标签:二进制 nbsp iter http 对象锁 default 代码分析 有助于 max
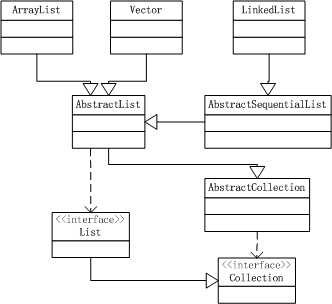
ArrayList和Vector通过数组实现,几乎使用了相同的算法;区别是ArrayList不是线程安全的,Vector绝大多数方法做了线程同步。
LinkedList通过双向链表实现。
ArrayList:当所需容量超过当前ArrayList的大小时,需要进行扩容,对性能有一定的影响。
优化策略:在能有效评估ArrayList数组初始值大小的情况下,指定其容量大小有助于性能提升,避免频繁的扩容。
public boolean add(E e) { ensureCapacityInternal(size + 1); // Increments modCount!! 确保内部数组有足够的空间 elementData[size++] = e; //将元素放在数组尾部 return true; } private void ensureCapacityInternal(int minCapacity) { if (elementData == EMPTY_ELEMENTDATA) { minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity); //如果数组为空数组,取初始容量和minCapacity中的最大值,初始容量DEFAULT_CAPACITY = 10 } ensureExplicitCapacity(minCapacity); } private void ensureExplicitCapacity(int minCapacity) { modCount++; //被修改次数,iterator成员变量expectedModCount为创建时的modCount的值,用来判断list是否在迭代过程中被修改 // overflow-conscious code if (minCapacity - elementData.length > 0) grow(minCapacity); //如果所需容量大小大于数组的大小就进行扩展 } private void grow(int minCapacity) { // overflow-conscious code int oldCapacity = elementData.length; int newCapacity = oldCapacity + (oldCapacity >> 1); //旧容量的1.5倍。二进制右移一位差不多相当于十进制除以2,对CPU来说,右移比除运算速度更快。如果oldCapacity为偶数,newCapacity为1.5*oldCapacity,否则为1.5*oldCapacity-1。 if (newCapacity - minCapacity < 0) //如果计算出的容量不够用,就使用minCapacity newCapacity = minCapacity; if (newCapacity - MAX_ARRAY_SIZE > 0) //如果计算出的容量大于MAX_ARRAY_SIZE=Integer.MAX_VALUE-8, newCapacity = hugeCapacity(minCapacity); // minCapacity is usually close to size, so this is a win: elementData = Arrays.copyOf(elementData, newCapacity);//调用System.arraycopy方法复制数组 } //判断是否大于数组最大值Integer.MAX_VALUE,疑问:设置MAX_ARRAY_SIZE=Integer.MAX_VALUE-8的意义是什么? private static int hugeCapacity(int minCapacity) { if (minCapacity < 0) // overflow throw new OutOfMemoryError(); return (minCapacity > MAX_ARRAY_SIZE) ? Integer.MAX_VALUE : MAX_ARRAY_SIZE; // }
LinkedList:每次新增元素都需要new一个Node对象,并进行更多的赋值操作。在频繁的调用中,对性能会产生一定的影响。
public boolean add(E e) { linkLast(e); return true; } void linkLast(E e) { final Node<E> l = last; final Node<E> newNode = new Node<>(l, e, null); //每增加一个节点,都需要new一个Node last = newNode; if (l == null) first = newNode; else l.next = newNode; size++; modCount++; }
ArrayList:基于数组实现,数组需要一组连续的内存空间,如果在任意位置插入元素,那么该位置之后的元素需要重新排列,效率低。
public void add(int index, E element) { rangeCheckForAdd(index);//检查索引是否越界 ensureCapacityInternal(size + 1); // Increments modCount!! System.arraycopy(elementData, index, elementData, index + 1, size - index);//每次操作都会进行数组复制,System.arraycopy可以实现数组自身的复制 elementData[index] = element; size++; } private void rangeCheckForAdd(int index) { if (index > size || index < 0) throw new IndexOutOfBoundsException(outOfBoundsMsg(index)); }
LinkedList:先找到指定位置的元素,然后在该元素之前插入元素。在首尾插入元素,性能较高;在中间位置插入,性能较低。
