标签:测试数据 试验 人生巅峰 任务 lan 介绍 效果 man 台湾
支持向量机(support vector machine, 以下简称svm)是机器学习里的重要方法,特别适用于中小型样本、非线性、高维的分类和回归问题。本篇希望在正篇提供一个svm的简明阐述,附录则提供一些其他内容。(以下各节内容分别来源于不同的资料,在数学符号表述上可能有差异,望见谅。)

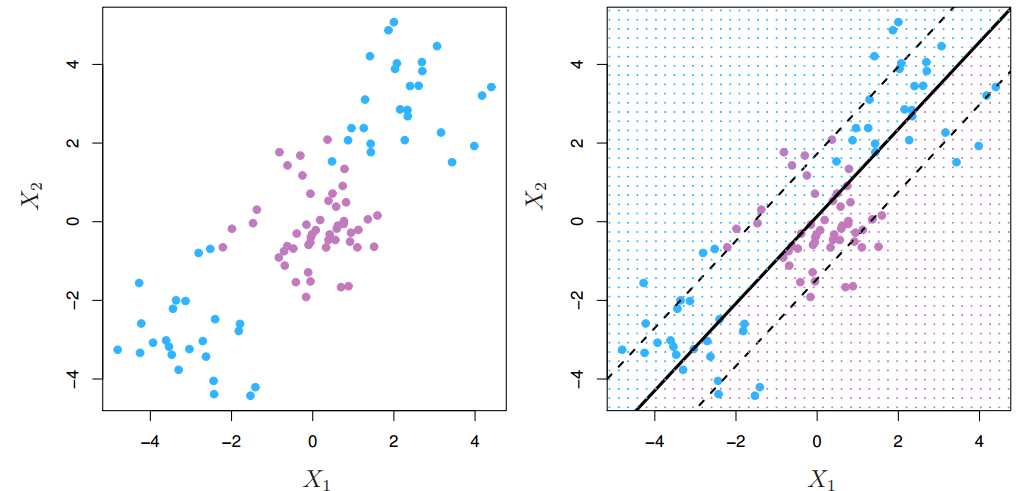
机器学习的一大任务就是分类(Classification)。如下图所示,假设一个二分类问题,给定一个数据集,里面所有的数据都事先被标记为两类,能很容易找到一个超平面(hyperplane)将其完美分类。
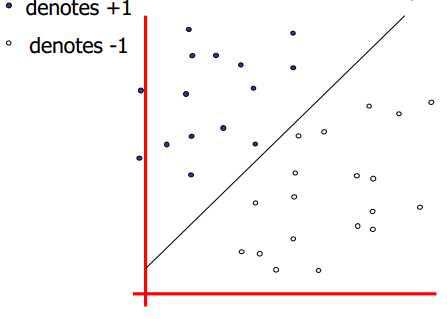
然而实际上可以找到无数个超平面将这两类分开,那么哪一个超平面是效果最好的呢?
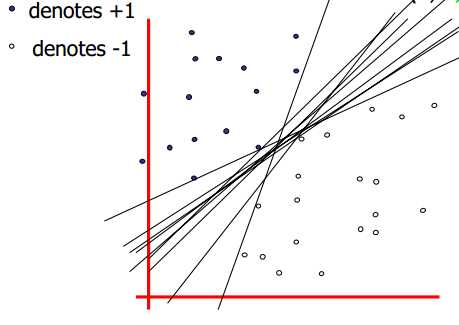
要回答这个问题,首先就要定义什么叫做“效果好”?在面临机器学习问题的时候普遍不是很关心训练数据的分类正确与否,而是关心一个新数据出现的时候其能否被模型正确分类。举个上学的例子(这里主要指理科),训练数据就像是平时的作业和小测验+答案,新数据则像是期末大考或中高考。作业和小测验有答案的帮助下做得很好,我们自然很高兴,但扪心自问,做作业和小测验的目的是为了在这之中取得好成绩吗?其实本质上不是的,作业和小测验的目的是为了训练我们的“大脑模型”,以备在期末大考和中高考中取得好成绩,继而走上人生巅峰。所以在做作业和小测验的时候,重要的是训练一种解题的思路,使之充分熟练进而能举一反三,在真正的大考中灵活地运用这些思路获得好成绩。此类情况用机器学习的说法就是这种“大脑模型”有较好的泛化能力,而相应的“过拟合”则指的是平时做题都会,一到关键大考就掉链子的行为。造成此类“过拟合”的原因固然有很多种,但其中之一恐怕就是平时不训练清楚思路、老是死记硬背、以至把答案中的“噪音”也学进去了。
所以在上述二分类问题中,如果新数据被分类的准确率高,可以认为是“效果好”,或者说有较好的泛化能力。因此这里的问题就转化为:上图中哪一个超平面对新数据的分类准确率最高?
