标签:连接 取字符串 bst 类加载 循环调用 sys mat 注册 java
原文地址:http://blog.csdn.net/xieyuooo/article/details/9089441/
在spring 3.0以上大家都一般会配置一个Servelet,如下所示:
1 <servlet> 2 <servlet-name>spring</servlet-name> 3 <servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class> 4 <load-on-startup>1</load-on-startup> 5 </servlet>
我们就通过DispatcherServlet来说明和跟踪(注意我们这里不说请求转发,就说bean的加载过程),我们知道servlet的规范中,如果load-on-startup被设定了,那么就会被初始化的时候装载,而servlet装载时会调用其init()方法,那么自然是调用DispatcherServlet的init方法,通过源码一看,竟然没有,但是并不带表真的没有,你会发现在父类的父类中:org.springframework.web.servlet.HttpServletBean有这个方法,如下图所示:
1 public final void init() throws ServletException { 2 if (logger.isDebugEnabled()) { 3 logger.debug("Initializing servlet ‘" + getServletName() + "‘"); 4 } 5 6 // Set bean properties from init parameters. 7 try { 8 PropertyValues pvs = new ServletConfigPropertyValues(getServletConfig(), this.requiredProperties); 9 BeanWrapper bw = PropertyAccessorFactory.forBeanPropertyAccess(this); 10 ResourceLoader resourceLoader = new ServletContextResourceLoader(getServletContext()); 11 bw.registerCustomEditor(Resource.class, new ResourceEditor(resourceLoader)); 12 initBeanWrapper(bw); 13 bw.setPropertyValues(pvs, true); 14 } 15 catch (BeansException ex) { 16 logger.error("Failed to set bean properties on servlet ‘" + getServletName() + "‘", ex); 17 throw ex; 18 } 19 20 // Let subclasses do whatever initialization they like. 21 initServletBean(); 22 23 if (logger.isDebugEnabled()) { 24 logger.debug("Servlet ‘" + getServletName() + "‘ configured successfully"); 25 } 26 }
