标签:学习 print sorted dex als 二维 efault 中标 manager
1 KNN算法
1.1 KNN算法简介
KNN(K-Nearest Neighbor)工作原理:存在一个样本数据集合,也称为训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分类对应的关系。输入没有标签的数据后,将新数据中的每个特征与样本集中数据对应的特征进行比较,提取出样本集中特征最相似数据(最近邻)的分类标签。一般来说,我们只选择样本数据集中前k个最相似的数据,这就是k近邻算法中k的出处,通常k是不大于20的整数。最后选择k个最相似数据中出现次数最多的分类作为新数据的分类。
说明:KNN没有显示的训练过程,它是“懒惰学习”的代表,它在训练阶段只是把数据保存下来,训练时间开销为0,等收到测试样本后进行处理。
举例:以电影分类作为例子,电影题材可分为爱情片,动作片等,那么爱情片有哪些特征?动作片有哪些特征呢?也就是说给定一部电影,怎么进行分类?这里假定将电影分为爱情片和动作片两类,如果一部电影中接吻镜头很多,打斗镜头较少,显然是属于爱情片,反之为动作片。有人曾根据电影中打斗动作和接吻动作数量进行评估,数据如下:
|
电影名称 |
打斗镜头 |
接吻镜头 |
电影类别 |
|
Califoria Man |
3 |
104 |
爱情片 |
|
Beautigul Woman |
1 |
81 |
爱情片 |
|
Kevin Longblade |
101 |
10 |
动作片 |
|
Amped II |
98 |
2 |
动作片 |
给定一部电影数据(18,90)打斗镜头18个,接吻镜头90个,如何知道它是什么类型的呢?KNN是这样做的,首先计算未知电影与样本集中其他电影的距离(这里使用曼哈顿距离),数据如下:
|
电影名称 |
与未知分类电影的距离 |
|
Califoria Man |
20.5 |
|
Beautigul Woman |
19.2 |
|
Kevin Longblade |
115.3 |
|
Amped II |
118.9 |
现在我们按照距离的递增顺序排序,可以找到k个距离最近的电影,加入k=3,那么来看排序的前3个电影的类别,爱情片,爱情片,动作片,下面来进行投票,这部未知的电影爱情片2票,动作片1票,那么我们就认为这部电影属于爱情片。
1.2 KNN算法优缺点
优点:精度高,对异常值不敏感、无数据输入假定
缺点:计算复杂度高、空间复杂度高
1.3 KNN算法python代码实现
实现步骤:
(1)计算距离
(2)选择距离最小的k个点
(3)排序
Python 3代码:

1 import numpy as np 2 import operator 3 4 def classify(intX,dataSet,labels,k): 5 ‘‘‘ 6 KNN算法 7 ‘‘‘ 8 #numpy中shape[0]返回数组的行数,shape[1]返回列数 9 dataSetSize = dataSet.shape[0] 10 #将intX在横向重复dataSetSize次,纵向重复1次 11 #例如intX=([1,2])--->([[1,2],[1,2],[1,2],[1,2]])便于后面计算 12 diffMat = np.tile(intX,(dataSetSize,1))-dataSet 13 #二维特征相减后乘方 14 sqdifMax = diffMat**2 15 #计算距离 16 seqDistances = sqdifMax.sum(axis=1) 17 distances = seqDistances**0.5 18 print ("distances:",distances) 19 #返回distance中元素从小到大排序后的索引 20 sortDistance = distances.argsort() 21 print ("sortDistance:",sortDistance) 22 classCount = {} 23 for i in range(k): 24 #取出前k个元素的类别 25 voteLabel = labels[sortDistance[i]] 26 print ("第%d个voteLabel=%s",i,voteLabel) 27 classCount[voteLabel] = classCount.get(voteLabel,0)+1 28 #dict.get(key,default=None),字典的get()方法,返回指定键的值,如果值不在字典中返回默认值。 29 #计算类别次数 30 31 #key=operator.itemgetter(1)根据字典的值进行排序 32 #key=operator.itemgetter(0)根据字典的键进行排序 33 #reverse降序排序字典 34 sortedClassCount = sorted(classCount.items(),key = operator.itemgetter(1),reverse = True) 35 #结果sortedClassCount = [(‘动作片‘, 2), (‘爱情片‘, 1)] 36 print ("sortedClassCount:",sortedClassCount) 37 return sortedClassCount[0][0]