然而令人沮丧的是,没人能确切地回答哪个超平面最好,因为没人能把真实世界中的所有数据都拿过来测试。从广义上来说,大部分的理论研究都是对真实情况的模拟,譬如我们用人均收入来衡量一个国家的人民生活水平,这里的人均收入甚至只是一个不太接近的近似,因为不可能把每个国家中所有人的收入都拿出来一一比较。我们的大脑善于把繁琐的细节组合起来并高度抽象化,形成模型和假设,来逼近真实情况。
所以,在这个问题上我们能做的,也只有提出假设,建立模型,验证假设。而在svm中,这个假设就是:拥有最大间隔的超平面效果最好。
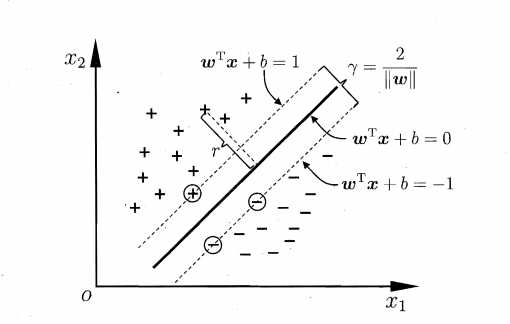
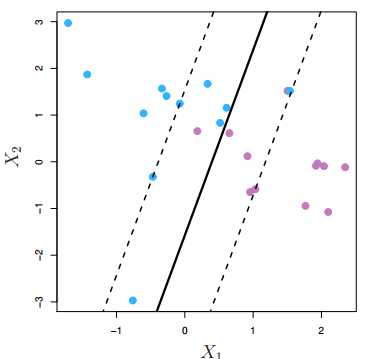
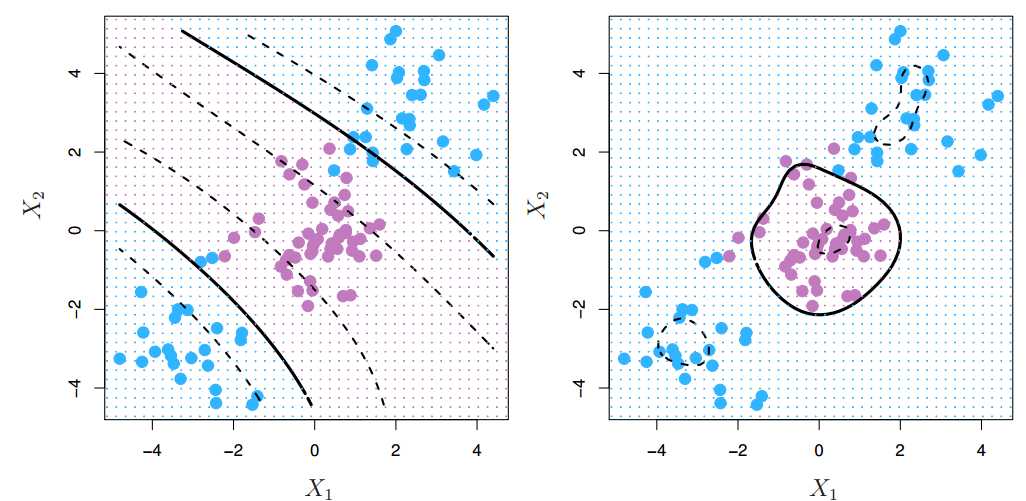
间隔(margin)指的是所有数据点中到这个超平面的最小距离。如下图所示,实线为超平面,虚线为间隔边界,黑色箭头为间隔,即虚线上的点到超平面的距离。可以看出,虚线上的三个点(2蓝1红)到超平面的距离都是一样的,实际上只有这三个点共同决定了超平面的位置,因而它们被称为“支持向量(support vectors)”,而“支持向量机”也由此而得名。
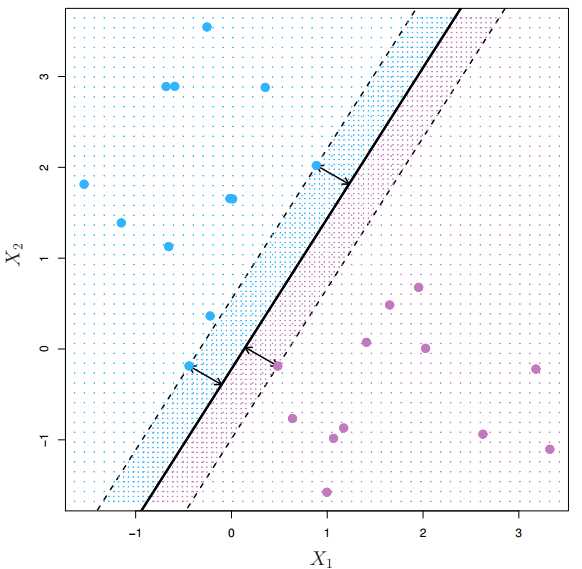
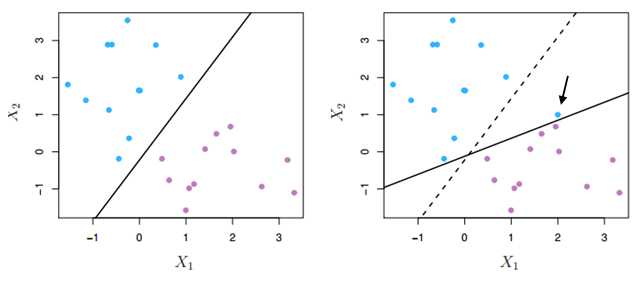
于是我们来到了svm的核心思想 —— 寻找一个超平面,使其到数据点的间隔最大。原因主要是这样的超平面分类结果较为稳健(robust),对于最难分的数据点(即离超平面最近的点)也能有足够大的确信度将它们分开,因而泛化到新数据点效果较好。
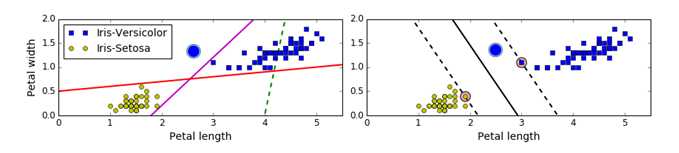
比如上左图的红线和紫线虽然能将两类数据完美分类,但注意到这两个超平面本身非常靠近数据点。以紫线为例,圆点为测试数据,其正确分类为蓝色,但因为超平面到数据点的间隔太近,以至于被错分成了黄色。 而上右图中因为间隔较大,圆点即使比所有蓝点更靠近超平面,最终也能被正确分类。
定义超平面:![]()
假设二分类问题中正类的标签为+1,负类的标签为 -1,若要找到一个超平面能正确分类所有样本点点,且所有样本点都位于间隔边界上或间隔边界外侧(如上图所示),
则满足 ,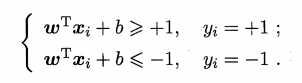
该式也可写为: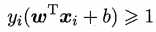
上图中距离超平面最近的三个点(即支持向量)满足 |wTx+b| = 1,又由样本空间任意点x到超平面的距离:![]() , 因此所有数据点的最小间隔为
, 因此所有数据点的最小间隔为![]()
因为我们的目标是间隔最大化,因此问题转化为:
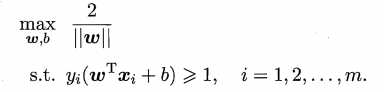
上述优化问题的解为间隔最大时的w和b,随即可求出超平面 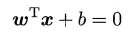
为后面解优化问题方便,上式可重写为:
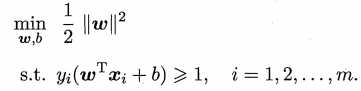