注意代码:initServletBean(); 其余的都和加载bean关系并不是特别大,跟踪进去会发I发现这个方法是在类:org.springframework.web.servlet.FrameworkServlet类中(是DispatcherServlet的父类、HttpServletBean的子类),内部通过调用initWebApplicationContext()来初始化一个WebApplicationContext,源码片段(篇幅所限,不拷贝所有源码,仅仅截取片段)
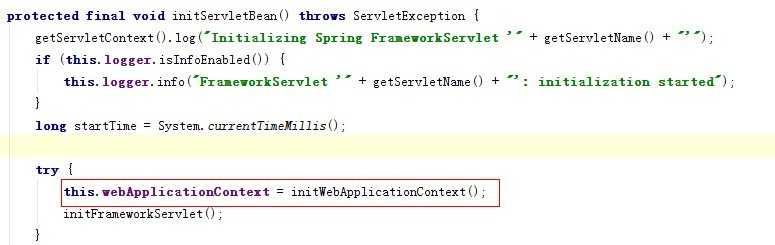
接下来需要知道的是如何初始化这个context的(按照使用习惯,其实只要得到了ApplicationContext,就得到了bean的信息,所以在初始化ApplicationCotext的时候,就已经初始化好了bean的信息,至少至少,它初始化好了bean的路径,以及描述信息),所以我们一旦知道ApplicationCotext是怎么初始化的,就基本知道bean是如何加载的了。
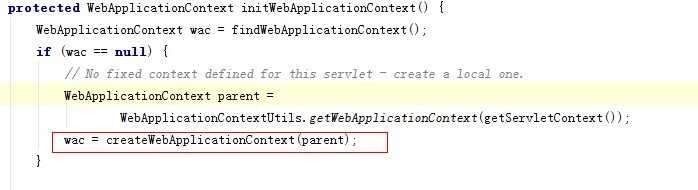
这里的parent基本不用管,因为Root的ApplicationContext的信息还根本没创建,所以主要是看createWebApplicationContext这个方法,进去后,该方法前面部分,都是在设置一些相关的参数,例如我们需要将WEB容器、以及容器的配置信息设置进去,然后会调用一个refresh()方法,这个方法表面上是用来刷新的,其实也是用来做初始化bean用的,也就是配置修改后,如果你能调用它的这个方法,就可以重新装载spring的信息

其实这个方法,不论是通过ClassPathXmlApplicationContext还是WEB装载都会调用这里,我们看下ClassPathXmlApplicationContext中调用的部分:
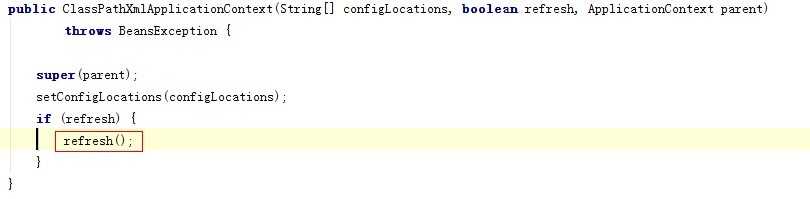
他们的区别在于,web容器中,用servlet装载了,servlet中包装了一个XmlWebApplicationContext而已,而ClassPathXmlApplicationContext是直接调用的,他们共同点是,不论是XmlWebApplicationContext、还是ClassPathXmlApplicationContext都继承了类(间接继承):
AbstractApplicationContext,这个类中的refresh()方法是共用的,也就是他们都调用的这个方法来加载bean的,在这个方法中,通过obtainFreshBeanFactory方法来构造beanFactory的,如下图所示:
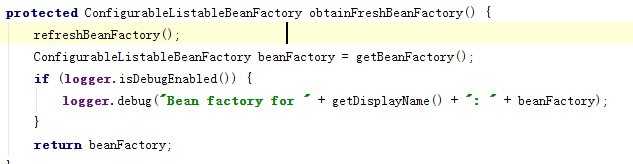