2 KNN算法实例
2.1 KNN实现电影分类
1 import numpy as np 2 import operator 3 4 def createDataset(): 5 #四组二维特征 6 group = np.array([[5,115],[7,106],[56,11],[66,9]]) 7 #四组对应标签 8 labels = (‘动作片‘,‘动作片‘,‘爱情片‘,‘爱情片‘) 9 return group,labels 10 11 def classify(intX,dataSet,labels,k): 12 ‘‘‘ 13 KNN算法 14 ‘‘‘ 15 #numpy中shape[0]返回数组的行数,shape[1]返回列数 16 dataSetSize = dataSet.shape[0] 17 #将intX在横向重复dataSetSize次,纵向重复1次 18 #例如intX=([1,2])--->([[1,2],[1,2],[1,2],[1,2]])便于后面计算 19 diffMat = np.tile(intX,(dataSetSize,1))-dataSet 20 #二维特征相减后乘方 21 sqdifMax = diffMat**2 22 #计算距离 23 seqDistances = sqdifMax.sum(axis=1) 24 distances = seqDistances**0.5 25 print ("distances:",distances) 26 #返回distance中元素从小到大排序后的索引 27 sortDistance = distances.argsort() 28 print ("sortDistance:",sortDistance) 29 classCount = {} 30 for i in range(k): 31 #取出前k个元素的类别 32 voteLabel = labels[sortDistance[i]] 33 print ("第%d个voteLabel=%s",i,voteLabel) 34 classCount[voteLabel] = classCount.get(voteLabel,0)+1 35 #dict.get(key,default=None),字典的get()方法,返回指定键的值,如果值不在字典中返回默认值。 36 #计算类别次数 37 38 #key=operator.itemgetter(1)根据字典的值进行排序 39 #key=operator.itemgetter(0)根据字典的键进行排序 40 #reverse降序排序字典 41 sortedClassCount = sorted(classCount.items(),key = operator.itemgetter(1),reverse = True) 42 #结果sortedClassCount = [(‘动作片‘, 2), (‘爱情片‘, 1)] 43 print ("sortedClassCount:",sortedClassCount) 44 return sortedClassCount[0][0] 45 46 47 48 if __name__ == ‘__main__‘: 49 group,labels = createDataset() 50 test = [20,101] 51 test_class = classify(test,group,labels,3) 52 print (test_class)
2.2 改进约会网站匹配
这个例子简单说就是通过KNN找到你喜欢的人,首先数据样本包含三个特征,(a)每年获得的飞行常客里程数(b)玩游戏消耗的时间(c)每周消耗的冰激淋公升数,样本数据放在txt中,如下,前三列为三个特征值,最后一列为标签
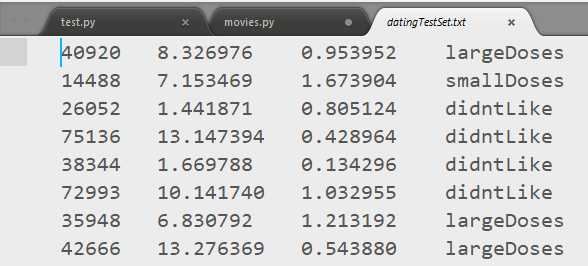
首先读取数据,获取数据集和标签
