标签:中学 http 数据集 cti 说明 git 流程 数据 repr
MICCAI 2017年论文
Overview:
视杯视盘精确分割后,就可以计算杯盘比了,杯盘比是青光眼疾病的主要manifestation。以往的方法往往采用监督学习的方法,这样需要大量的精确像素级别的标定。而这些标定非常费时间。所以本文为了解决这个问题,提出了一个半监督学习的方法,从一堆没有标签的数据中继承一些相似的特征,然后根据少量的有标签的图像训练一个分割模型。具体地,首先采用variational autoencoder从没有标签的图像中学习生成模型的参数,这样,这个训练好的生成模型提供了一个很好的feature embedding,在这个latent feature space中,观测图像就会聚成一簇一簇的。然后,将feature embedding与segmentation autoencoder相结合。这个segmentation autoencoder是在少量的标签数据集上训练得到的,可以获得视杯的分割。
创新点:将生成学习用于半监督的分割方法中。
基本流程:
(image auto-encoder, Generative Variational Autoencoder, GVAE)生成模型学习:用variational autoencoder学习生成模型的参数,autoencoder包含两个部分,一个是将图像映射到因变量空间,用隐变量z表示图像,叫做encoder network。一个是用隐空间变量对图像进行重构,叫做decoder network。
(image segmentation) segmentation variational autoencoder (SVAE)也包含两个部分:一个是segmentation encoder,学习分割模型的因变量表示V,一个是segmentation decoder,将分割模型的因变量表示x作为输入,学习分割的参数,输出segmentation mask。为了利用image auto-encoder从未标记数据中获得的信息,SVAE不仅需要对segmentation mask进行重构,还需要对从GVAE中学到的latent representation x进行重构。所以,loss function为:
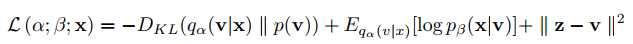
实验:
数据:EyePACS, 12000张眼底图像。从中选600张进行了标记。600张中400张用来做训练,200张用来做测试。实验结果如下:
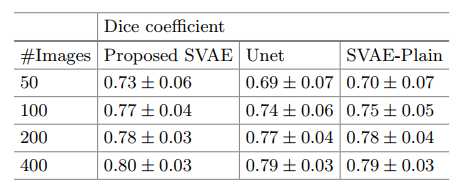
第一列:训练集中使用的图像的数量,相比于Unet有一个百分点的提升。而本身所使用的segmentation autoencoder相比于Unet,使用更少的数据进行训练的时候,分割精度也比Unet高,说明本身所使用的SVAE的泛化能力要优于Unet的。
最后,看论文Auto-Encoding Variational Bayes,code
标签:中学 http 数据集 cti 说明 git 流程 数据 repr
原文地址:http://www.cnblogs.com/qingliu411/p/7593012.html