这里很多人可能会不太注意refreshBeanFactory()这个方法,尤其是第一遍看这个代码的,如果你忽略掉,你可能会找不到bean在哪里加载的,前面提到了refresh其实可以用以初始化,这里也是这样,refreshBeanFactory如果没有初始化beanFactory就是初始化它了,后面你看到的都是getBeanFactory的代码,也就是已经初始化好了,这个refreshBeanFactory方法类AbstractRefreshableApplicationContext中的方法,它是AbstractApplicationContext的子类,同样不论是XmlWebApplicationContext、还是ClassPathXmlApplicationContext都继承了它,因此都能调用到这个一样的初始化方法,来看看body部分的代码:
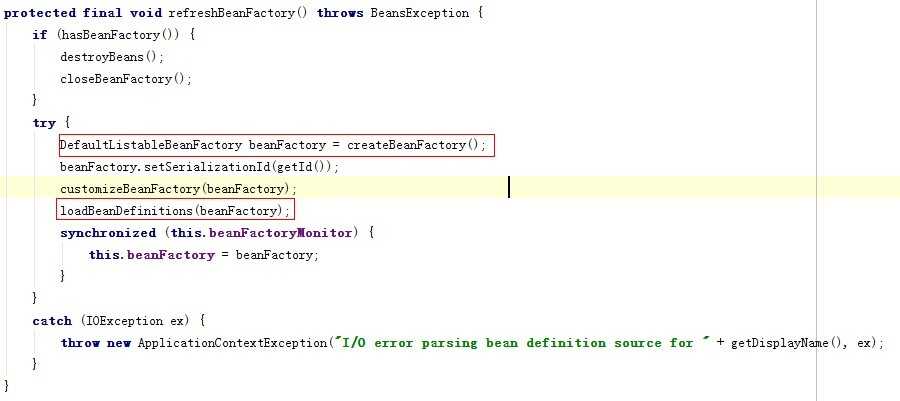
注意第一个红圈圈住的地方,是创建了一个beanFactory,然后下面的方法可以通过名称就能看出是“加载bean的定义”,将beanFactory传入,自然要加载到beanFactory中了,createBeanFactory就是实例化一个beanFactory没别的,我们要看的是bean在哪里加载的,现在貌似还没看到重点,继续跟踪
loadBeanDefinitions(DefaultListableBeanFactory)方法
它由AbstractXmlApplicationContext类中的方法实现,web项目中将会由类:XmlWebApplicationContext来实现,其实差不多,主要是看启动文件是在那里而已,如果在非web类项目中没有自定义的XmlApplicationContext,那么其实功能可以参考XmlWebApplicationContext,可以认为是一样的功能。那么看看loadBeanDefinitions方法如下:
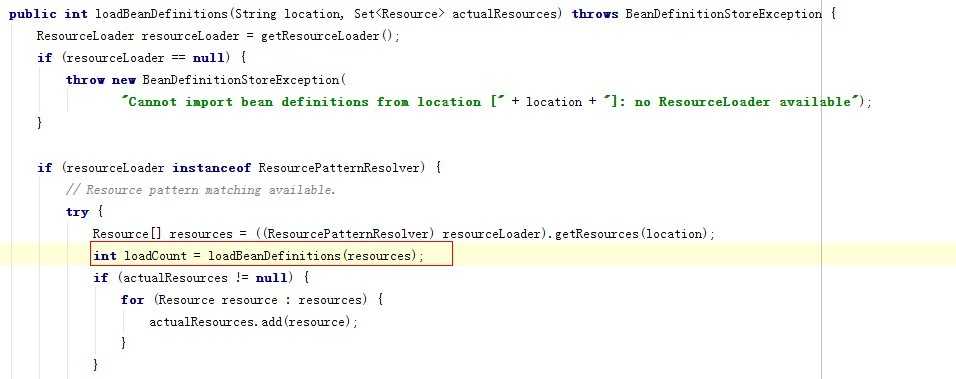
这里大家会疑惑,为啥里面还有一个loadBeanDefinitions,大家要知道,我们目前只解析到我们的springContext.xml在哪里,但是还没解析到springContext.xml的内容是什么,可能有多个spring的配置文件,这里会出现多个Resource,所以是一个数组(这里如何通过location找到文件部分,在我们找class的时候自然明了,大家先不纠结这个问题)。
接下来有很多层调用,会以此调用:
AbstractBeanDefinitionReader.loadBeanDefinitions(Resources []) 循环Resource数组,调用方法:
XmlBeanDefinitionReader.loadBeanDefinitions(Resource ) 和上面这个类是父子关系,接下来会做:doLoadBeanDefinitions、registerBeanDefinitions的操作,在注册beanDefinitions的时候,其实就是要真正开始解析XML了
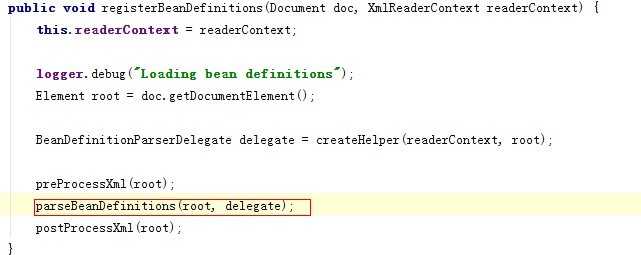
它调用了DefaultBeanDefinitionDocumentReader类的registerBeanDefinitions方法,如下图所示:
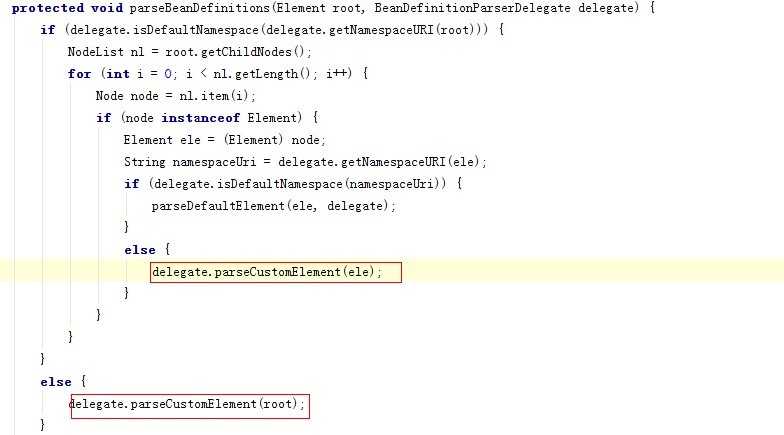