1 def file2matrix(filename): 2 fr = open(filename) 3 arraylines = fr.readlines() 4 #获取行数 5 numberoflines = len(arraylines) 6 #返回numpy的数据矩阵,目前矩阵数据为0 7 returnMat = np.zeros([numberoflines,3]) 8 #返回的分类标签 9 classLabelVector = [] 10 #行的索引 11 index = 0 12 for line in arraylines: 13 #str.strip(rm) 删除str头和尾指定的字符 rm为空时,默认删除空白符(包括‘\n‘,‘\r‘,‘\t‘,‘ ‘) 14 line = line.strip() 15 #每行数据是\t划分的,将每行数据按照\t进行切片划分 16 listFromLine = line.split(‘\t‘) 17 #取出前三列数据存放到returnMat 18 returnMat[index,:] = listFromLine[0:3] 19 #根据文本中标记的喜欢程度进行分类 20 if listFromLine[-1] == "didntLike": 21 classLabelVector.append(1) 22 elif listFromLine[-1] == "smallDoses": 23 classLabelVector.append(2) 24 else: 25 classLabelVector.append(3) 26 index += 1 27 return returnMat,classLabelVector
数据和标签我们可以打印一下:
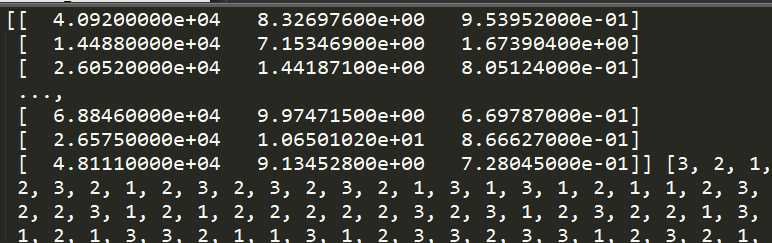
下面用Matplotlib作图看一下数据信息:
1 from matplotlib.font_manager import FontProperties 2 import numpy as np 3 import matplotlib.pyplot as plt 4 from prepareData_1 import file2matrix 5 import matplotlib.lines as mlines 6 # from matplotlib.font_manage import FontProperties 7 ‘‘‘ 8 函数说明:数据可视化 9 Parameters: 10 datingDataMat - 特征矩阵 11 datingLabels - 分类标签向量 12 Returns: 13 无 14 ‘‘‘ 15 def showDatas(datingDataMat,datingLabels): 16 #设置汉子格式 17 font = FontProperties(fname=r"c:\windows\fonts\simsun.ttc", size=14) 18 #函数返回一个figure图像和一个子图ax的array列表。 19 fig,axs = plt.subplots(nrows=2,ncols=2,sharex=False,sharey=False,figsize=(13,8)) 20 21 numberofLabels = len(datingLabels) 22 LabelColors = [] 23 for i in datingLabels: 24 if i==1: 25 LabelColors.append(‘black‘) 26 if i ==2: 27 LabelColors.append(‘orange‘) 28 if i==3: 29 LabelColors.append("red") 30 #画散点图,以数据矩阵的第一列(飞行常客历程)、第二列(玩游戏)数据话散点图 31 #散点大小为15 透明度为0.5 32 axs[0][0].scatter(x=datingDataMat[:,0],y=datingDataMat[:,1],color=LabelColors, 33 s=15,alpha=0.5) 34 axs0_title_text=axs[0][0].set_title(u"每年获得的飞行里程数与玩视频游戏消耗时间占比", 35 FontProperties=font) 36 axs0_xlabel_text=axs[0][0].set_xlabel("每年获得的飞行常客里程数",FontProperties=font) 37 axs0_ylabel_text=axs[0][0].set_ylabel("玩游戏消耗的时间",FontProperties=font) 38 plt.setp(axs0_title_text,size=9,weight=‘bold‘,color=‘red‘) 39 #画散点图,以数据矩阵的第一列(飞行常客历程)、第三列(冰激淋公斤数)数据话散点图 40 #散点大小为15 透明度为0.5 41 axs[0][1].scatter(x=datingDataMat[:,0],y=datingDataMat[:,2],color=LabelColors, 42 s=15,alpha=0.5) 43 axs0_title_text=axs[0][0].set_title("每年获得的飞行里程数与冰激淋公斤数占比", 44 FontProperties=font) 45 axs0_xlabel_text=axs[0][0].set_xlabel("每年获得的飞行常客里程数",FontProperties=font) 46 