这是一个凸二次规划(convex quadratic programming)问题,可以用现成的软件包计算。然而现实中一般采用对偶算法(dual algorithm),通过求解原始问题(primal problem)的对偶问题(dual problem),来获得原始问题(primal problem)的最优解。这样做的优点,一是对偶问题往往更容易求解,二是能自然地引入核函数,进而高效的解决高维非线性分类问题。
拉格朗日乘子法的主要思想是将含有n个变量和k个约束条件的约束优化问题转化为含有(n+k)个变量的无约束优化问题。下面阐述其原理 :
考虑一个“原始问题”:
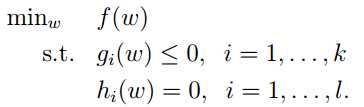
其中w为优化变量,为了解这个问题,引入广义拉格朗日函数:
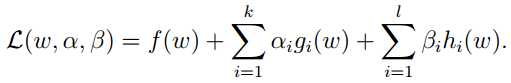
ɑi和βi为拉格朗日乘子,ɑi ≥0,考虑下式:
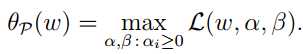
这里的下标P意为原始问题(primal problem),若w违反了一些原始问题的约束条件(即存在某个i,使得gi(w) > 0 或 hi(w) ≠ 0),那么就有
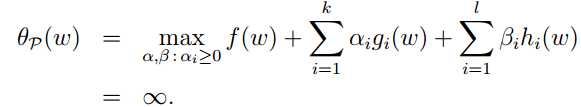
于是,
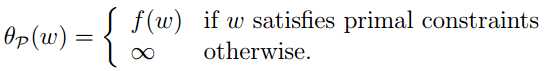
因而极小化问题 ![]() 与“原始问题”就是等价的,因为只有当w满足原始优化条件时,
与“原始问题”就是等价的,因为只有当w满足原始优化条件时,![]() 。为了方便,定义原始问题的最优值为
。为了方便,定义原始问题的最优值为 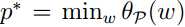
接下来考虑“对偶问题”,定义:
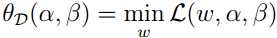
这里的下标D意为对偶(dual),接着考虑其极大化问题:
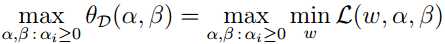
该式称为原始问题的对偶问题,定义其最优值为 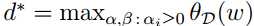
原始问题和对偶问题的关系可以用下式表示:
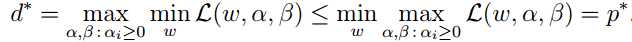
若要满足强对偶性(strong duality),即 ![]() ,则需满足Slater条件: f(w)和g(w)都是凸函数,h(w)是仿射函数,并且存在w使得所有的不等式约束g(w)<0成立。
,则需满足Slater条件: f(w)和g(w)都是凸函数,h(w)是仿射函数,并且存在w使得所有的不等式约束g(w)<0成立。
另外因为有不等式约束, ![]() 需满足下列Karush-Kuhn-Tucker (KKT)条件 :
需满足下列Karush-Kuhn-Tucker (KKT)条件 :
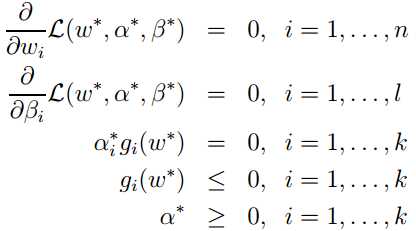
这时原始问题和对偶问题的最优解相同,可用解对偶问题替代解原始问题。
在svm中我们的原始问题:
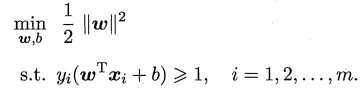