中间有解析XML的过程,但是貌似我们不是很关心,我们就关系类是怎么加载的,虽然已经到XML解析部分了,所以主要看parseBeanDefinitions这个方法,里面会调用到BeanDefinitionParserDelegate类的parseCustomElement方法,用来解析bean的信息:
这里解析了XML的信息,跟踪进去,会发现用了NamespaceHandlerSupport的parse方法,它会根据节点的类型,找到一种合适的解析BeanDefinitionParser(接口),他们预先被spring注册好了,放在一个HashMap中,例如我们在spring 的annotation扫描中,通常会配置:
1 <context:component-scan base-package="com.ccc"/>
此时根据名称“component-scan”就会找到对应的解析器来解析,而与之对应的就是ComponentScanBeanDefinitionParser的parse方法,这地方已经很明显有扫描bean的概念在里面了,这里的parse获取到后,中间有一个非常非常关键的步骤那就是定义了ClassPathBeanDefinitionScanner来扫描类的信息,它扫描的是什么?是加载的类还是class文件呢?答案是后者,为何,因为有些类在初始化化时根本还没被加载,ClassLoader根本还没加载,只是ClassLoader可以找到这些class的路径而已:
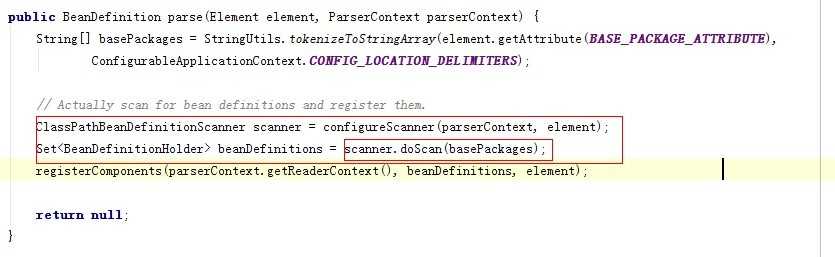
注意这里的scanner创建后,最关键的是doScan的功能,解析XML我想来看这个的不是问题,如果还不熟悉可以先看看,那么我们得到了类似:com.xxx这样的信息,就要开始扫描类的列表,那么再哪里扫描呢?这里的doScan返回了一个Set<BeanDefinitionHolder>我们感到希望就在不远处,进去看看doScan方法。
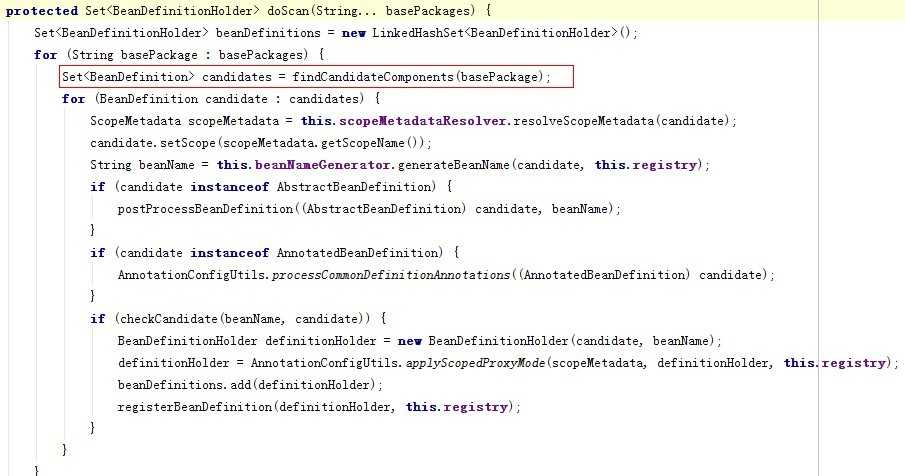
我们看到这么大一坨代码,其实我们目前不关心的代码,暂时可以不管,我们就看怎么扫描出来的,可以看出最关键的扫描代码是:findCandidateComponents(String basePackage)方法,也就是通过每个basePackage去找到有那些类是匹配的,我们这里假如配置了com.abc,或配置了 * 两种情况说明。
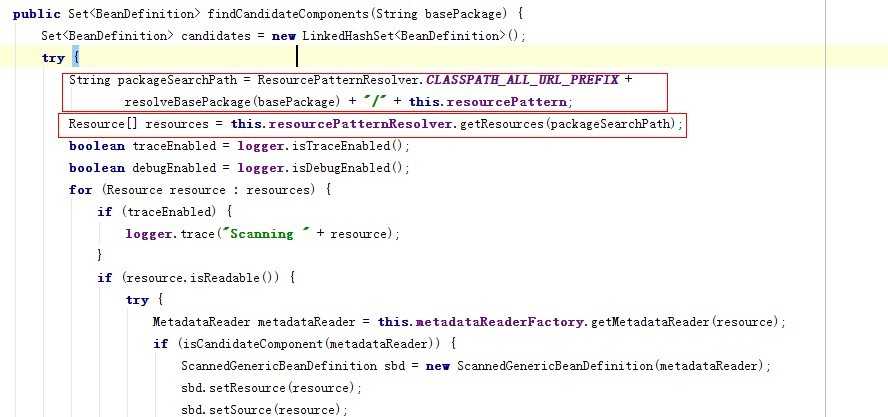
主要看红线部分,下面非红线部分,是已经拿到了类的定义,红线部分,会组装信息,如果我们配置了 com.abc会组装为:classpath*:com/abc/**/*.class ,如果配置是 * ,那么将会被组装为classpath*:*/**/*.class ,但是这个好像和我们用的东西不太一样,java中也没见这种URL可以获取到,spring到底是怎么搞的呢?就要看第二个红线部分的代码:
Resource[] resources = this.resourcePatternResolver.getResources(packageSearchPath);