axs0_ylabel_text=axs[0][0].set_ylabel("所吃冰激淋公斤数",FontProperties=font) 47 plt.setp(axs0_title_text,size=9,weight=‘bold‘,color=‘red‘) 48 #画散点图,以数据矩阵的第二列(玩游戏)、第三列(冰激淋公斤数)数据话散点图 49 #散点大小为15 透明度为0.5 50 axs[1][0].scatter(x=datingDataMat[:,1],y=datingDataMat[:,2],color=LabelColors, 51 s=15,alpha=0.5) 52 axs0_title_text=axs[0][0].set_title("玩游戏时间与冰激淋公斤数占比", 53 FontProperties=font) 54 axs0_xlabel_text=axs[0][0].set_xlabel("每年获得的飞行常客里程数",FontProperties=font) 55 axs0_ylabel_text=axs[0][0].set_ylabel("所吃冰激淋公斤数",FontProperties=font) 56 plt.setp(axs0_title_text,size=9,weight=‘bold‘,color=‘red‘) 57 58 #设置图例 59 didntLike = mlines.Line2D([],[],color=‘black‘,marker=‘.‘,markersize=6,label=‘didntlike‘) 60 smallDose = mlines.Line2D([],[],color=‘orange‘,marker=‘.‘,markersize=6,label=‘smallDose‘) 61 largeDose = mlines.Line2D([],[],color=‘red‘,marker=‘.‘,markersize=6,label=‘largeDose‘) 62 63 #添加图例 64 axs[0][0].legend(handles=[didntLike,smallDose,largeDose]) 65 axs[0][1].legend(handles=[didntLike,smallDose,largeDose]) 66 axs[1][0].legend(handles=[didntLike,smallDose,largeDose]) 67 68 plt.show() 69 70 if __name__ == ‘__main__‘: 71 filename = "datingTestSet.txt" 72 returnMat,classLabelVector = file2matrix(filename) 73 showDatas(returnMat,classLabelVector) 74 75
这里我把py文件分开写了,还要注意txt数据的路径,高大上的图:
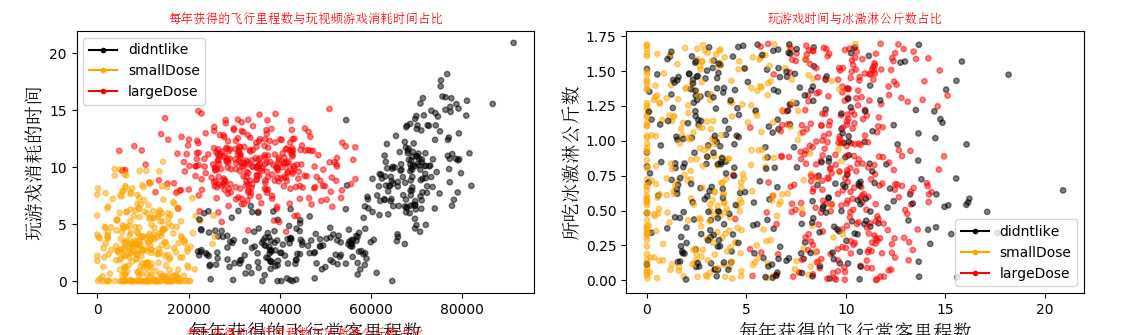
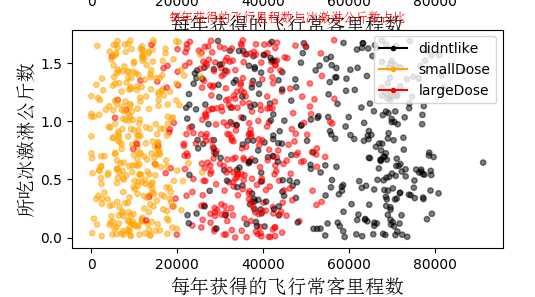
样本数据中的到底喜欢什么样子的人?自己去分析一下吧。下面要对数据进行归一化,归一化的原因就不多说了,
1 from prepareData_1 import file2matrix 2 import numpy as np 3 ‘‘‘ 4 函数说明:数据归一化 5 Parameters: 6 dataSet - 特征矩阵 7 Returns: 8 normDataSet - 归一化后的特征矩阵 9 ranges - 数据范围 10 minVals - 数据最小值 11 ‘‘‘ 12 13 def autoNorm(dataSet): 14 #获得数据的最大最小值 15 print (dataSet) 16 print ("**********************") 17 minVals = dataSet.min(0) 18 maxVals = dataSet.max(0) 19 print ("minValues:",minVals) 20 print ("maxValuse:",maxVals) 21 #计算最大最小值的差 22 ranges = maxVals - minVals 23 print () 24 #shape(dataSet)返回dataSet的矩阵行列数 25 normDataSet=np.zeros(np.shape(dataSet)) 26 #返回dataSet的行数 27 m = dataSet.shape[0] 28 #原始值减去最小值 29 normDataSet=dataSet-np.tile(minVals,(m,1)) 30 #除以最大值和最小值的差,得到的归一化的数据 31 normDataSet = normDataSet/np.tile(ranges,(m,1)) 32 return normDataSet,ranges,minVals