由拉格朗日乘子法,为每条约束引进拉格朗日乘子αi ≥ 0,该问题的拉格朗日函数变为:
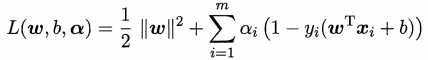
原始问题的对偶问题为: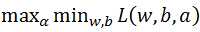 。依据KKT条件,先固定ɑ,令L(w, b, α)对w和b的偏导为0可得,
。依据KKT条件,先固定ɑ,令L(w, b, α)对w和b的偏导为0可得,
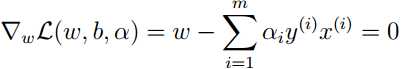 ,
, 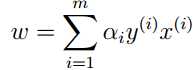
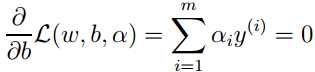
将上两式代入拉格朗日函数,即可得对偶问题的新形式:
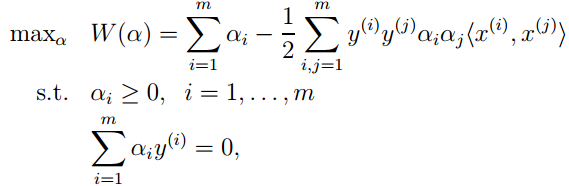
求出上式中的α后,即可求得原始问题中的w和b。
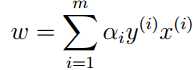
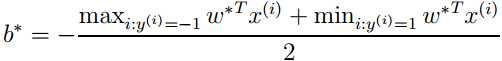
于是分离超平面就是: 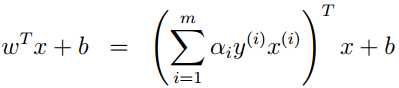
在w和b的求解公式中,注意到w和b由对应于α> 0的样本点(xi,yi)决定,又由KKT条件中:αi (yi(w?xi+b)-1)=0 , yi(w?xi+b)= ±1,因此这些样本点(xi,yi)一定在间隔边界上,它们就是“支持向量”,这些点共同决定了分离超平面。
上一节求解出来的间隔被称为“硬间隔(hard margin)“,其可以将所有样本点划分正确且都在间隔边界之外,即所有样本点都满足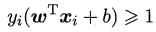
但硬间隔有两个缺点:1. 不适用于线性不可分数据集。 2. 对离群点(outlier)敏感。
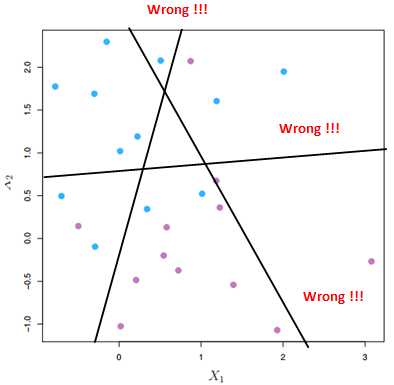
比如下图就无法找到一个超平面将蓝点和紫点完全分开:
下图显示加入了一个离群点后,超平面发生了很大的变动,最后形成的间隔变得很小,这样最终的泛化效果可能不会太好。
为了缓解这些问题,引入了“软间隔(soft margin)”,即允许一些样本点跨越间隔边界甚至是超平面。如下图中一些离群点就跨过了间隔边界。
于是为每个样本点引入松弛变量 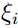 ,优化问题变为:
,优化问题变为:
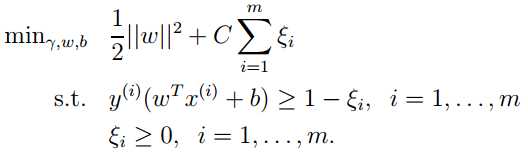
由上式可以看出:
1. 离群点的松弛变量值越大,点就离得越远。
2. 所有没离群的点松弛变量都等于0,即这些点都满足![]()
3. C > 0 被称为惩罚参数,即为scikit-learn中的svm超参数C。当C设的越大,意味着对离群点的惩罚就越大,最终就会有较少的点跨过间隔边界,模型也会变得复杂。而C设的越小,则较多的点会跨过间隔边界,最终形成的模型较为平滑。
上述优化问题同样可使用拉格朗日乘子法:
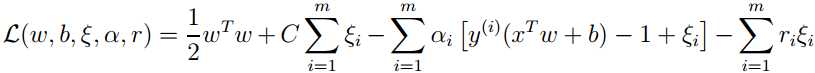
运用和上一节同样的方法,分别对w,b, 求偏导,得到对偶问题:
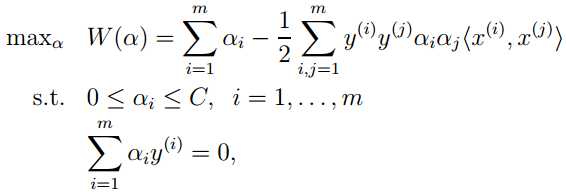
求出上式中的α后,即可求得原始问题中的w和b,进而获得分离超平面。
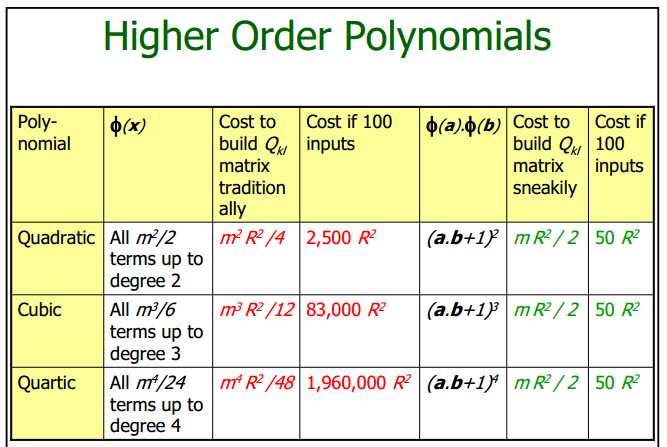
前几节展示的硬间隔和软间隔svm主要是用于处理线性分类问题,然而现实中很多分类问题是非线性的,如下图所示,无论怎样一个线性超平面都无法很好地将样本点分类:
所以在此引入核函数(kernel function),构造非线性svm,如下图所示,左图使用的是多项式核函数,右图使用的是高斯核函数,二者均能将样本点很好地分类:
核函数的主要作用是将样本从原始空间映射到一个更高维的特征空间,使得样本在这个特征空间内线性可分。下图显示原来在二维空间不可分的两类样本点,在映射到三维空间后变为线性可分 :
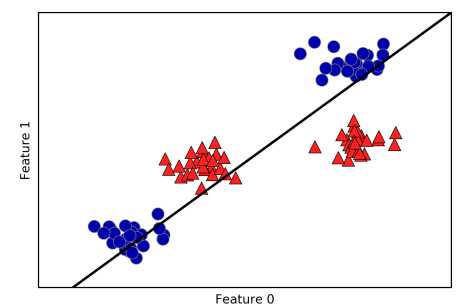
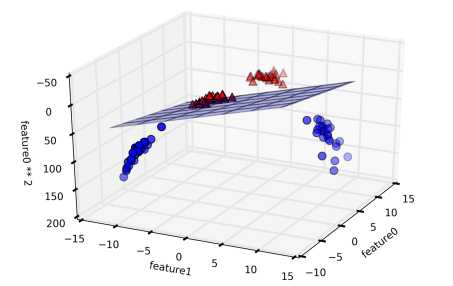
但回到原来的二维空间中,决策边界就变成非线性的了:
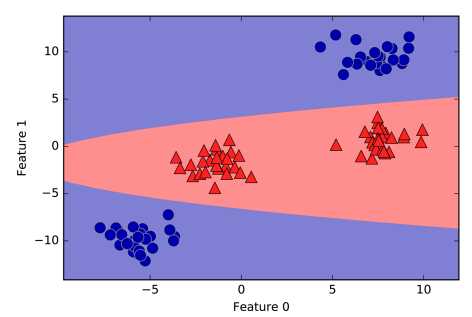
核函数是如何将原始空间映射到高维的特征空间的? 下面先举个例子:
假设做一个2维到3维的映射,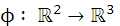
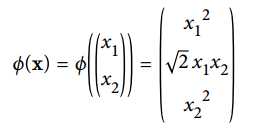 , 求
, 求 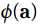 和
和 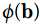 的内积:
的内积:
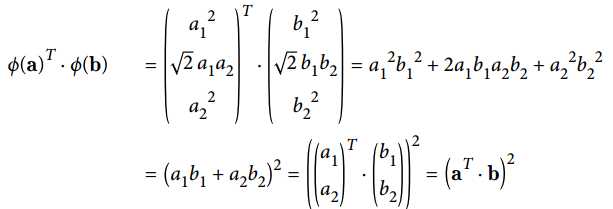
可以看出转换后向量的内积等于原向量内积的平方,即 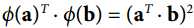
函数![]() 被称为二次多项核函数,于是如果想计算高维特征空间的内积
被称为二次多项核函数,于是如果想计算高维特征空间的内积 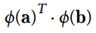 ,我们只需计算核函数,即原向量内积的平方
,我们只需计算核函数,即原向量内积的平方 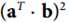
就可以了。这样做的好处有:
下图也能看出在原始空间和高维空间下计算量的巨大差异:
在上一节中,最后的对偶问题为: 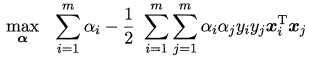
将原始空间映射到高维特征空间后变为: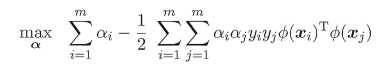
直接计算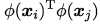 比较复杂,因此若能找到一个核函数
比较复杂,因此若能找到一个核函数 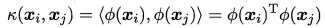 ,则最后变为:
,则最后变为:
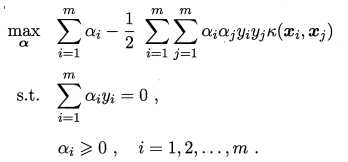
求解后的分离超平面为:
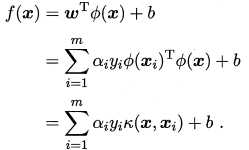