它竟然神奇般的通过这个路径获取到了URL,你一旦跟踪你会发现,获取出来的全是.class的路径,包括jar包中的相关class路径,这里有些细节,我们先不说,先看下这个resourcePatternResolover是什么类型的,看到定义部分是:
1 private ResourcePatternResolver resourcePatternResolver = new PathMatchingResourcePatternResolver();
测试main方法
1 ResourcePatternResolver resourcePatternResolver = new PathMatchingResourcePatternResolver(); 2 3 Resource[] resources = resourcePatternResolver.getResources("classpath*:com/abc/**/*.class");
获取出来的果然是那样,这个和ClassLoader的getResource方法有关系了,因为太类似了,我们跟踪进去看下:
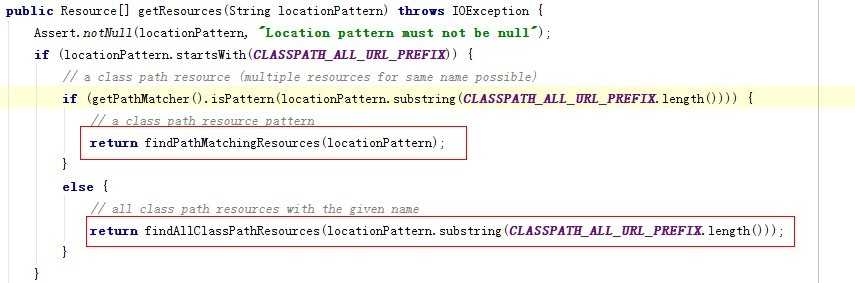
这个CLASSPATH_ALL_URL_PREFIX就是字符串 classpath*: , 我们传递参数进来的时候,自然会走第一个红圈圈住部分的代码,但是第二个红圈圈住部分的代码是干嘛的呢,然后回头会有用,继续找findPathMatchingResources方法,好了,越来越接近真相了。
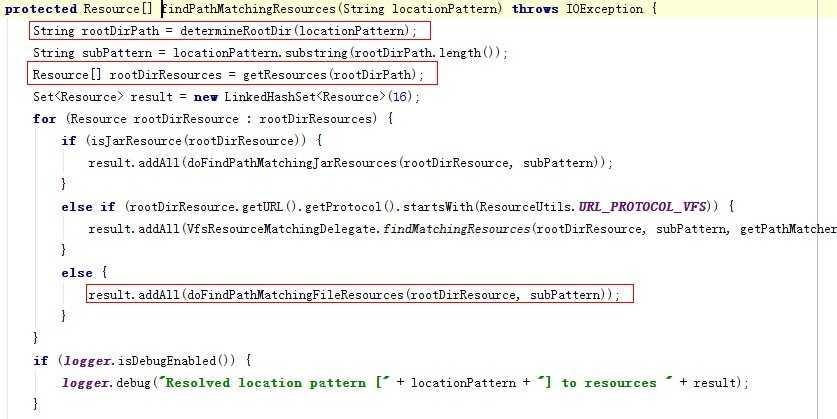
这里有一个rootDirPath,这个地方有个容易出错的,是如果你配置的是 com.abc,那么rootDirPath部分应该是:classpath*:com/abc/ 而如果配置是 * 那么classpath*: 只有这个结果,而不是classpath*:*(这里我就不说截取字符串的源码了),回到上一段代码,这里再次调用了getResources(String)方法,又回到前面一个方法,这一次,依然是以classpath*:开头,所以第一层 if 语句会进去,而第二层不会,为什么?在里面的isPattern() 的实现中是这样写的:
public boolean isPattern(String path) { return (path.indexOf(‘*‘) != -1 || path.indexOf(‘?‘) != -1); }
在匹配前,做了一个substring的操作,会将“classpath*:”这个字符串去掉,如果是配置的是com.abc就变成了"com/abc/",而如果配置为*,那么得到的就是“” ,也就是长度为0的字符串,因此在我们的这条路上,这个方法返回的是false,就会走到代码段findAllClassPathResources中,这就是为什么上面提到会有用途的原因,好了,最最最最关键的地方来了哦。例如我们知道了一个com/abc/为前缀,此时要知道相关的classpath下面有哪些class是匹配的,如何做?自然用ClassLoader,我们看看Spring是不是这样做的:
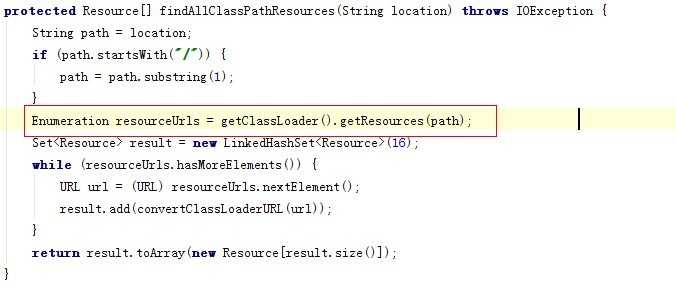