归一化后的数据如下:
 有了以上步骤,下面就可以构建完整的约会分类,去找你喜欢的人了:
有了以上步骤,下面就可以构建完整的约会分类,去找你喜欢的人了:
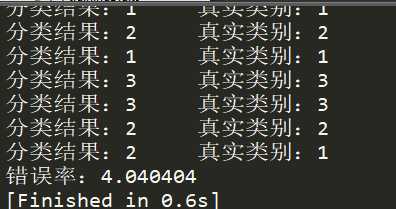
1 from prepareData_1 import file2matrix 2 from dataNormal_3 import autoNorm 3 import operator 4 import numpy as np 5 ‘‘‘ 6 函数说明:knn算法,分类器 7 Parameters: 8 inX - 用于分类的数据(测试集) 9 dataset - 用于训练的数据(训练集) 10 labes - 分类标签 11 k - knn算法参数,选择距离最小的k个点 12 Returns: 13 sortedClassCount[0][0] - 分类结果 14 ‘‘‘ 15 def classify0(inX,dataset,labes,k): 16 dataSetSize = dataset.shape[0] #返回行数 17 diffMat = np.tile(inX,(dataSetSize,1))-dataset 18 sqDiffMat = diffMat**2 19 sqDistances = sqDiffMat.sum(axis=1) 20 distances = sqDistances**0.5 21 sortedDistIndices =distances.argsort() 22 classCount = {} 23 for i in range(k): 24 voteLabel = labes[sortedDistIndices[i]] 25 classCount[voteLabel] = classCount.get(voteLabel,0)+1 26 sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True) 27 return sortedClassCount[0][0] 28 def datingClassTest(): 29 #filename="test.txt" 30 filename = "datingTestSet.txt" 31 datingDataMat,datingLabels = file2matrix(filename) 32 #取所有数据的10% 33 hoRatio = 0.1 34 #数据归一化,返回归一化后的矩阵,数据范围,数据最小值 35 normMat,ranges,minVals = autoNorm(datingDataMat) 36 #获得nornMat的行数 37 m = normMat.shape[0] 38 #百分之十的测试数据的个数 39 numTestVecs = int(m*hoRatio) 40 #分类错误计数 41 errorCount = 0.0 42 43 for i in range(numTestVecs): 44 #前numTestVecs个数据作为测试集,后m-numTestVecs个数据作为训练集 45 classifierResult = classify0(normMat[i,:],normMat[numTestVecs:m,:], 46 datingLabels[numTestVecs:m],10) 47 print ("分类结果:%d \t真实类别:%d"%(classifierResult,datingLabels[i])) 48 if classifierResult != datingLabels[i]: 49 errorCount += 1.0 50 print ("错误率:%f"%(errorCount/float(numTestVecs)*100)) 51 52 if __name__ == ‘__main__‘: 53 datingClassTest()
都是上面的步骤,这里就不解释了,结果如下所示:
2.3 手写数字识别
数据可以样例可以打开文本文件进行查看,其中txt文件名的第一个数字为本txt中的数字,目录trainingDigits中包含了大约2000个例子,每个数字大约有200个样本,testDigits中包含900个测试数据,我们使用trainingDigits中的数据训练分类器,testDigits中的数据作为测试,两组数据没有重合。
数据在这里:https://github.com/Jenny0611/Ml_Learning01
首先我们要将图像数据处理为一个向量,将32*32的二进制图像信息转化为1*1024的向量,再使用前面的分类器,代码如下:
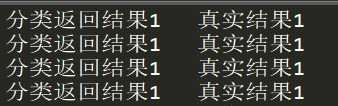
