程。
在现实的网络环境中。主机之间的通信都是通过配置静态路由或者(默认网关)来完成的,而主机之间的路由器一旦发生故障,通信就会失效,因此这种通信模式当中,路由器就成了一个单点瓶颈,为了解决这个问题,就引入了VRRP协议。
熟悉网络的学员对VRRP协议应该不陌生,它是一种主备模式的协议,通过VRRP可以在网络发生故障时透明的进行设备切换而不影响主机之间的数据通信,这其中涉及到两个概念:物理路由器和虚拟路由器。
VRRP可以将两台或者多台物理路由器设备虚拟成一个虚拟路由,这个虚拟路由器通过虚拟IP(一个或者多个)对外提供服务,而在虚拟路由器内部十多个物理路由器协同工作,同一时间只有一台物理路由器对外提供服务,
这台物理路由设备被成为:主路由器(Master角色),一般情况下Master是由选举算法产生,它拥有对外服务的虚拟IP,提供各种网络功能,如:ARP请求,ICMP 数据转发等,而且其它的物理路由器不拥有对外的虚拟IP,
也不提供对外网络功能,仅仅接收MASTER的VRRP状态通告信息,这些路由器被统称为“BACKUP的角色”,当主路由器失败时,处于BACKUP角色的备份路由器将重新进行选举,
产生一个新的主路由器进入MASTER角色,继续提供对外服务,整个切换对用户来说是完全透明的。
每个虚拟路由器都有一个唯一的标识号,称为VRID,一个VRID与一组IP地址构成一个虚拟路由器,在VRRP协议中,所有的报文都是通过IP多播方式发送的,而在一个虚拟路由器中,
只有处于Master角色的路由器会一直发送VRRP数据包,处于BACKUP角色的路由器只会接受Master角色发送过来的报文信息,用来监控Master运行状态,一一般不会发生BACKUP抢占的情况,除非它的优先级更高,
而当MASTER不可用时,BACKUP也就无法收到Master发过来的信息,于是就认定Master出现故障,接着多台BAKCUP就会进行选举,优先级最高的BACKUP将称为新的MASTER,这种选举角色切换非常之快,因而保证了服务的持续可用性。
在一个VRRP虚拟路由器中,有多态物理的VRRP路由器,但是这多台物理的及其并不同时工作,而是有一台成为Master的负责路由工作,其他都是Backup,master并非一成不变vrrp协议让每个vrrp路由参与竞选,最终获称的就是master。
Master有一些特权,比如拥有虚拟路由器的ip地址,我们的主机就是通过这个ip地址作为静态路由的,拥有特权的master要负责转发发送给网关地址的包和响应app的请求
简单的说:Mysql 主主复制 ,主节点自动切换。利用 keepalived 软件 监控主节点状态,当主节点崩溃,立刻热切换主节点备份节点从而得到高可用性。
双机热备是指两台机器都在运行,但并不是两台机器都同时在提供服务。当提供服务的一台出现故障的时候,另外一台会马上自动接管并且提供服务,而且切换的时间非常短。
1)在心跳失效的时候,就容易发生了脑裂(split-brain)。
2)( 一种常见的脑裂情况可以描述如下)比如正常情况下,(集群中的)NodeA 和 NodeB 会通过心跳检测以确认对方存在,在通过心跳检测确认不到对方存在时,就接管对应的(共享) resource 。
如果突然间,NodeA 和 NodeB 之间的心跳不存在了(如网络断开),而 NodeA 和 NodeB 事实上却都处于 Active 状态,此时 NodeA 要接管 NodeB 的 resource ,同时 NodeB 要接管 NodeA 的 resource ,这时就是脑裂(split-brain)。
3)脑裂(split-brain)会 引起数据的不完整性 ,并且可能会 对服务造成严重影响 。
4)引起数据的不完整性主要是指,集群中节点(在脑裂期间)同时访问同一共享资源,而此时并没有锁机制来控制针对该数据访问(都脑裂了,咋控制哩),那么就存在数据的不完整性的可能。
对服务造成严重影响,举例来说,可能你早上上班的时候会发现 NodeA 和 NodeB 同时接管了一个虚拟 IP 。
环境:
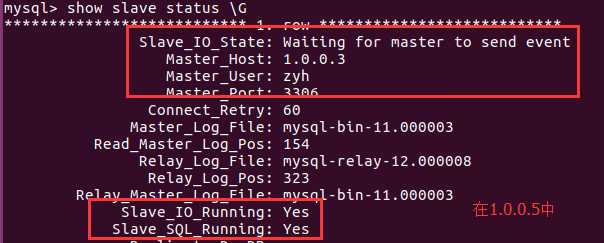
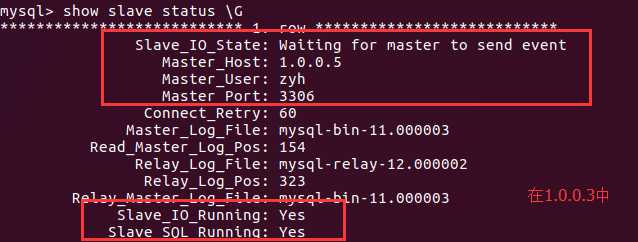
ubuntu17.04的server版:hostname=server1、ip=1.0.0.3
ubuntu17.04的桌面版:hostname=udzyh1、ip1.0.0.5
这里我就不描述了,因为在前面的博客已经介绍了
使用sudo apt install keepalived
首先我们进入到/etc/keepalived中,创建一个keepalived.conf(记住两台都要配置)
1)在主机udzyh1的配置
global_defs { notification_email { liuhl@briup.com } notification_email_from liuhl@briup.com smtp_server 127.0.0.1 smtp_connect_timeout 30 router_id mysql_ha01 } vrrp_instance VI_1 { state MASTER interface ens33 #配置哪个网卡去进行心跳包的传输 virtual_router_id 51 priority 100 #成为主节点 nopreempt #不抢占资源 advert_int 1 #心跳包的频率 1秒一次 authentication { #两台主机通信心跳包的加密 auth_type PASS auth_pass 1111 } virtual_ipaddress { 192.168.41.222/24 #虚拟ip(类似于--proxy-address) } } virtual_server 1.0.0.3 3306 { delay_loop 2 #每个2秒检查一次real_server状态 lb_algo wrr #LVS算法 lb_kind DR #LVS算法 persistence_timeout 60 #会话保持时间 protocol TCP real_server 192.168.41.201 3306 { weight 3 notify_down /home/shell/closekeepalived.sh #检测到服务down后执行的脚本 TCP_CHECK { connect_timeout 10 #连接超时时间 nb_get_retry 3 #重连次数 delay_before_retry 3 #重连间隔时间 connect_port 3306 #健康检查端口 } } }
我们还需要在创建/home/shell/closekeepalived.sh这个脚本
echo "zyh"|sudo -S killall keepalived
给脚本添加执行权限:sudo chmod u+x closekeepalived.sh
配置完成之后开启服务:

2)在主机server1配置
global_defs { notification_email { zhaojing@briup.com } notification_email_from zhaojing@briup.com smtp_server 127.0.0.1 smtp_connect_timeout 30 router_id mysql_ha02(和udzyh1不一样) } vrrp_instance VI_1 { state BACKUP interface ens33 virtual_router_id 51 priority 50 #成为备份节点 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 1.0.0.122 } } virtual_server 1.0.0.122 3306{ delay_loop 3 lb_algo wrr lb_kind DR persistence_timeout 50 protocol TCP real_server 1.0.0.3 3306 { weight 3 notify_down /home/shell/closekeepalived.sh TCP_CHECK{ connect_timeout 10 nb_get_retry 3 delay_before_retry 3 connect_port 3306 } } }
我们还需要在创建/home/shell/closekeepalived.sh这个脚本
echo "zyh"|sudo -S killall keepalived
给脚本添加执行权限:sudo chmod u+x closekeepalived.sh
配置完成之后开启服务:

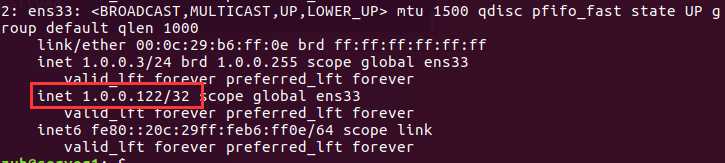
在主机server1和主机udzyh1中分别执行:ip a查看
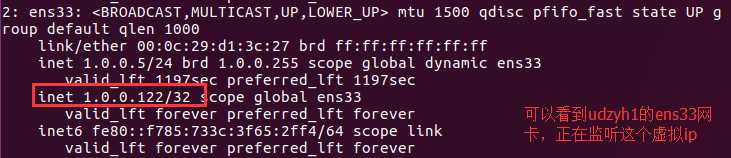
而在server1中,并没有监听虚拟ip,这是因为我们在配置文件中设置了udzyh1主机的keepalived的优先级高。所以当者两台主机
开启的时候,他们两个竞争这个虚拟ip,但是因为udzyh1的优先级高,所以归它了。

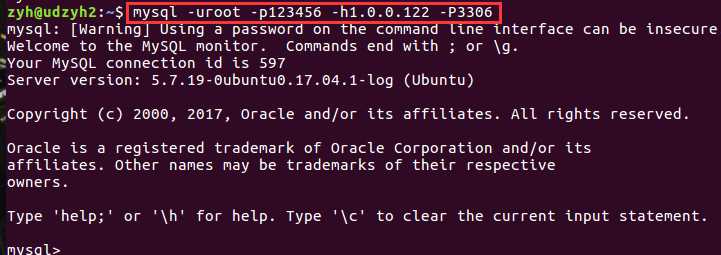
注意:我是在我的udzyh2中测试的
在这里我们使用虚拟ip登录上了udzyh1中的MySQL服务器(因为它是主节点:竞争到了虚拟ip)
我们通过说我们udzyh1中的MySQL服务宕机之后,keepalived检测到了它宕机,会执行配置文件的脚本,使得keepalived停止,
备份节点的keepalived接受不到数据包,所以备份节点就会立刻热切换主节点备份节点从而得到高可用性,获得虚拟ip。
但是我在测试的时候,它不执行脚本,所以即使我强行使用sudo killall mysqld关闭MySQL服务,它不会执行脚本,导致不会关闭
keepalived。
所以这里我直接关闭keepalived来模拟热切换。

我们在查看server1中的 :ip a,可以看到切换成功。
MySQL集群(四)之keepalived实现mysql双主高可用
标签:timeout 通过 efs 工作原理 针对 过程 路由 停止 instance
原文地址:http://www.cnblogs.com/zhangyinhua/p/7567629.html