标签:表示 相同 raw branch 思路 als error 没有 不同的
《Deep Residual Learning for Image Recognition》是2016年 kaiming大神CVPR的最佳论文
原文:http://m.blog.csdn.net/justpsss/article/details/77103077
resNet主要解决一个问题,就是更深的神经网络如何收敛的问题,为了解决这个问题,论文提出了一个残差学习的框架。然后简单跟VGG比较了一下,152层的残差网络,比VGG深了8倍,但是比VGG复杂度更低,当然在ImageNet上的表现肯定比VGG更好,是2015年ILSVRC分类任务的冠军。
另外用resNet作为预训练模型的检测和分割效果也要更好,这个比较好理解,分类效果提升必然带来检测和分割的准确性提升。
在resNet之前,随着网络层数的增加,收敛越来越难,大家通常把其原因归结为梯度消失或者梯度爆炸,这是不对的。另外当训练网络的时候,也会有这样一个问题,当网络层数加深的时候,准确率可能会快速的下降,这当然也不是由过拟合导致的。我们可以这样理解,构造一个深度模型,我们把新加的层叫做identity mapping(这个mapping实在不知道怎么翻译好,尴尬……),而其他层从学好的浅层模型复制过来。现在我们需要保证这个构造的深度模型并不会比之前的浅层模型产生更高的训练错误,然而目前并没有好的比较方法。
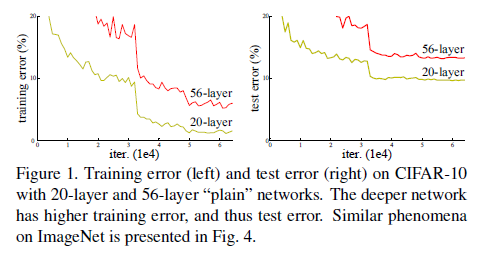
从图上可以看到,层数越多,收敛越慢,且error更高。
在论文中,kaiming大佬提出了一个深度残差学习框架来解决网络加深之后准确率下降的问题。用公式来表示,假如我们需要的理想的mapping定义为H(x),那么我们新加的非线性层就是F(x):=H(x)?x,原始的mapping就从x变成了F(x)+x。也就是说,如果我们之前的x是最优的,那么新加的identity mapping F(x)就应该都是0,而不会是其他的值。
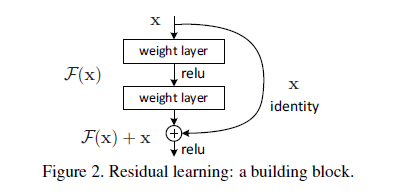
这样整个残差网络是端对端(end-to-end)的,可以通过随机梯度下降反向传播,而且实现起来很简单(实际上就是两层求和,在Caffe中用Eltwise层实现)。至于它为什么收敛更快,error更低,我是这么理解的:
我们知道随机梯度下降就是用的链式求导法则,我们对H(x)求导,相当于对F(x)+x求导,那么这个梯度值就会在1附近(x的导数是1),相比之前的plain网络,自然收敛更快。
假设多个线性和非线性的组合层可以近似任意复杂函数(这是一个开放性的问题),那么当然也可以逼近残差函数H(x)?x(假设输入和输出的维度相同)。
论文中残差模块定义为:
y=F(x,wi)+x
其中,x代表输入,y代表输出,F(x,wi)代表需要学习的残差mapping。像上图firgure 2有两层网络,用F=W2σ(W1x)表示,这里σ表示ReLU激活层。这里Wx是卷积操作,是线性的,ReLU是非线性的。
其中x和F的维度一定要相同,如果不同的话,可以通过一个线性映射Ws来匹配维度:
y=F(x,Wi)+Wsx
这里F是比较灵活的,可以包含两层或者三层,甚至更多层。但是如果只有一层的话,就变成了y=Wix+x,这就是普通的线性函数了,就没有意义了。
接下来就是按照这个思路将网络结构加深了,下面列出几种结构:
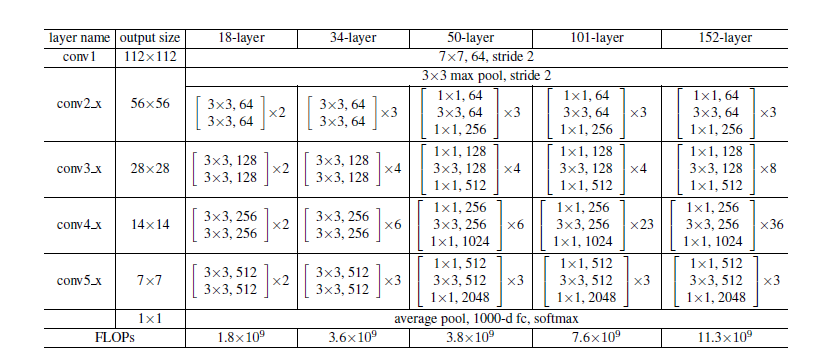
最后是一个更深的瓶颈结构问题,论文中用三个1x1,3x3,1x1的卷积层代替前面说的两个3x3卷积层,第一个1x1用来降低维度,第三个1x1用来增加维度,这样可以保证中间的3x3卷积层拥有比较小的输入输出维度。
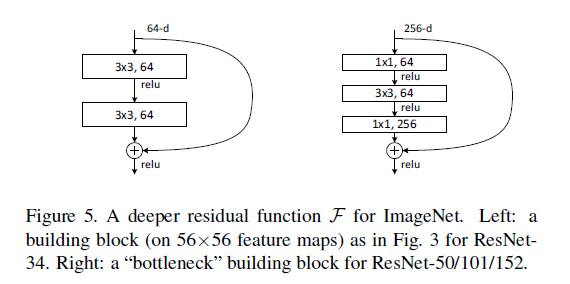
好了,resNet读到这里基本上差不多了,当然啦,后来又出了resNet的加宽版resNeXt,借鉴了GoogLeNet的思想,以后有机会再细读
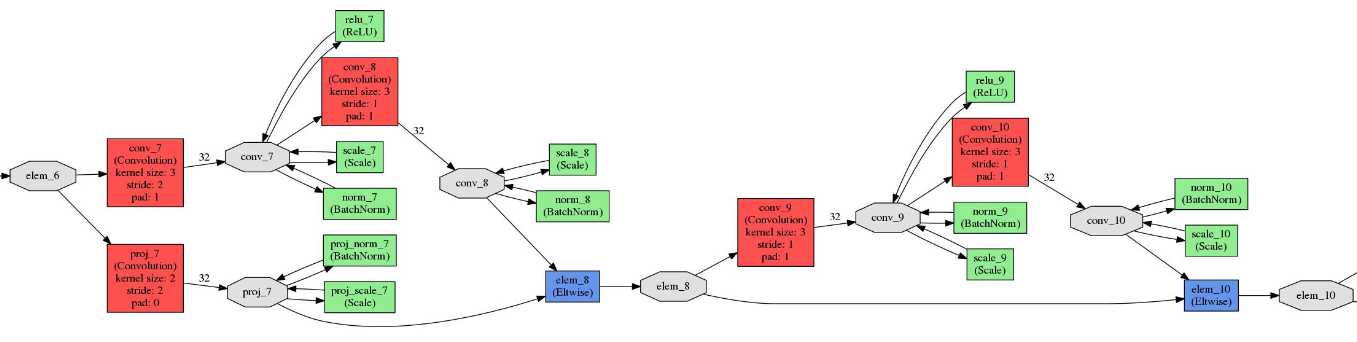
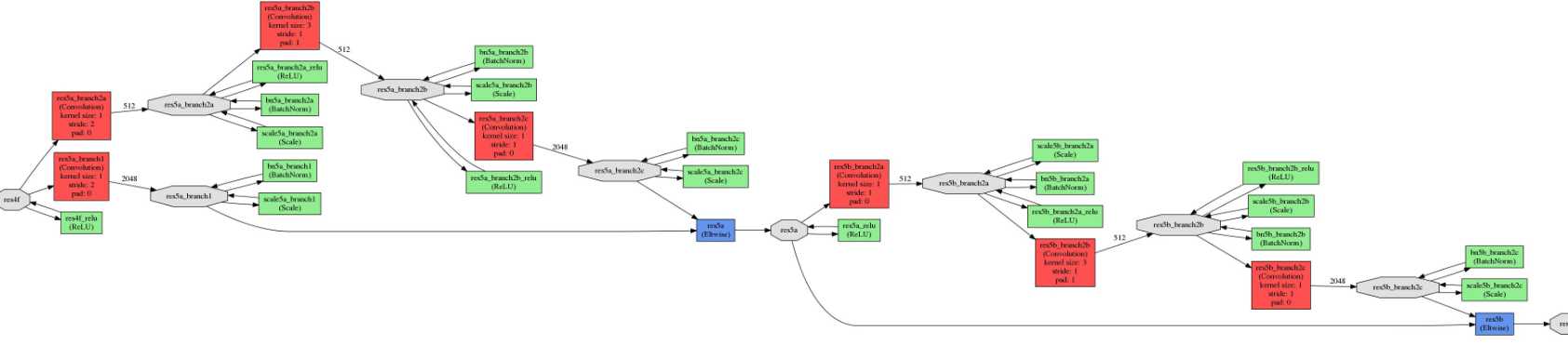
最后附图:ResNet-20 和ResNet-50 模型结构,由于模型太大,图像显示不清晰,这里只黏贴很小的一部分:
name: "resnet20_cifar10" layer { name: "Input1" type: "Input" top: "data" input_param { shape { dim: 1 dim: 3 dim: 32 dim: 32 } } } layer { name: "conv_0" type: "Convolution" bottom: "data" top: "conv_0" param { lr_mult: 1.0 decay_mult: 2.0 } param { lr_mult: 1.0 decay_mult: 0.0 } convolution_param { num_output: 16 pad: 1 kernel_size: 3 stride: 1 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0 } } } layer { name: "norm_0" type: "BatchNorm" bottom: "conv_0" top: "conv_0" param { lr_mult: 0.0 decay_mult: 0.0 } param { lr_mult: 0.0 decay_mult: 0.0 } param { lr_mult: 0.0 decay_mult: 0.0 } batch_norm_param { use_global_stats: true moving_average_fraction: 0.95 } } layer { name: "scale_0" type: "Scale" bottom: "conv_0" top: "conv_0" scale_param { bias_term: true } } layer { name: "relu_0" type: "ReLU" bottom: "conv_0" top: "conv_0" } layer { name: "conv_1" type: "Convolution" bottom: "conv_0" top: "conv_1" param { lr_mult: 1.0 decay_mult: 2.0 } param { lr_mult: 1.0 decay_mult: 0.0 } convolution_param { num_output: 16 pad: 1 kernel_size: 3 stride: 1 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0 } } } layer { name: "norm_1" type: "BatchNorm" bottom: "conv_1" top: "conv_1" param { lr_mult: 0.0 decay_mult: 0.0 } param { lr_mult: 0.0 decay_mult: 0.0 } param { lr_mult: 0.0 decay_mult: 0.0 } batch_norm_param { use_global_stats: true moving_average_fraction: 0.95 } } layer { name: "scale_1" type: "Scale" bottom: "conv_1" top: "conv_1" scale_param { bias_term: true } } layer { name: "relu_1" type: "ReLU" bottom: "conv_1" top: "conv_1" } layer { name: "conv_2" type: "Convolution" bottom: "conv_1" top: "conv_2" param { lr_mult: 1.0 decay_mult: 2.0 } param { lr_mult: 1.0 decay_mult: 0.0 } convolution_param { num_output: 16 pad: 1 kernel_size: 3 stride: 1 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0 } } } layer { name: "norm_2" type: "BatchNorm" bottom: "conv_2" top: "conv_2" param { lr_mult: 0.0 decay_mult: 0.0 } param { lr_mult: 0.0 decay_mult: 0.0 } param { lr_mult: 0.0 decay_mult: 0.0 } batch_norm_param { use_global_stats: true moving_average_fraction: 0.95 } } layer { name: "scale_2" type: "Scale" bottom: "conv_2" top: "conv_2" scale_param { bias_term: true } } layer { name: "elem_2" type: "Eltwise" bottom: "conv_2" bottom: "conv_0" top: "elem_2" eltwise_param { operation: SUM } } layer { name: "conv_3" type: "Convolution" bottom: "elem_2" top: "conv_3" param { lr_mult: 1.0 decay_mult: 2.0 } param { lr_mult: 1.0 decay_mult: 0.0 } convolution_param { num_output: 16 pad: 1 kernel_size: 3 stride: 1 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0 } } } layer { name: "norm_3" type: "BatchNorm" bottom: "conv_3" top: "conv_3" param { lr_mult: 0.0 decay_mult: 0.0 } param { lr_mult: 0.0 decay_mult: 0.0 } param { lr_mult: 0.0 decay_mult: 0.0 } batch_norm_param { use_global_stats: true moving_average_fraction: 0.95 } } layer { name: "scale_3" type: "Scale" bottom: "conv_3" top: "conv_3" scale_param { bias_term: true } } layer { name: "relu_3" type: "ReLU" bottom: "conv_3" top: "conv_3" } layer { name: "conv_4" type: "Convolution" bottom: "conv_3" top: "conv_4" param { lr_mult: 1.0 decay_mult: 2.0 } param { lr_mult: 1.0 decay_mult: 0.0 } convolution_param { num_output: 16 pad: 1 kernel_size: 3 stride: 1 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0 } } } layer { name: "norm_4" type: "BatchNorm" bottom: "conv_4" top: "conv_4" param { lr_mult: 0.0 decay_mult: 0.0 } param { lr_mult: 0.0 decay_mult: 0.0 } param { lr_mult: 0.0 decay_mult: 0.0 } batch_norm_param { use_global_stats: true moving_average_fraction: 0.95 } } layer { name: "scale_4" type: "Scale" bottom: "conv_4" top: "conv_4" scale_param { bias_term: true } } layer { name: "elem_4" type: "Eltwise" bottom: "conv_4" bottom: "elem_2" top: "elem_4" eltwise_param { operation: SUM } } layer { name: "conv_5" type: "Convolution" bottom: "elem_4" top: "conv_5" param { lr_mult: 1.0 decay_mult: 2.0 } param { lr_mult: 1.0 decay_mult: 0.0 } convolution_param { num_output: 16 pad: 1 kernel_size: 3 stride: 1 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0 } } } layer { name: "norm_5" type: "BatchNorm" bottom: "conv_5" top: "conv_5" param { lr_mult: 0.0 decay_mult: 0.0 } param { lr_mult: 0.0 decay_mult: 0.0 } param { lr_mult: 0.0 decay_mult: 0.0 } batch_norm_param { use_global_stats: true moving_average_fraction: 0.95 } } layer { name: "scale_5" type: "Scale" bottom: "conv_5" top: "conv_5" scale_param { bias_term: true } } layer { name: "relu_5" type: "ReLU" bottom: "conv_5" top: "conv_5" } layer { name: "conv_6" type: "Convolution" bottom: "conv_5" top: "conv_6" param { lr_mult: 1.0 decay_mult: 2.0 } param { lr_mult: 1.0 decay_mult: 0.0 } convolution_param { num_output: 16 pad: 1 kernel_size: 3 stride: 1 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0 } } } layer { name: "norm_6" type: "BatchNorm" bottom: "conv_6" top: "conv_6" param { lr_mult: 0.0 decay_mult: 0.0 } param { lr_mult: 0.0 decay_mult: 0.0 } param { lr_mult: 0.0 decay_mult: 0.0 } batch_norm_param { use_global_stats: true moving_average_fraction: 0.95 } } layer { name: "scale_6" type: "Scale" bottom: "conv_6" top: "conv_6" scale_param { bias_term: true } } layer { name: "elem_6" type: "Eltwise" bottom: "conv_6" bottom: "elem_4" top: "elem_6" eltwise_param { operation: SUM } } layer { name: "conv_7" type: "Convolution" bottom: "elem_6" top: "conv_7" param { lr_mult: 1.0 decay_mult: 2.0 } param { lr_mult: 1.0 decay_mult: 0.0 } convolution_param { num_output: 32 pad: 1 kernel_size: 3 stride: 2 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0 } } } layer { name: "norm_7" type: "BatchNorm" bottom: "conv_7" top: "conv_7" param { lr_mult: 0.0 decay_mult: 0.0 } param { lr_mult: 0.0 decay_mult: 0.0 } param { lr_mult: 0.0 decay_mult: 0.0 } batch_norm_param { use_global_stats: true moving_average_fraction: 0.95 } } layer { name: "scale_7" type: "Scale" bottom: "conv_7" top: "conv_7" scale_param { bias_term: true } } layer { name: "relu_7" type: "ReLU" bottom: "conv_7" top: "conv_7" } layer { name: "conv_8" type: "Convolution" bottom: "conv_7" top: "conv_8" param { lr_mult: 1.0 decay_mult: 2.0 } param { lr_mult: 1.0 decay_mult: 0.0 } convolution_param { num_output: 32 pad: 1 kernel_size: 3 stride: 1 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0 } } } layer { name: "norm_8" type: "BatchNorm" bottom: "conv_8" top: "conv_8" param { lr_mult: 0.0 decay_mult: 0.0 } param { lr_mult: 0.0 decay_mult: 0.0 } param { lr_mult: 0.0 decay_mult: 0.0 } batch_norm_param { use_global_stats: true moving_average_fraction: 0.95 } } layer { name: "scale_8" type: "Scale" bottom: "conv_8" top: "conv_8" scale_param { bias_term: true } } layer { name: "proj_7" type: "Convolution" bottom: "elem_6" top: "proj_7" param { lr_mult: 1.0 decay_mult: 2.0 } param { lr_mult: 1.0 decay_mult: 0.0 } convolution_param { num_output: 32 pad: 0 kernel_size: 2 stride: 2 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0 } } } layer { name: "proj_norm_7" type: "BatchNorm" bottom: "proj_7" top: "proj_7" param { lr_mult: 0.0 decay_mult: 0.0 } param { lr_mult: 0.0 decay_mult: 0.0 } param { lr_mult: 0.0 decay_mult: 0.0 } batch_norm_param { use_global_stats: true moving_average_fraction: 0.95 } } layer { name: "proj_scale_7" type: "Scale" bottom: "proj_7" top: "proj_7" scale_param { bias_term: true } } layer { name: "elem_8" type: "Eltwise" bottom: "conv_8" bottom: "proj_7" top: "elem_8" eltwise_param { operation: SUM } } layer { name: "conv_9" type: "Convolution" bottom: "elem_8" top: "conv_9" param { lr_mult: 1.0 decay_mult: 2.0 } param { lr_mult: 1.0 decay_mult: 0.0 } convolution_param { num_output: 32 pad: 1 kernel_size: 3 stride: 1 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0 } } } layer { name: "norm_9" type: "BatchNorm" bottom: "conv_9" top: "conv_9" param { lr_mult: 0.0 decay_mult: 0.0 } param { lr_mult: 0.0 decay_mult: 0.0 } param { lr_mult: 0.0 decay_mult: 0.0 } batch_norm_param { use_global_stats: true moving_average_fraction: 0.95 } } layer { name: "scale_9" type: "Scale" bottom: "conv_9" top: "conv_9" scale_param { bias_term: true } } layer { name: "relu_9" type: "ReLU" bottom: "conv_9" top: "conv_9" } layer { name: "conv_10" type: "Convolution" bottom: "conv_9" top: "conv_10" param { lr_mult: 1.0 decay_mult: 2.0 } param { lr_mult: 1.0 decay_mult: 0.0 } convolution_param { num_output: 32 pad: 1 kernel_size: 3 stride: 1 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0 } } } layer { name: "norm_10" type: "BatchNorm" bottom: "conv_10" top: "conv_10" param { lr_mult: 0.0 decay_mult: 0.0 } param { lr_mult: 0.0 decay_mult: 0.0 } param { lr_mult: 0.0 decay_mult: 0.0 } batch_norm_param { use_global_stats: true moving_average_fraction: 0.95 } } layer { name: "scale_10" type: "Scale" bottom: "conv_10" top: "conv_10" scale_param { bias_term: true } } layer { name: "elem_10" type: "Eltwise" bottom: "conv_10" bottom: "elem_8" top: "elem_10" eltwise_param { operation: SUM } } layer { name: "conv_11" type: "Convolution" bottom: "elem_10" top: "conv_11" param { lr_mult: 1.0 decay_mult: 2.0 } param { lr_mult: 1.0 decay_mult: 0.0 } convolution_param { num_output: 32 pad: 1 kernel_size: 3 stride: 1 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0 } } } layer { name: "norm_11" type: "BatchNorm" bottom: "conv_11" top: "conv_11" param { lr_mult: 0.0 decay_mult: 0.0 } param { lr_mult: 0.0 decay_mult: 0.0 } param { lr_mult: 0.0 decay_mult: 0.0 } batch_norm_param { use_global_stats: true moving_average_fraction: 0.95 } } layer { name: "scale_11" type: "Scale" bottom: "conv_11" top: "conv_11" scale_param { bias_term: true } } layer { name: "relu_11" type: "ReLU" bottom: "conv_11" top: "conv_11" } layer { name: "conv_12" type: "Convolution" bottom: "conv_11" top: "conv_12" param { lr_mult: 1.0 decay_mult: 2.0 } param { lr_mult: 1.0 decay_mult: 0.0 } convolution_param { num_output: 32 pad: 1 kernel_size: 3 stride: 1 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0 } } } layer { name: "norm_12" type: "BatchNorm" bottom: "conv_12" top: "conv_12" param { lr_mult: 0.0 decay_mult: 0.0 } param { lr_mult: 0.0 decay_mult: 0.0 } param { lr_mult: 0.0 decay_mult: 0.0 } batch_norm_param { use_global_stats: true moving_average_fraction: 0.95 } } layer { name: "scale_12" type: "Scale" bottom: "conv_12" top: "conv_12" scale_param { bias_term: true } } layer { name: "elem_12" type: "Eltwise" bottom: "conv_12" bottom: "elem_10" top: "elem_12" eltwise_param { operation: SUM } } layer { name: "conv_13" type: "Convolution" bottom: "elem_12" top: "conv_13" param { lr_mult: 1.0 decay_mult: 2.0 } param { lr_mult: 1.0 decay_mult: 0.0 } convolution_param { num_output: 64 pad: 1 kernel_size: 3 stride: 2 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0 } } } layer { name: "norm_13" type: "BatchNorm" bottom: "conv_13" top: "conv_13" param { lr_mult: 0.0 decay_mult: 0.0 } param { lr_mult: 0.0 decay_mult: 0.0 } param { lr_mult: 0.0 decay_mult: 0.0 } batch_norm_param { use_global_stats: true moving_average_fraction: 0.95 } } layer { name: "scale_13" type: "Scale" bottom: "conv_13" top: "conv_13" scale_param { bias_term: true } } layer { name: "relu_13" type: "ReLU" bottom: "conv_13" top: "conv_13" } layer { name: "conv_14" type: "Convolution" bottom: "conv_13" top: "conv_14" param { lr_mult: 1.0 decay_mult: 2.0 } param { lr_mult: 1.0 decay_mult: 0.0 } convolution_param { num_output: 64 pad: 1 kernel_size: 3 stride: 1 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0 } } } layer { name: "norm_14" type: "BatchNorm" bottom: "conv_14" top: "conv_14" param { lr_mult: 0.0 decay_mult: 0.0 } param { lr_mult: 0.0 decay_mult: 0.0 } param { lr_mult: 0.0 decay_mult: 0.0 } batch_norm_param { use_global_stats: true moving_average_fraction: 0.95 } } layer { name: "scale_14" type: "Scale" bottom: "conv_14" top: "conv_14" scale_param { bias_term: true } } layer { name: "proj_13" type: "Convolution" bottom: "elem_12" top: "proj_13" param { lr_mult: 1.0 decay_mult: 2.0 } param { lr_mult: 1.0 decay_mult: 0.0 } convolution_param { num_output: 64 pad: 0 kernel_size: 2 stride: 2 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0 } } } layer { name: "proj_norm_13" type: "BatchNorm" bottom: "proj_13" top: "proj_13" param { lr_mult: 0.0 decay_mult: 0.0 } param { lr_mult: 0.0 decay_mult: 0.0 } param { lr_mult: 0.0 decay_mult: 0.0 } batch_norm_param { use_global_stats: true moving_average_fraction: 0.95 } } layer { name: "proj_scale_13" type: "Scale" bottom: "proj_13" top: "proj_13" scale_param { bias_term: true } } layer { name: "elem_14" type: "Eltwise" bottom: "conv_14" bottom: "proj_13" top: "elem_14" eltwise_param { operation: SUM } } layer { name: "conv_15" type: "Convolution" bottom: "elem_14" top: "conv_15" param { lr_mult: 1.0 decay_mult: 2.0 } param { lr_mult: 1.0 decay_mult: 0.0 } convolution_param { num_output: 64 pad: 1 kernel_size: 3 stride: 1 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0 } } } layer { name: "norm_15" type: "BatchNorm" bottom: "conv_15" top: "conv_15" param { lr_mult: 0.0 decay_mult: 0.0 } param { lr_mult: 0.0 decay_mult: 0.0 } param { lr_mult: 0.0 decay_mult: 0.0 } batch_norm_param { use_global_stats: true moving_average_fraction: 0.95 } } layer { name: "scale_15" type: "Scale" bottom: "conv_15" top: "conv_15" scale_param { bias_term: true } } layer { name: "relu_15" type: "ReLU" bottom: "conv_15" top: "conv_15" } layer { name: "conv_16" type: "Convolution" bottom: "conv_15" top: "conv_16" param { lr_mult: 1.0 decay_mult: 2.0 } param { lr_mult: 1.0 decay_mult: 0.0 } convolution_param { num_output: 64 pad: 1 kernel_size: 3 stride: 1 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0 } } } layer { name: "norm_16" type: "BatchNorm" bottom: "conv_16" top: "conv_16" param { lr_mult: 0.0 decay_mult: 0.0 } param { lr_mult: 0.0 decay_mult: 0.0 } param { lr_mult: 0.0 decay_mult: 0.0 } batch_norm_param { use_global_stats: true moving_average_fraction: 0.95 } } layer { name: "scale_16" type: "Scale" bottom: "conv_16" top: "conv_16" scale_param { bias_term: true } } layer { name: "elem_16" type: "Eltwise" bottom: "conv_16" bottom: "elem_14" top: "elem_16" eltwise_param { operation: SUM } } layer { name: "conv_17" type: "Convolution" bottom: "elem_16" top: "conv_17" param { lr_mult: 1.0 decay_mult: 2.0 } param { lr_mult: 1.0 decay_mult: 0.0 } convolution_param { num_output: 64 pad: 1 kernel_size: 3 stride: 1 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0 } } } layer { name: "norm_17" type: "BatchNorm" bottom: "conv_17" top: "conv_17" param { lr_mult: 0.0 decay_mult: 0.0 } param { lr_mult: 0.0 decay_mult: 0.0 } param { lr_mult: 0.0 decay_mult: 0.0 } batch_norm_param { use_global_stats: true moving_average_fraction: 0.95 } } layer { name: "scale_17" type: "Scale" bottom: "conv_17" top: "conv_17" scale_param { bias_term: true } } layer { name: "relu_17" type: "ReLU" bottom: "conv_17" top: "conv_17" } layer { name: "conv_18" type: "Convolution" bottom: "conv_17" top: "conv_18" param { lr_mult: 1.0 decay_mult: 2.0 } param { lr_mult: 1.0 decay_mult: 0.0 } convolution_param { num_output: 64 pad: 1 kernel_size: 3 stride: 1 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0 } } } layer { name: "norm_18" type: "BatchNorm" bottom: "conv_18" top: "conv_18" param { lr_mult: 0.0 decay_mult: 0.0 } param { lr_mult: 0.0 decay_mult: 0.0 } param { lr_mult: 0.0 decay_mult: 0.0 } batch_norm_param { use_global_stats: true moving_average_fraction: 0.95 } } layer { name: "scale_18" type: "Scale" bottom: "conv_18" top: "conv_18" scale_param { bias_term: true } } layer { name: "elem_18" type: "Eltwise" bottom: "conv_18" bottom: "elem_16" top: "elem_18" eltwise_param { operation: SUM } } layer { name: "pool_19" type: "Pooling" bottom: "elem_18" top: "pool_19" pooling_param { pool: AVE global_pooling: true } } layer { name: "fc_19" type: "InnerProduct" bottom: "pool_19" top: "fc_19" param { lr_mult: 1.0 decay_mult: 2.0 } param { lr_mult: 1.0 decay_mult: 0.0 } inner_product_param { num_output: 10 weight_filler { type: "xavier" } bias_filler { type: "constant" value: 0 } } }