1 import numpy as np 2 import operator 3 from os import listdir 4 from sklearn.neighbors import KNeighborsClassifier as kNN 5 6 ‘‘‘ 7 函数说明:将32*32的二进制图片转换为1*1024向量 8 Parameters: 9 filename - 文件名 10 Returns: 11 returnVect - 返回的二进制图像的1*1024向量 12 ‘‘‘ 13 def img2vector(filename): 14 #创建1*1024的0向量 15 returnVect = np.zeros((1,1024)) 16 fr = open(filename) 17 #按行读取 18 for i in range(32): 19 #读一行数据 20 lineStr=fr.readline() 21 #每一行的前32个数据依次添加到returnVect 22 for j in range(32): 23 returnVect[0,32*i+j]=int(lineStr[j]) 24 return returnVect 25 26 ‘‘‘ 27 函数说明:手写数字分类测试 28 Parameters: 29 filename - 无 30 Returns: 31 returnVect - 无 32 ‘‘‘ 33 def handwritingClassTest(): 34 #测试集的labels 35 hwLabels=[] 36 #返回trainingDigits目录下的文件名 37 trainingFileList=listdir(‘trainingDigits‘) 38 #返回文件夹下文件的个数 39 m=len(trainingFileList) 40 #初始化训练的Mat矩阵的测试集 41 trainingMat=np.zeros((m,1024)) 42 #从文件名中解析出训练集的类别 43 for i in range(m): 44 fileNameStr=trainingFileList[i] 45 classNumber = int(fileNameStr.split(‘_‘)[0]) 46 #将获取的类别添加到hwLabels中 47 hwLabels.append(classNumber) 48 #将每一个文件的1*1024数据存储到trainingMat矩阵中 49 trainingMat[i,:]=img2vector(‘trainingDigits/%s‘%(fileNameStr)) 50 #构建KNN分类器 51 neigh = kNN(n_neighbors=3,algorithm=‘auto‘) 52 #拟合模型,trainingMat为测试矩阵,hwLabels为对应的标签 53 neigh.fit(trainingMat,hwLabels) 54 #返回testDigits目录下的文件列表 55 testFileList=listdir(‘testDigits‘) 56 errorCount=0.0 57 mTest=len(testFileList) 58 #从文件中解析出测试集的类别并进行分类测试 59 for i in range(mTest): 60 fileNameStr=testFileList[i] 61 classNumber=int(fileNameStr.split(‘_‘)[0]) 62 #获得测试集的1*1024向量用于训练 63 vectorUnderTest=img2vector(‘testDigits/%s‘%(fileNameStr)) 64 #获得预测结果 65 classifierResult=neigh.predict(vectorUnderTest) 66 print ("分类返回结果%d\t真实结果%d"%(classifierResult,classNumber)) 67 if (classNumber != classifierResult): 68 errorCount += 1.0 69 print ("总共错了%d个\t错误率为%f%%"%(errorCount,errorCount/mTest*100)) 70 71 if __name__ == ‘__main__‘: 72 handwritingClassTest()
2.4 小结
KNN是简单有效的分类数据算法,在使用时必须有训练样本数据,还要计算距离,如果数据量非常大会非常消耗空间和时间。它的另一个缺陷是无法给出任何数据的基础结构信息,因此我们无法平均实例样本和典型实例样本具体特征,而决策树将使用概率测量方法处理分类问题,以后章节会介绍。
本文参考:http://blog.csdn.net/c406495762/article/details/75172850
《机器学习实战》
标签:学习 print sorted dex als 二维 efault 中标 manager
原文地址:http://www.cnblogs.com/erbaodabao0611/p/7588840.html
