标签:class 3.0 numpy str alt result color csv dma
线性回归分析:
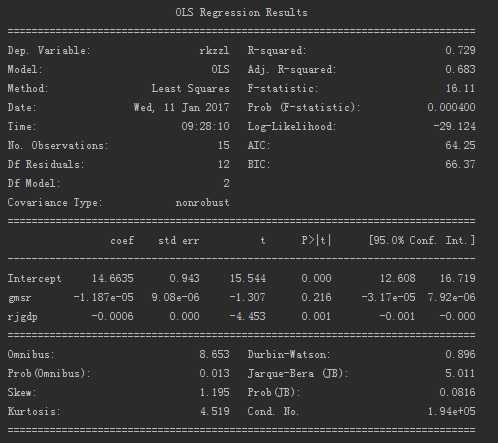
方法: import statsmodels.api as sm import pandas as pd from patsy.highlevel import dmatrices ----2.7里面是 from patsy import dmatrices hg =‘D:/hg.csv‘ df=pd.read_csv(hg) vars=[‘rkzzl‘,‘zrs‘,‘rjgdp‘] df=df[vars] y,X=dmatrices(‘ rkzzl ~ zrs + rjgdp ‘,data=df,return_type=‘dataframe‘) mod=sm.OLS(y,X) res=mod.fit() print res.summary()
所有代码:
import statsmodels.api as sm import pandas as pd import numpy as np from patsy.highlevel import dmatrices from common.util.my_sqlalchemy import sqlalchemy_engine import math sql = "select Q1R3, Q1R5, Q1R6, Q1R7 from db2017091115412316222027656281_1;" df = pd.read_sql(sql, sqlalchemy_engine) df_dropna = df.dropna() y,X=dmatrices(‘ Q1R3 ~ Q1R5 + Q1R6 + Q1R7‘,data=df_dropna,return_type=‘dataframe‘) mod=sm.OLS(y,X) res=mod.fit() result = res.summary() print(result) model = { ‘n‘: int(res.nobs), ‘df‘: res.df_model, ‘r‘: math.sqrt(res.rsquared), ‘r_squared‘:res.rsquared, ‘r_squared_adj‘: res.rsquared_adj, ‘f_statistic‘: res.fvalue, ‘prob_f_statistic‘: res.f_pvalue, } coefficient = { ‘coefficient‘:list(res.params), ‘std‘: list(np.diag(np.sqrt(res.cov_params()))), ‘t‘: list(res.tvalues), ‘sig‘: [i for i in map(lambda x:float(x),("".join("{:.4f},"*len(res.pvalues)).format(*list(res.pvalues))).rstrip(",").split(","))] } returnValue = {‘model‘: model, ‘coefficient‘: coefficient} print(returnValue)
{ ‘model‘: { ‘df‘: 3.0, ‘n‘: 665, ‘prob_f_statistic‘: 1.185607423551511e-17, ‘r_squared_adj‘: 0.11247707470462853, ‘f_statistic‘: 29.049896130483212, ‘r_squared‘: 0.11648696743939679, ‘r‘: 0.3413018714267427}, ‘coefficient‘: { ‘std‘: [0.30170364007280126, 0.049972399035516278, 0.051623405028706125, 0.047659986606566104], ‘sig‘: [0.0, 0.0, 0.0, 0.0312], ‘t‘: [5.4578212730306044, 5.3469744215460269, 4.3810228293129168, 2.1587543885465008], ‘coefficient‘: [1.6466445449401035, 0.26720113942619689, 0.22616331595762876, 0.10288620524499202]} }
标签:class 3.0 numpy str alt result color csv dma
原文地址:http://www.cnblogs.com/renfanzi/p/7598006.html