name: "ResNet-50" input: "data" input_dim: 1 input_dim: 3 input_dim: 224 input_dim: 224 layer { bottom: "data" top: "conv1" name: "conv1" type: "Convolution" convolution_param { num_output: 64 kernel_size: 7 pad: 3 stride: 2 } } layer { bottom: "conv1" top: "conv1" name: "bn_conv1" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "conv1" top: "conv1" name: "scale_conv1" type: "Scale" scale_param { bias_term: true } } layer { bottom: "conv1" top: "conv1" name: "conv1_relu" type: "ReLU" } layer { bottom: "conv1" top: "pool1" name: "pool1" type: "Pooling" pooling_param { kernel_size: 3 stride: 2 pool: MAX } } layer { bottom: "pool1" top: "res2a_branch1" name: "res2a_branch1" type: "Convolution" convolution_param { num_output: 256 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res2a_branch1" top: "res2a_branch1" name: "bn2a_branch1" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res2a_branch1" top: "res2a_branch1" name: "scale2a_branch1" type: "Scale" scale_param { bias_term: true } } layer { bottom: "pool1" top: "res2a_branch2a" name: "res2a_branch2a" type: "Convolution" convolution_param { num_output: 64 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res2a_branch2a" top: "res2a_branch2a" name: "bn2a_branch2a" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res2a_branch2a" top: "res2a_branch2a" name: "scale2a_branch2a" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res2a_branch2a" top: "res2a_branch2a" name: "res2a_branch2a_relu" type: "ReLU" } layer { bottom: "res2a_branch2a" top: "res2a_branch2b" name: "res2a_branch2b" type: "Convolution" convolution_param { num_output: 64 kernel_size: 3 pad: 1 stride: 1 bias_term: false } } layer { bottom: "res2a_branch2b" top: "res2a_branch2b" name: "bn2a_branch2b" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res2a_branch2b" top: "res2a_branch2b" name: "scale2a_branch2b" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res2a_branch2b" top: "res2a_branch2b" name: "res2a_branch2b_relu" type: "ReLU" } layer { bottom: "res2a_branch2b" top: "res2a_branch2c" name: "res2a_branch2c" type: "Convolution" convolution_param { num_output: 256 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res2a_branch2c" top: "res2a_branch2c" name: "bn2a_branch2c" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res2a_branch2c" top: "res2a_branch2c" name: "scale2a_branch2c" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res2a_branch1" bottom: "res2a_branch2c" top: "res2a" name: "res2a" type: "Eltwise" } layer { bottom: "res2a" top: "res2a" name: "res2a_relu" type: "ReLU" } layer { bottom: "res2a" top: "res2b_branch2a" name: "res2b_branch2a" type: "Convolution" convolution_param { num_output: 64 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res2b_branch2a" top: "res2b_branch2a" name: "bn2b_branch2a" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res2b_branch2a" top: "res2b_branch2a" name: "scale2b_branch2a" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res2b_branch2a" top: "res2b_branch2a" name: "res2b_branch2a_relu" type: "ReLU" } layer { bottom: "res2b_branch2a" top: "res2b_branch2b" name: "res2b_branch2b" type: "Convolution" convolution_param { num_output: 64 kernel_size: 3 pad: 1 stride: 1 bias_term: false } } layer { bottom: "res2b_branch2b" top: "res2b_branch2b" name: "bn2b_branch2b" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res2b_branch2b" top: "res2b_branch2b" name: "scale2b_branch2b" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res2b_branch2b" top: "res2b_branch2b" name: "res2b_branch2b_relu" type: "ReLU" } layer { bottom: "res2b_branch2b" top: "res2b_branch2c" name: "res2b_branch2c" type: "Convolution" convolution_param { num_output: 256 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res2b_branch2c" top: "res2b_branch2c" name: "bn2b_branch2c" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res2b_branch2c" top: "res2b_branch2c" name: "scale2b_branch2c" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res2a" bottom: "res2b_branch2c" top: "res2b" name: "res2b" type: "Eltwise" } layer { bottom: "res2b" top: "res2b" name: "res2b_relu" type: "ReLU" } layer { bottom: "res2b" top: "res2c_branch2a" name: "res2c_branch2a" type: "Convolution" convolution_param { num_output: 64 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res2c_branch2a" top: "res2c_branch2a" name: "bn2c_branch2a" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res2c_branch2a" top: "res2c_branch2a" name: "scale2c_branch2a" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res2c_branch2a" top: "res2c_branch2a" name: "res2c_branch2a_relu" type: "ReLU" } layer { bottom: "res2c_branch2a" top: "res2c_branch2b" name: "res2c_branch2b" type: "Convolution" convolution_param { num_output: 64 kernel_size: 3 pad: 1 stride: 1 bias_term: false } } layer { bottom: "res2c_branch2b" top: "res2c_branch2b" name: "bn2c_branch2b" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res2c_branch2b" top: "res2c_branch2b" name: "scale2c_branch2b" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res2c_branch2b" top: "res2c_branch2b" name: "res2c_branch2b_relu" type: "ReLU" } layer { bottom: "res2c_branch2b" top: "res2c_branch2c" name: "res2c_branch2c" type: "Convolution" convolution_param { num_output: 256 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res2c_branch2c" top: "res2c_branch2c" name: "bn2c_branch2c" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res2c_branch2c" top: "res2c_branch2c" name: "scale2c_branch2c" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res2b" bottom: "res2c_branch2c" top: "res2c" name: "res2c" type: "Eltwise" } layer { bottom: "res2c" top: "res2c" name: "res2c_relu" type: "ReLU" } layer { bottom: "res2c" top: "res3a_branch1" name: "res3a_branch1" type: "Convolution" convolution_param { num_output: 512 kernel_size: 1 pad: 0 stride: 2 bias_term: false } } layer { bottom: "res3a_branch1" top: "res3a_branch1" name: "bn3a_branch1" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res3a_branch1" top: "res3a_branch1" name: "scale3a_branch1" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res2c" top: "res3a_branch2a" name: "res3a_branch2a" type: "Convolution" convolution_param { num_output: 128 kernel_size: 1 pad: 0 stride: 2 bias_term: false } } layer { bottom: "res3a_branch2a" top: "res3a_branch2a" name: "bn3a_branch2a" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res3a_branch2a" top: "res3a_branch2a" name: "scale3a_branch2a" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res3a_branch2a" top: "res3a_branch2a" name: "res3a_branch2a_relu" type: "ReLU" } layer { bottom: "res3a_branch2a" top: "res3a_branch2b" name: "res3a_branch2b" type: "Convolution" convolution_param { num_output: 128 kernel_size: 3 pad: 1 stride: 1 bias_term: false } } layer { bottom: "res3a_branch2b" top: "res3a_branch2b" name: "bn3a_branch2b" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res3a_branch2b" top: "res3a_branch2b" name: "scale3a_branch2b" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res3a_branch2b" top: "res3a_branch2b" name: "res3a_branch2b_relu" type: "ReLU" } layer { bottom: "res3a_branch2b" top: "res3a_branch2c" name: "res3a_branch2c" type: "Convolution" convolution_param { num_output: 512 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res3a_branch2c" top: "res3a_branch2c" name: "bn3a_branch2c" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res3a_branch2c" top: "res3a_branch2c" name: "scale3a_branch2c" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res3a_branch1" bottom: "res3a_branch2c" top: "res3a" name: "res3a" type: "Eltwise" } layer { bottom: "res3a" top: "res3a" name: "res3a_relu" type: "ReLU" } layer { bottom: "res3a" top: "res3b_branch2a" name: "res3b_branch2a" type: "Convolution" convolution_param { num_output: 128 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res3b_branch2a" top: "res3b_branch2a" name: "bn3b_branch2a" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res3b_branch2a" top: "res3b_branch2a" name: "scale3b_branch2a" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res3b_branch2a" top: "res3b_branch2a" name: "res3b_branch2a_relu" type: "ReLU" } layer { bottom: "res3b_branch2a" top: "res3b_branch2b" name: "res3b_branch2b" type: "Convolution" convolution_param { num_output: 128 kernel_size: 3 pad: 1 stride: 1 bias_term: false } } layer { bottom: "res3b_branch2b" top: "res3b_branch2b" name: "bn3b_branch2b" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res3b_branch2b" top: "res3b_branch2b" name: "scale3b_branch2b" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res3b_branch2b" top: "res3b_branch2b" name: "res3b_branch2b_relu" type: "ReLU" } layer { bottom: "res3b_branch2b" top: "res3b_branch2c" name: "res3b_branch2c" type: "Convolution" convolution_param { num_output: 512 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res3b_branch2c" top: "res3b_branch2c" name: "bn3b_branch2c" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res3b_branch2c" top: "res3b_branch2c" name: "scale3b_branch2c" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res3a" bottom: "res3b_branch2c" top: "res3b" name: "res3b" type: "Eltwise" } layer { bottom: "res3b" top: "res3b" name: "res3b_relu" type: "ReLU" } layer { bottom: "res3b" top: "res3c_branch2a" name: "res3c_branch2a" type: "Convolution" convolution_param { num_output: 128 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res3c_branch2a" top: "res3c_branch2a" name: "bn3c_branch2a" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res3c_branch2a" top: "res3c_branch2a" name: "scale3c_branch2a" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res3c_branch2a" top: "res3c_branch2a" name: "res3c_branch2a_relu" type: "ReLU" } layer { bottom: "res3c_branch2a" top: "res3c_branch2b" name: "res3c_branch2b" type: "Convolution" convolution_param { num_output: 128 kernel_size: 3 pad: 1 stride: 1 bias_term: false } } layer { bottom: "res3c_branch2b" top: "res3c_branch2b" name: "bn3c_branch2b" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res3c_branch2b" top: "res3c_branch2b" name: "scale3c_branch2b" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res3c_branch2b" top: "res3c_branch2b" name: "res3c_branch2b_relu" type: "ReLU" } layer { bottom: "res3c_branch2b" top: "res3c_branch2c" name: "res3c_branch2c" type: "Convolution" convolution_param { num_output: 512 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res3c_branch2c" top: "res3c_branch2c" name: "bn3c_branch2c" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res3c_branch2c" top: "res3c_branch2c" name: "scale3c_branch2c" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res3b" bottom: "res3c_branch2c" top: "res3c" name: "res3c" type: "Eltwise" } layer { bottom: "res3c" top: "res3c" name: "res3c_relu" type: "ReLU" } layer { bottom: "res3c" top: "res3d_branch2a" name: "res3d_branch2a" type: "Convolution" convolution_param { num_output: 128 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res3d_branch2a" top: "res3d_branch2a" name: "bn3d_branch2a" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res3d_branch2a" top: "res3d_branch2a" name: "scale3d_branch2a" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res3d_branch2a" top: "res3d_branch2a" name: "res3d_branch2a_relu" type: "ReLU" } layer { bottom: "res3d_branch2a" top: "res3d_branch2b" name: "res3d_branch2b" type: "Convolution" convolution_param { num_output: 128 kernel_size: 3 pad: 1 stride: 1 bias_term: false } } layer { bottom: "res3d_branch2b" top: "res3d_branch2b" name: "bn3d_branch2b" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res3d_branch2b" top: "res3d_branch2b" name: "scale3d_branch2b" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res3d_branch2b" top: "res3d_branch2b" name: "res3d_branch2b_relu" type: "ReLU" } layer { bottom: "res3d_branch2b" top: "res3d_branch2c" name: "res3d_branch2c" type: "Convolution" convolution_param { num_output: 512 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res3d_branch2c" top: "res3d_branch2c" name: "bn3d_branch2c" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res3d_branch2c" top: "res3d_branch2c" name: "scale3d_branch2c" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res3c" bottom: "res3d_branch2c" top: "res3d" name: "res3d" type: "Eltwise" } layer { bottom: "res3d" top: "res3d" name: "res3d_relu" type: "ReLU" } layer { bottom: "res3d" top: "res4a_branch1" name: "res4a_branch1" type: "Convolution" convolution_param { num_output: 1024 kernel_size: 1 pad: 0 stride: 2 bias_term: false } } layer { bottom: "res4a_branch1" top: "res4a_branch1" name: "bn4a_branch1" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res4a_branch1" top: "res4a_branch1" name: "scale4a_branch1" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res3d" top: "res4a_branch2a" name: "res4a_branch2a" type: "Convolution" convolution_param { num_output: 256 kernel_size: 1 pad: 0 stride: 2 bias_term: false } } layer { bottom: "res4a_branch2a" top: "res4a_branch2a" name: "bn4a_branch2a" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res4a_branch2a" top: "res4a_branch2a" name: "scale4a_branch2a" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res4a_branch2a" top: "res4a_branch2a" name: "res4a_branch2a_relu" type: "ReLU" } layer { bottom: "res4a_branch2a" top: "res4a_branch2b" name: "res4a_branch2b" type: "Convolution" convolution_param { num_output: 256 kernel_size: 3 pad: 1 stride: 1 bias_term: false } } layer { bottom: "res4a_branch2b" top: "res4a_branch2b" name: "bn4a_branch2b" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res4a_branch2b" top: "res4a_branch2b" name: "scale4a_branch2b" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res4a_branch2b" top: "res4a_branch2b" name: "res4a_branch2b_relu" type: "ReLU" } layer { bottom: "res4a_branch2b" top: "res4a_branch2c" name: "res4a_branch2c" type: "Convolution" convolution_param { num_output: 1024 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res4a_branch2c" top: "res4a_branch2c" name: "bn4a_branch2c" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res4a_branch2c" top: "res4a_branch2c" name: "scale4a_branch2c" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res4a_branch1" bottom: "res4a_branch2c" top: "res4a" name: "res4a" type: "Eltwise" } layer { bottom: "res4a" top: "res4a" name: "res4a_relu" type: "ReLU" } layer { bottom: "res4a" top: "res4b_branch2a" name: "res4b_branch2a" type: "Convolution" convolution_param { num_output: 256 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res4b_branch2a" top: "res4b_branch2a" name: "bn4b_branch2a" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res4b_branch2a" top: "res4b_branch2a" name: "scale4b_branch2a" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res4b_branch2a" top: "res4b_branch2a" name: "res4b_branch2a_relu" type: "ReLU" } layer { bottom: "res4b_branch2a" top: "res4b_branch2b" name: "res4b_branch2b" type: "Convolution" convolution_param { num_output: 256 kernel_size: 3 pad: 1 stride: 1 bias_term: false } } layer { bottom: "res4b_branch2b" top: "res4b_branch2b" name: "bn4b_branch2b" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res4b_branch2b" top: "res4b_branch2b" name: "scale4b_branch2b" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res4b_branch2b" top: "res4b_branch2b" name: "res4b_branch2b_relu" type: "ReLU" } layer { bottom: "res4b_branch2b" top: "res4b_branch2c" name: "res4b_branch2c" type: "Convolution" convolution_param { num_output: 1024 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res4b_branch2c" top: "res4b_branch2c" name: "bn4b_branch2c" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res4b_branch2c" top: "res4b_branch2c" name: "scale4b_branch2c" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res4a" bottom: "res4b_branch2c" top: "res4b" name: "res4b" type: "Eltwise" } layer { bottom: "res4b" top: "res4b" name: "res4b_relu" type: "ReLU" } layer { bottom: "res4b" top: "res4c_branch2a" name: "res4c_branch2a" type: "Convolution" convolution_param { num_output: 256 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res4c_branch2a" top: "res4c_branch2a" name: "bn4c_branch2a" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res4c_branch2a" top: "res4c_branch2a" name: "scale4c_branch2a" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res4c_branch2a" top: "res4c_branch2a" name: "res4c_branch2a_relu" type: "ReLU" } layer { bottom: "res4c_branch2a" top: "res4c_branch2b" name: "res4c_branch2b" type: "Convolution" convolution_param { num_output: 256 kernel_size: 3 pad: 1 stride: 1 bias_term: false } } layer { bottom: "res4c_branch2b" top: "res4c_branch2b" name: "bn4c_branch2b" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res4c_branch2b" top: "res4c_branch2b" name: "scale4c_branch2b" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res4c_branch2b" top: "res4c_branch2b" name: "res4c_branch2b_relu" type: "ReLU" } layer { bottom: "res4c_branch2b" top: "res4c_branch2c" name: "res4c_branch2c" type: "Convolution" convolution_param { num_output: 1024 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res4c_branch2c" top: "res4c_branch2c" name: "bn4c_branch2c" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res4c_branch2c" top: "res4c_branch2c" name: "scale4c_branch2c" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res4b" bottom: "res4c_branch2c" top: "res4c" name: "res4c" type: "Eltwise" } layer { bottom: "res4c" top: "res4c" name: "res4c_relu" type: "ReLU" } layer { bottom: "res4c" top: "res4d_branch2a" name: "res4d_branch2a" type: "Convolution" convolution_param { num_output: 256 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res4d_branch2a" top: "res4d_branch2a" name: "bn4d_branch2a" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res4d_branch2a" top: "res4d_branch2a" name: "scale4d_branch2a" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res4d_branch2a" top: "res4d_branch2a" name: "res4d_branch2a_relu" type: "ReLU" } layer { bottom: "res4d_branch2a" top: "res4d_branch2b" name: "res4d_branch2b" type: "Convolution" convolution_param { num_output: 256 kernel_size: 3 pad: 1 stride: 1 bias_term: false } } layer { bottom: "res4d_branch2b" top: "res4d_branch2b" name: "bn4d_branch2b" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res4d_branch2b" top: "res4d_branch2b" name: "scale4d_branch2b" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res4d_branch2b" top: "res4d_branch2b" name: "res4d_branch2b_relu" type: "ReLU" } layer { bottom: "res4d_branch2b" top: "res4d_branch2c" name: "res4d_branch2c" type: "Convolution" convolution_param { num_output: 1024 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res4d_branch2c" top: "res4d_branch2c" name: "bn4d_branch2c" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res4d_branch2c" top: "res4d_branch2c" name: "scale4d_branch2c" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res4c" bottom: "res4d_branch2c" top: "res4d" name: "res4d" type: "Eltwise" } layer { bottom: "res4d" top: "res4d" name: "res4d_relu" type: "ReLU" } layer { bottom: "res4d" top: "res4e_branch2a" name: "res4e_branch2a" type: "Convolution" convolution_param { num_output: 256 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res4e_branch2a" top: "res4e_branch2a" name: "bn4e_branch2a" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res4e_branch2a" top: "res4e_branch2a" name: "scale4e_branch2a" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res4e_branch2a" top: "res4e_branch2a" name: "res4e_branch2a_relu" type: "ReLU" } layer { bottom: "res4e_branch2a" top: "res4e_branch2b" name: "res4e_branch2b" type: "Convolution" convolution_param { num_output: 256 kernel_size: 3 pad: 1 stride: 1 bias_term: false } } layer { bottom: "res4e_branch2b" top: "res4e_branch2b" name: "bn4e_branch2b" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res4e_branch2b" top: "res4e_branch2b" name: "scale4e_branch2b" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res4e_branch2b" top: "res4e_branch2b" name: "res4e_branch2b_relu" type: "ReLU" } layer { bottom: "res4e_branch2b" top: "res4e_branch2c" name: "res4e_branch2c" type: "Convolution" convolution_param { num_output: 1024 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res4e_branch2c" top: "res4e_branch2c" name: "bn4e_branch2c" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res4e_branch2c" top: "res4e_branch2c" name: "scale4e_branch2c" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res4d" bottom: "res4e_branch2c" top: "res4e" name: "res4e" type: "Eltwise" } layer { bottom: "res4e" top: "res4e" name: "res4e_relu" type: "ReLU" } layer { bottom: "res4e" top: "res4f_branch2a" name: "res4f_branch2a" type: "Convolution" convolution_param { num_output: 256 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res4f_branch2a" top: "res4f_branch2a" name: "bn4f_branch2a" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res4f_branch2a" top: "res4f_branch2a" name: "scale4f_branch2a" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res4f_branch2a" top: "res4f_branch2a" name: "res4f_branch2a_relu" type: "ReLU" } layer { bottom: "res4f_branch2a" top: "res4f_branch2b" name: "res4f_branch2b" type: "Convolution" convolution_param { num_output: 256 kernel_size: 3 pad: 1 stride: 1 bias_term: false } } layer { bottom: "res4f_branch2b" top: "res4f_branch2b" name: "bn4f_branch2b" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res4f_branch2b" top: "res4f_branch2b" name: "scale4f_branch2b" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res4f_branch2b" top: "res4f_branch2b" name: "res4f_branch2b_relu" type: "ReLU" } layer { bottom: "res4f_branch2b" top: "res4f_branch2c" name: "res4f_branch2c" type: "Convolution" convolution_param { num_output: 1024 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res4f_branch2c" top: "res4f_branch2c" name: "bn4f_branch2c" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res4f_branch2c" top: "res4f_branch2c" name: "scale4f_branch2c" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res4e" bottom: "res4f_branch2c" top: "res4f" name: "res4f" type: "Eltwise" } layer { bottom: "res4f" top: "res4f" name: "res4f_relu" type: "ReLU" } layer { bottom: "res4f" top: "res5a_branch1" name: "res5a_branch1" type: "Convolution" convolution_param { num_output: 2048 kernel_size: 1 pad: 0 stride: 2 bias_term: false } } layer { bottom: "res5a_branch1" top: "res5a_branch1" name: "bn5a_branch1" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res5a_branch1" top: "res5a_branch1" name: "scale5a_branch1" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res4f" top: "res5a_branch2a" name: "res5a_branch2a" type: "Convolution" convolution_param { num_output: 512 kernel_size: 1 pad: 0 stride: 2 bias_term: false } } layer { bottom: "res5a_branch2a" top: "res5a_branch2a" name: "bn5a_branch2a" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res5a_branch2a" top: "res5a_branch2a" name: "scale5a_branch2a" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res5a_branch2a" top: "res5a_branch2a" name: "res5a_branch2a_relu" type: "ReLU" } layer { bottom: "res5a_branch2a" top: "res5a_branch2b" name: "res5a_branch2b" type: "Convolution" convolution_param { num_output: 512 kernel_size: 3 pad: 1 stride: 1 bias_term: false } } layer { bottom: "res5a_branch2b" top: "res5a_branch2b" name: "bn5a_branch2b" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res5a_branch2b" top: "res5a_branch2b" name: "scale5a_branch2b" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res5a_branch2b" top: "res5a_branch2b" name: "res5a_branch2b_relu" type: "ReLU" } layer { bottom: "res5a_branch2b" top: "res5a_branch2c" name: "res5a_branch2c" type: "Convolution" convolution_param { num_output: 2048 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res5a_branch2c" top: "res5a_branch2c" name: "bn5a_branch2c" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res5a_branch2c" top: "res5a_branch2c" name: "scale5a_branch2c" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res5a_branch1" bottom: "res5a_branch2c" top: "res5a" name: "res5a" type: "Eltwise" } layer { bottom: "res5a" top: "res5a" name: "res5a_relu" type: "ReLU" } layer { bottom: "res5a" top: "res5b_branch2a" name: "res5b_branch2a" type: "Convolution" convolution_param { num_output: 512 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res5b_branch2a" top: "res5b_branch2a" name: "bn5b_branch2a" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res5b_branch2a" top: "res5b_branch2a" name: "scale5b_branch2a" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res5b_branch2a" top: "res5b_branch2a" name: "res5b_branch2a_relu" type: "ReLU" } layer { bottom: "res5b_branch2a" top: "res5b_branch2b" name: "res5b_branch2b" type: "Convolution" convolution_param { num_output: 512 kernel_size: 3 pad: 1 stride: 1 bias_term: false } } layer { bottom: "res5b_branch2b" top: "res5b_branch2b" name: "bn5b_branch2b" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res5b_branch2b" top: "res5b_branch2b" name: "scale5b_branch2b" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res5b_branch2b" top: "res5b_branch2b" name: "res5b_branch2b_relu" type: "ReLU" } layer { bottom: "res5b_branch2b" top: "res5b_branch2c" name: "res5b_branch2c" type: "Convolution" convolution_param { num_output: 2048 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res5b_branch2c" top: "res5b_branch2c" name: "bn5b_branch2c" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res5b_branch2c" top: "res5b_branch2c" name: "scale5b_branch2c" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res5a" bottom: "res5b_branch2c" top: "res5b" name: "res5b" type: "Eltwise" } layer { bottom: "res5b" top: "res5b" name: "res5b_relu" type: "ReLU" } layer { bottom: "res5b" top: "res5c_branch2a" name: "res5c_branch2a" type: "Convolution" convolution_param { num_output: 512 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res5c_branch2a" top: "res5c_branch2a" name: "bn5c_branch2a" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res5c_branch2a" top: "res5c_branch2a" name: "scale5c_branch2a" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res5c_branch2a" top: "res5c_branch2a" name: "res5c_branch2a_relu" type: "ReLU" } layer { bottom: "res5c_branch2a" top: "res5c_branch2b" name: "res5c_branch2b" type: "Convolution" convolution_param { num_output: 512 kernel_size: 3 pad: 1 stride: 1 bias_term: false } } layer { bottom: "res5c_branch2b" top: "res5c_branch2b" name: "bn5c_branch2b" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res5c_branch2b" top: "res5c_branch2b" name: "scale5c_branch2b" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res5c_branch2b" top: "res5c_branch2b" name: "res5c_branch2b_relu" type: "ReLU" } layer { bottom: "res5c_branch2b" top: "res5c_branch2c" name: "res5c_branch2c" type: "Convolution" convolution_param { num_output: 2048 kernel_size: 1 pad: 0 stride: 1 bias_term: false } } layer { bottom: "res5c_branch2c" top: "res5c_branch2c" name: "bn5c_branch2c" type: "BatchNorm" batch_norm_param { use_global_stats: true } } layer { bottom: "res5c_branch2c" top: "res5c_branch2c" name: "scale5c_branch2c" type: "Scale" scale_param { bias_term: true } } layer { bottom: "res5b" bottom: "res5c_branch2c" top: "res5c" name: "res5c" type: "Eltwise" } layer { bottom: "res5c" top: "res5c" name: "res5c_relu" type: "ReLU" } layer { bottom: "res5c" top: "pool5" name: "pool5" type: "Pooling" pooling_param { kernel_size: 7 stride: 1 pool: AVE } } layer { bottom: "pool5" top: "fc1000" name: "fc1000" type: "InnerProduct" inner_product_param { num_output: 1000 } } layer { bottom: "fc1000" top: "prob" name: "prob" type: "Softmax" }
标签:表示 相同 raw branch 思路 als error 没有 不同的
原文地址:http://www.cnblogs.com/hansjorn/p/7592649.html