提供的getResources方法就是这样的,有朋友问我的时候,正好遇到了类似的事情,另外需要注意的是,getResources这个方法是包含当前路径的一个递归文件查找(一般环境变量中都会配置 . ),所以如果是一个jar包,你要运行的话,切记放在某个根目录来跑,因为当前目录,就是根目录也会被递归下去,你的程序会被莫名奇怪地慢。
回到上面的代码中,在findPathMatchingResources中我们这里刚刚获取到base的路径列表,也就是所有包含类似com/abc/为前缀的路径,或classpath合并后的目录根路径;此时我们需要下面所有的class,那么就需要的是递归,这里我就不再跟踪了,大家可以自己去跟踪里面的几个方法调用:doFindPathMatchingJarResources、doFindPathMatchingFileResources 。
几乎不会用到:VfsResourceMatchingDelegate.findMatchingResources,所以主要是上面两个,分别是jar包中的和工程里面的class,跟踪进去会发现,代码会不断递归循环调用目录路径下的class文件的路径信息,最终会拿到相关的class列表信息,但是这些class还并没有做检测是否有annotation,那是下一步做的事情,但是下一个步骤已经很简单了,因为要检测一个类的annotation,在前面的文章中:《 java之annotation与框架的那些秘密》中已经提到了。
这里大家还可以通过以下简单的方式来测试调用路径的问题:
1 ClassPathScanningCandidateComponentProvider provider = new ClassPathScanningCandidateComponentProvider(true); 2 Set<BeanDefinition> beanDefinitions = provider.findCandidateComponents("com/abc"); 3 for(BeanDefinition beanDefinition : beanDefinitions) { 4 System.out.println(beanDefinition.getBeanClassName() 5 + "\t" + beanDefinition.getResourceDescription() 6 + "\t" + beanDefinition.getClass()); 7 }
这是直接引用spring的源码部分的内容,如果这里可以获取到,且路径是正确的,一般情况下,都是可以加载到类的。
看了这么多,是不是有点晕,没关系,谁第一回看都这样,当你下一次看的时候,有个思路就好了,我这里并没有像UML一样理出他们的层次关系,和调用关系,仅仅针对代码调用逐层来说明,大家如果初步看就是,由Servlet初始化来创建ApplicationContext,在设置了Servelt相关参数后,获取servlet的配置文件路径或自己指定的配置文件路径(applicationContext.xml或其他的名字,可以一个或多个),然后通过系列的XML解析,以及针对每种不同的节点类型使用不同的加载方式,其中component-scan用于指定扫描类的对应有一个Scanner,它会通过ClassLoader的getResources方法来获取到class的路径信息,那么class的路径都能获取到,类的什么还拿不到呢?呵呵!