这样我们就能以较小的计算量解决非线性分类问题,甚至都不需要知道低维空间的数据是怎样映射到高维空间的,只需要在原来的低维空间计算核函数就行了。

由于高斯核函数是目前最主流的核函数,所以在这里以其举例介绍:
高斯核(Gaussian Kernel) 属于径向基函数(Radial Basis Function , RBF)的一种。其表达式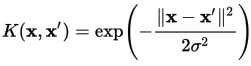
也可写为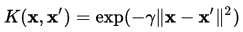 ,范围为(0,1],其中
,范围为(0,1],其中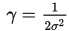
高斯核函数可理解为两个样本点的相似程度,两点(x, x’)的距离 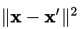 越大,
越大,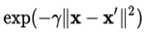 越小,则两个点的相似程度很小,这意味着高斯核具有“局部(local)”特征,只有相对邻近的样本点会对测试点的分类产生较大作用。
越小,则两个点的相似程度很小,这意味着高斯核具有“局部(local)”特征,只有相对邻近的样本点会对测试点的分类产生较大作用。 ![]() ,即为scikit-learn中的svm超参数 γ,γ 越大,意味着两个点只有相当接近时才会被判为相似,这样决策边界会变得较为扭曲,容易过拟合,因为只取决于较少的几个样本点。相反,γ 越小,大量的点被判为近似,因而导致模型变得简单,容易欠拟合。
,即为scikit-learn中的svm超参数 γ,γ 越大,意味着两个点只有相当接近时才会被判为相似,这样决策边界会变得较为扭曲,容易过拟合,因为只取决于较少的几个样本点。相反,γ 越小,大量的点被判为近似,因而导致模型变得简单,容易欠拟合。
线性svm还有另一种解释方法,能揭示出其与其他分类方法(如Logistic Regression)的渊源。线性svm的原始最优化问题:
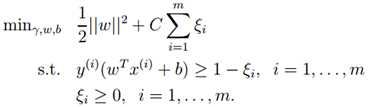 可重写为:
可重写为: ![]()
[1-y(w?x+b)]+ 也可写为 max(0, 1-y((w?x+b)),该损失函数被称为Hinge Loss。
若将式中 [1-y(w?x+b)]+ 替换为对率损失(logistic loss): log[1+exp(-y(w?x+b))],则成为了Logistic Regression的损失函数。下图显示出二者的关系:
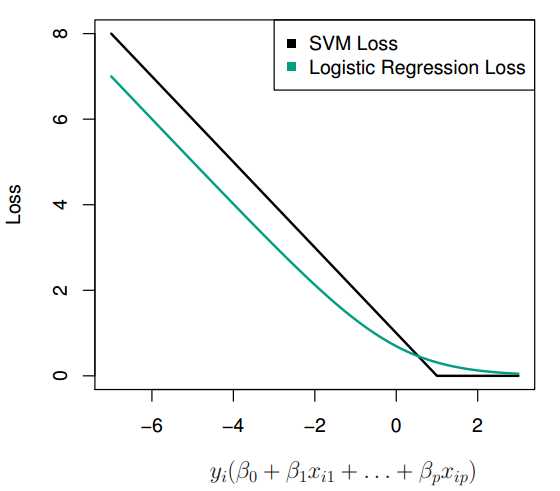
也即是说,对于svm的hinge loss而言,如果样本点被正确分类且在间隔边界之外,即w?x + b >1,则[1-y(w?x+b)] +=0,损失为0。若样本点即使被正确分类,但位于超平面和间隔边界之间,意味着分类正确的确信度不够高,因而损失不为0。而对于logistic regression来说,所有的样本点都会有损失,因为其损失函数
log[1+exp(-y(w?x+b))] 始终不为0,但当样本点远离其决策边界时,损失就会变得非常接近0。
