标签:for void java color def es2017 tor 循环 str
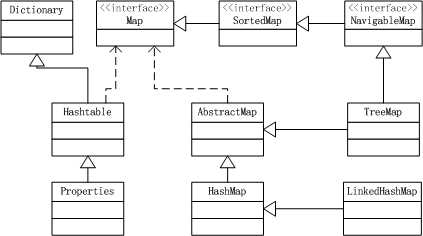
Hashtable对绝大多数方法做了同步,是线程安全的,HashMap则不是;
Hashtable不允许key和value为null,HashMap则允许;
两者对key的hash算法和hash值到内存索引的映射算法不同。
HashMap底层通过数组实现,数组中的元素是一个链表,准确的说HashMap是一个数组与链表的结合体。
HashMap的几个属性:
initialCapacity:初始容量,即数组的大小。实际采用大于等于initialCapacity且是2^N的最小的整数。
loadFactor:负载因子,元素个数/数组大小。衡量数组的填充度,默认为0.75。
threshold:阈值。值为initialCapacity和loadFactor的乘积。当元素个数大于阈值时,进行扩容。
优化点:1、频繁扩容会影响性能。设置合理的初始大小和负载因子可有效减少扩容次数。
2、一个好的hashCode算法,可以尽可能较少冲突,从而提高HashMap的访问速度。
添加元素源代码分析:
public V put(K key, V value) { if (table == EMPTY_TABLE) { //判断是否已经初始化,1.7版本新增的延迟初始化:构造函数初始化后table是空数组,没有真正进行初始化,直到使用时在进行真正的初始化 inflateTable(threshold); } if (key == null) return putForNullKey(value); int hash = hash(key); //计算key的hash值 int i = indexFor(hash, table.length); //根据hash值计算数组索引 for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { //如果key已经存在,新值替换旧值,返回旧值 V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; addEntry(hash, key, value, i); return null; } private void inflateTable(int toSize) { // Find a power of 2 >= toSize int capacity = roundUpToPowerOf2(toSize); //计算不小于toSize且满足2^n的数,算法很巧妙 threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);//阈值=容量*负载因子,用于判断是否需要扩容,负载因子默认为0.75 table = new Entry[capacity]; //真正的数组初始化 initHashSeedAsNeeded(capacity); //初始化hash种子 } private static int roundUpToPowerOf2(int number) { // assert number >= 0 : "number must be non-negative"; return number >= MAXIMUM_CAPACITY ? MAXIMUM_CAPACITY : (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1; //获取最靠近且大于等于number的2^n: //第一种情况number不是2^n,number的二进制的最高位的高一位变为1且其余位变为0,例如14(0000 1110)-->16(0001 0000)。 // 将number左移1位,相当于最高位的高一位变为1,例如:14(0000 1110)-->28(0001 1100), // 计算最靠近且小于等于上一步得到的数的2^n数,相当于其余位变为0,例如:28(0001 1100)-->16(0001 0000) // //第二种情况number本身就是2^n,按上述步骤计算会得到number*2。例如:16-->32 // number - 1的目的是针对number正好是2^n的特殊处理。做减1处理后,number最高位变为0,次高位变为1,再按第一种情况计算得到number本身。 //由于对本身就是2^n的number的减1处理,当number=1时会出现错误,所以需要对1特殊处理,如果number=1则直接返回1 //最终得到计算最靠近且大于等于number的2^n的方法: (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1 } //如果一个数是0, 则返回0; //如果是负数, 则返回 -2147483648: //如果是正数, 返回的则是跟它最靠近且小于等于它的2的N次方,例如8->8 17->16 public static int highestOneBit(int i) { // HD, Figure 3-1 i |= (i >> 1); i |= (i >> 2); i |= (i >> 4); i |= (i >> 8); i |= (i >> 16); //对正数来说,移位完之后为最高位之后都变为1,移5次是因为int为32位,例如:0010010 ---> 0011111 return i - (i >>> 1); //结果为最高位为1,其他位为0,例如0010000,从而得到最靠近且小于等于它的2的N次方。 } //单独处理key为null的情况,放在数组索引位置为0的链表 private V putForNullKey(V value) { for (Entry<K,V> e = table[0]; e != null; e = e.next) { if (e.key == null) { //如果已经存在key为null的元素,用新值替换调旧值,返回旧值。 V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; addEntry(0, null, value, 0);//如果不存在key为null的元素,在0位置新增key为null的元素,返回null。 return null; } //计算key的hash值 final int hash(Object k) { int h = hashSeed; //hash种子,1.7版本引入,获取更好的hash值,减少hash冲突;当等于0时禁止调备用hash函数 if (0 != h && k instanceof String) { return sun.misc.Hashing.stringHash32((String) k); } h ^= k.hashCode(); // This function ensures that hashCodes that differ only by // constant multiples at each bit position have a bounded // number of collisions (approximately 8 at default load factor). h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4); } //根据hash值计算数组索引 static int indexFor(int h, int length) { // assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2"; return h & (length-1); //首先想到的应该是取模运算,h(hash值)%length(数组长度),考虑到取模运算效率较低,JDK采用另一种方法。 //数组长度length总是2的N次方且h为非负数,此时h & (length-1)就等价于h % length,但&运算比%运算效率高的多。 //当数组长度为2的n次幂的时候,不同的key算得得index相同的几率较小。可以这么理解,2^4-1为0000 1111和0000 1110对比,或者的最后一位为0,经过&运算,1101和1100会映射到同一个数组索引。 //length-1即2^N-1,二进制表示为00...0011...11,h & (length-1)的计算结果就是0~length-1之间的值, //如果h的小于length,h & (length-1) = h;如果h大于length,h & (length-1) = h的后n位 } //在指定的数组索引添加Entry void addEntry(int hash, K key, V value, int bucketIndex) { if ((size >= threshold) && (null != table[bucketIndex])) { //当元素个数>=threshold且指定索引元素不为null时,进行扩容 resize(2 * table.length); //扩容,数组长度增加一倍 hash = (null != key) ? hash(key) : 0; //重新计算hash值 bucketIndex = indexFor(hash, table.length); //重新根据hash值计算数组索引 } createEntry(hash, key, value, bucketIndex); // } //如果e==null(bucketIndex位置没有元素),数组中存放新Entry,新Entry的next为null; //如果e!=null(bucketIndex位置已有元素),数组中存放新Entry,新Entry的next为e; void createEntry(int hash, K key, V value, int bucketIndex) { Entry<K,V> e = table[bucketIndex]; table[bucketIndex] = new Entry<>(hash, key, value, e); size++; } //扩容 void resize(int newCapacity) { Entry[] oldTable = table; int oldCapacity = oldTable.length; if (oldCapacity == MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return; } Entry[] newTable = new Entry[newCapacity]; transfer(newTable, initHashSeedAsNeeded(newCapacity)); //重新初始化hash种子 table = newTable; threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1); } //从oldTable转移到newTable void transfer(Entry[] newTable, boolean rehash) { int newCapacity = newTable.length; for (Entry<K,V> e : table) { while(null != e) { Entry<K,V> next = e.next; if (rehash) { e.hash = null == e.key ? 0 : hash(e.key); //重新计算hash值 } int i = indexFor(e.hash, newCapacity); //重新根据hash值计算数组索引 e.next = newTable[i]; //如果e为第一个元素,e.next = null,否则,e.next = 前一个元素。经过扩容,链表上的多个元素的顺序会反转。 newTable[i] = e; //在指定数组索引赋值e e = next; //赋值为下一个元素,进入下一个循环 } } }
获取元素源代码分析:
public V get(Object key) { if (key == null) return getForNullKey(); //key=null,特殊处理 Entry<K,V> entry = getEntry(key); return null == entry ? null : entry.getValue(); } final Entry<K,V> getEntry(Object key) { if (size == 0) { return null; } int hash = (key == null) ? 0 : hash(key); //计算key的hash值 for (Entry<K,V> e = table[indexFor(hash, table.length)]; //计算数组索引 e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) //遍历链表,查找hash值相等且key相等的元素 return e; } return null; } private V getForNullKey() { if (size == 0) { return null; } for (Entry<K,V> e = table[0]; e != null; e = e.next) { if (e.key == null) return e.value; } return null; }
HashMap是无序的,即添加的顺序和遍历元素的顺序具有不确定性。
LinkedHashMap通过在Entry中加入 before, after属性记录该元素的前驱和后继,从而实现有序性。
两种排序方式:
元素添加顺序:accessOrder=false,默认为false
最近访问顺序:accessOrder=true。此情况下,不能使用迭代器遍历集合,因为get()方法会修改Map,在迭代器模式中修改集合会报ConcurrentModificationException。
TreeMap实现了SortedMap,可以根据key对元素进行排序,还提供了接口对有序的key集合进行筛选。
内部基于红黑树实现,红黑树是一种平衡查找树,它的统计性能要优于平衡二叉树。可以在O(logN) 时间内做查找、插入和删除,性能较好。
如果确实需要将排序功能加入HashMap,应该使用TreeMap,而不应该自己去实现排序。
Collections.synchronizedMap(hashMap);
ConcurrentHashMap
标签:for void java color def es2017 tor 循环 str
原文地址:http://www.cnblogs.com/zaizhoumo/p/7597868.html