好,本文基本内容就说到这里,接下来我会提到spring MVC的中的简单跳转的解析,其中有部分源码是这里看过的,只是还不是这里的重点而已。
而我想说的也是这点,其实本文虽然在说启动,其实有很多代码也没说,因为那样的话我就是一个复制咱贴机了;
其实看源码,要带着目的,大家要知道主体情况或实现的功能,不要就看源码而看源码,一个是根本记不下来,另一个这样看代码没有太大的意义。
当你有了疑问,遇到了难题不知道原因,或发现了新大陆,很有兴趣,那么去看看,也许看之前你会思考下如果我来实现会怎么做?再看看别人是怎么做的,有何区别,不断吸取这些开源框架中优秀的品质,包括代码的设计层次,了解它用到了什么,为何要这样设计,那么你的代码相信会越来越漂亮,你对开源界的代码也会越来越熟悉,熟悉得像自己亲人一样,呵呵。
【对于5楼的回复(CSDN发神经,我回复的内容提示我链接过多,其实一个链接都没有,神奇,所以回复在正文)】:
你能看到isCandidateComponent(MetadataReader metadataReader)方法,其实呢,你再跟下应该就有结果了!要细写可以写一篇文章,简单写下如下:
这个方法里先循环excludeFilters,再循环includeFilters,excludeFilters默认情况下没有啥内容,includeFilters默认情况下最少会有一个new AnnotationTypeFilter(Component.class);
也就是默认情况下excludeFilters排除内容不会循环,includeFilters包含内容最少会匹配到AnnotationTypeFilter,调用AnnotationTypeFilter.match方法是其父类AbstractTypeHierarchyTraversingFilter.math()方法,其内部调用matchSelf()调回子类的AnnotationTypeFilter.matchSelf()方法。该方法中用||连接两个判定分别是hasAnnotation、hasMetaAnnotation,前者判定注解名称本身是否匹配因此Component肯定能匹配上,后者会判定注解的meta注解是否包含,Service、Controller、Repository注解都注解了Component因此它们会在后者匹配上。这样match就肯定成立了。
此时类还没有被装载,Resource中仅仅是类的目录信息,Spring也没有通过ClassLoader将类加载后通过反射读取类的Annotation信息(这条路也是通的),而是通过自己的asm对类的class字节码的解析来完成的,这部分是字节码相关的知识,在我的书中和其它博客有所介绍。spring我想这样做的目的是方便自己做AOP相关的字节码增强一带搞定,也不会多加载不需要的类,因为本文提到的访问如果写了目录,可以访问到jar包中的内容,可能类信息会比较多。
【Spring源码分析系列】启动component-scan类扫描加载过程
标签:连接 取字符串 bst 类加载 循环调用 sys mat 注册 java
原文地址:http://www.cnblogs.com/dream-to-pku/p/7593002.html