第二节中提到样本空间任意点x到超平面的距离为: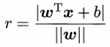 ,下面给出证明:
,下面给出证明:
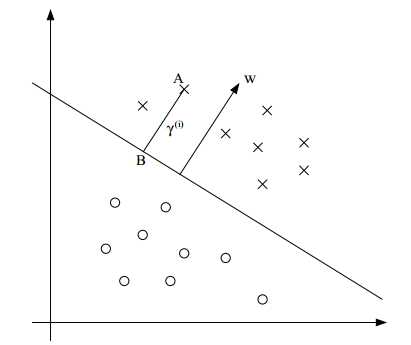
上图中超平面为: 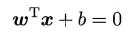 ,假设x1和x2都在超平面上,则有 wTx1+b = wTx2+b, wT(x1-x2)=0,即法向量w与超平面上任意向量正交。
,假设x1和x2都在超平面上,则有 wTx1+b = wTx2+b, wT(x1-x2)=0,即法向量w与超平面上任意向量正交。
B点为A点到超平面的投影,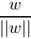 为垂直于超平面的单位向量,γ为A到超平面的算术距离,A点为 x(i),则B点为
为垂直于超平面的单位向量,γ为A到超平面的算术距离,A点为 x(i),则B点为 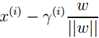 ,代入
,代入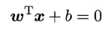 得:
得:
无论是线性还是非线性svm,最后都要归结为求拉格朗日乘子α的问题。
可以用通用的二次规划算法求解,但现实中当训练样本容量很大时,往往求解非常低效。所以本节介绍的SMO(sequential minimal optimization)算法就是高效求解上述问题的算法之一。
SMO算法的基本思路是:选择两个变量α1和α2,固定其他所有α,针对这两个变量构建二次规划问题,这样就比原来复杂的优化问题简化很多。由于有约束条件  ,固定了其他α后,可得
,固定了其他α后,可得 。所以α1确定后,α2即可自动获得,该问题中的两个变量会同时更新,再不断选取新的变量进行优化。
。所以α1确定后,α2即可自动获得,该问题中的两个变量会同时更新,再不断选取新的变量进行优化。
SMO采用启发式的变量选择方法:第1个变量α1,一般选择训练样本中违反KKT条件最严重的样本点所对应的α。而第2个变量α2则选取与α1的样本点之间间隔最大的样本点对应的α,这样二者的更新往往会给目标函数带来更大的变化。
下面来看如何解α1和α2:
由于其他变量αi (i=3,4…N)都是固定的,所以有 ![]() ,其中
,其中![]() 为常数。又有约束
为常数。又有约束 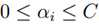 ,且y1,y2只能取值+1或-1,所以α1,α2的直线平行于[0,C]×[0,C]形成的对角线。
,且y1,y2只能取值+1或-1,所以α1,α2的直线平行于[0,C]×[0,C]形成的对角线。
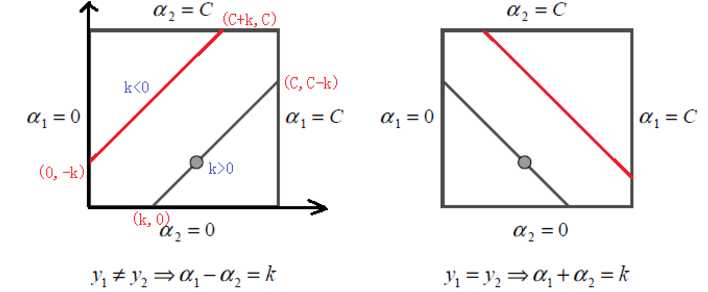
这里采用迭代法,假设上一轮迭代得到的解是α1old和α2old,沿着约束方向未经剪辑时α2的最优解为α2new, unclipped。本轮迭代完成后的解为α1new 和 α2new。
以上左图为例,假设要求α2的最小值,令α1等于0,由α1-α2 =k,
则α2new = -k = α2old -α1old。但因为α2new必须在[0,C],若α2old -α1old <0,则α2new 必须等于0,因此α2new的下界 L=max(0, α2old -α1old)。