//在列表指定位置添加元素 public void add(int index, E element) { checkPositionIndex(index);//检查索引是否越界 if (index == size) //index为列表大小,相当于在列表尾部添加元素 linkLast(element); else linkBefore(element, node(index)); } //返回指定索引的元素,在首尾查找速度快,在中间位置查找速度较慢,需要遍历列表的一半元素。 Node<E> node(int index) { // assert isElementIndex(index); if (index < (size >> 1)) { //如果index在列表的前半部分,从头结点开始向后遍历 Node<E> x = first; for (int i = 0; i < index; i++) x = x.next; return x; } else { //如果index在列表的后半部分,从尾结点开始向前遍历 Node<E> x = last; for (int i = size - 1; i > index; i--) x = x.prev; return x; } } //在指定节点succ之前添加元素 void linkBefore(E e, Node<E> succ) { // assert succ != null; final Node<E> pred = succ.prev; final Node<E> newNode = new Node<>(pred, e, succ); succ.prev = newNode; if (pred == null) //只有succ一个节点 first = newNode; else pred.next = newNode; size++; modCount++; }
ArrayList:每次删除都会复制数组。删除的位置越靠前,开销越大;删除的位置越靠后,开销越小。
public E remove(int index) { rangeCheck(index);//检查索引是否越界 modCount++; E oldValue = elementData(index); int numMoved = size - index - 1; if (numMoved > 0) System.arraycopy(elementData, index+1, elementData, index, numMoved);//将删除位置后面的元素往前移动一位 elementData[--size] = null; // clear to let GC do its work 最后一个位置设置为null return oldValue; }
LinkedList:先通过循环找到要删除的元素,然后删除该元素。删除首尾的元素,效率较高;删除中间元素,效率较差。
public E remove(int index) { checkElementIndex(index); return unlink(node(index)); } E unlink(Node<E> x) { // assert x != null; final E element = x.item; final Node<E> next = x.next; final Node<E> prev = x.prev; if (prev == null) { //x为第一个元素 first = next; } else { prev.next = next; x.prev = null; } if (next == null) { //x为最后一个元素 last = prev; } else { next.prev = prev; x.next = null; } x.item = null; size--; modCount++; return element; }
三种遍历方式:foreach,迭代器,for遍历随机访问。
foreach的内部实现也是使用迭代器进行遍历,但由于foreach存在多余的赋值操作,比直接使用迭代器稍慢,影响不大。for遍历随机访问对ArrayList性能较好,对LinkedList是灾难性的。
Vector和CopyOnWriteArrayList是线程安全的实现;
ArrayList不是线程安全的,可通过Collections.synchronizedList(list)进行包装。
CopyOnWriteArrayList,读操作不需要加锁,
CopyOnWriteArrayList:读操作没有锁操作
public E get(int index) { return get(getArray(), index); } final Object[] getArray() { return array; } private E get(Object[] a, int index) { return (E) a[index]; }
Vector:读操作需要加对象锁,高并发情况下,锁竞争影响性能。
public synchronized E get(int index) { if (index >= elementCount) throw new ArrayIndexOutOfBoundsException(index); return elementData(index); }
CopyOnWriteArrayList:需要加锁且每次写操作都需要进行一次数组复制,性能较差。
public boolean add(E e) { final ReentrantLock lock = this.lock; lock.lock(); try { Object[] elements = getArray(); int len = elements.length; Object[] newElements = Arrays.copyOf(elements, len + 1); //通过复制生成数组副本 newElements[len] = e; //修改副本 setArray(newElements); //将副本写会 return true; } finally { lock.unlock(); } }
Vector:和读一样需要加对象锁,相对CopyOnWriteArrayList来说不需要复制,写性能比CopyOnWriteArrayList要高。
public synchronized boolean add(E e) { modCount++; ensureCapacityHelper(elementCount + 1); //确认是否需要扩容 elementData[elementCount++] = e; return true; } private void ensureCapacityHelper(int minCapacity) { // overflow-conscious code if (minCapacity - elementData.length > 0) grow(minCapacity); }
标签:二进制 nbsp iter http 对象锁 default 代码分析 有助于 max
原文地址:http://www.cnblogs.com/zaizhoumo/p/7595068.html