标签:mono des nim padding pos font 自然语言 hub close
NLPIR分词系统前身为2000年发布的ICTCLAS词法分析系统,从2009年开始,为了和以前工作进行大的区隔,并推广NLPIR自然语言处理与信息检索共享平台,调整命名为NLPIR分词系统。
其主要的功能有中文分词,标注词性和获取句中的关键词。
主要用到的函数有两个: pynlpir.segment(s, pos_tagging=True, pos_names=‘parent‘, pos_english=True)
pynlpir.get_key_words(s, max_words=50, weighted=False)
分词:pynlpir.segment(s, pos_tagging=True, pos_names=‘parent‘, pos_english=True)
S: 句子
pos_tagging:是否进行词性标注
pos_names:显示词性的父类(parent)还是子类(child) 或者全部(all)
pos_english:词性显示英语还是中文
获取关键词:pynlpir.get_key_words(s, max_words=50, weighted=False)
s: 句子
max_words:最大的关键词数
weighted:是否显示关键词的权重
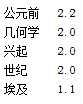
import pynlpirimport jiebapynlpir.open()s = ‘最早的几何学兴起于公元前7世纪的古埃及‘# s = ‘hscode为0110001234的进口‘segments = pynlpir.segment(s, pos_names=‘all‘,pos_english=False)for segment in segments: print (segment[0], ‘\t‘, segment[1])key_words = pynlpir.get_key_words(s, weighted=True)for key_word in key_words: print (key_word[0], ‘\t‘, key_word[1])pynlpir.close()
PyNLPIR python中文分词工具
标签:mono des nim padding pos font 自然语言 hub close
原文地址:http://www.cnblogs.com/combfish/p/7569111.html