同理,上界H = min(C, C+α2old -α1old)。
则: 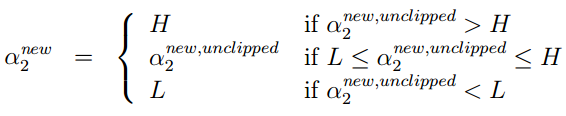
再由 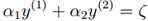 即可求得α1new,这样α1和α2就同时得到了更新。
即可求得α1new,这样α1和α2就同时得到了更新。
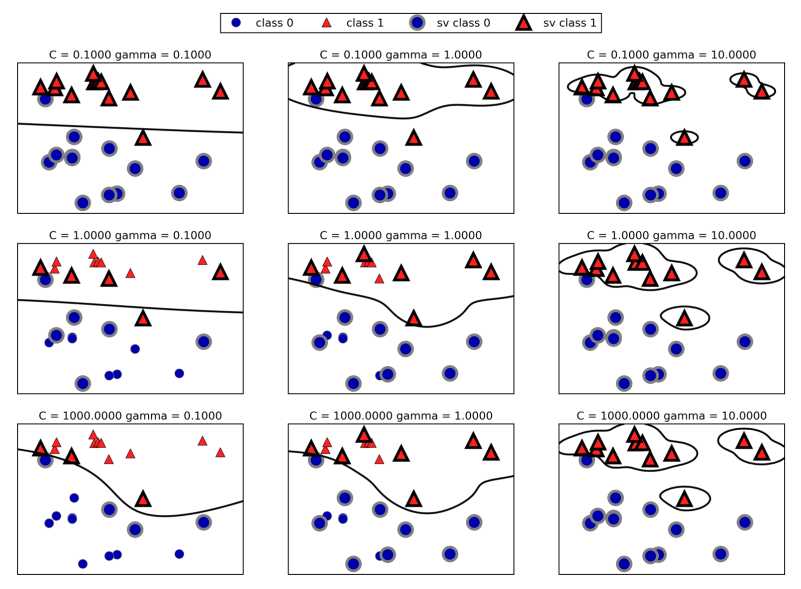
如正片中所述,scikit-learn中svm库的两个主要超参数为C和γ,C和γ越大,则模型趋于复杂,容易过拟合;反之,C和γ越大,模型变得简单,如下图所示:
LibSVM的作者,国立台湾大学的林智仁教授在其一篇小文(A Practical Guide to Support Vector Classification)中提出了svm库的一般使用流程 :

其中第二步scaling对于svm的整体效果有重大影响。主要原因为在没有进行scaling的情况下,数值范围大的特征会产生较大的影响,进而影响模型效果。
第三步中认为应优先试验RBF核,通常效果比较好。但他同时也提到,RBF核并不是万能的,在一些情况下线性核更加适用。当特征数非常多,或者样本数远小于特征数时,使用线性核已然足够,映射到高维空间作用不大,而且只要对C进行调参即可。虽然理论上高斯核的效果不会差于线性核,但高斯核需要更多轮的调参。
而且当样本量非常大时,线性核的效率要远高于其他核函数,在实际问题中这一点可能变得非常重要。scikit-learn的LinearSVC库计算量和样本数线性相关,时间复杂度约为O(m× n),而SVC库的时间复杂度约为O(m2×n)到O(m3×n),当样本量很大时训练速度会变得很慢,因此使用非线性核的svm不大适合样本量非常大的情景。下表总结了scikit-learn中的svm分类库:

[1] 周志华.《机器学习》
[2] 李航.《统计学习方法》
[3] Andrew Ng. cs229 Lecture notes 3
[4] Hastie, etc. An Introduction to Statistical Learning
[5] Aurélien Géron. Hands-On Machine Learning with Scikit-Learn&TensorFlow
[6] Andrew W. Moore. Support Vector Machines
[7] Pang-Ning Tan, etc. Introduction to Data Mining
[8] Chih-Jen Lin, etc. A Practical Guide to Support Vector Classification
[9] Wikipedia, Lagrange multiplier
[10] Wikipedia, Radial basis function kernel
/
A glimpse of Support Vector Machine
标签:测试数据 试验 人生巅峰 任务 lan 介绍 效果 man 台湾
原文地址:http://www.cnblogs.com/massquantity/p/7580688.html