标签:包括 unix 目标 enc 收集 null rect logs 传输数据
版权声明:本文为yunshuxueyuan原创文章。
如需转载请标明出处: http://www.cnblogs.com/sxt-zkys/
QQ技术交流群:299142667
1. flume 作为 cloudera 开发的实时日志收集系统,受到了业界的认可与广泛应用。Flume 初始的发行版本目前被统称为 Flume OG(original generation),属于 cloudera。但随着 FLume 功能的扩展,Flume OG 代码工程臃肿、核心组件设计不合理、核心配置不标准等缺点暴露出来,尤其是在 Flume OG 的最后一个发行版本 0.94.0 中,日志传输不稳定的现象尤为严重,为了解决这些问题,2011 年 10 月 22 号,cloudera 完成了 Flume-728,对 Flume 进行了里程碑式的改动:重构核心组件、核心配置以及代码架构,重构后的版本统称为 Flume NG(next generation);改动的另一原因是将 Flume 纳入 apache 旗下,cloudera Flume 改名为 Apache Flume。
2. flume的特点:
flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(比如文本、HDFS、Hbase等)的能力 。
flume的数据流由事件(Event)贯穿始终。事件是Flume的基本数据单位,它携带日志数据(字节数组形式)并且携带有头信息,这些Event由Agent外部的Source生成,当Source捕获事件后会进行特定的格式化,然后Source会把事件推入(单个或多个)Channel中。你可以把Channel看作是一个缓冲区,它将保存事件直到Sink处理完该事件。Sink负责持久化日志或者把事件推向另一个Source。
3. flume的可靠性
当节点出现故障时,日志能够被传送到其他节点上而不会丢失。Flume提供了三种级别的可靠性保障,从强到弱依次分别为:end-to-end(收到数据agent首先将event写到磁盘上,当数据传送成功后,再删除;如果数据发送失败,可以重新发送。),Store on failure(这也是scribe采用的策略,当数据接收方crash时,将数据写到本地,待恢复后,继续发送),Besteffort(数据发送到接收方后,不会进行确认)。
4. flume的可恢复性
还是靠Channel。推荐使用FileChannel,事件持久化在本地文件系统里(性能较差)。
5. flume的一些核心概念
Agent:使用JVM 运行Flume。每台机器运行一个agent,但是可以在一个 agent中
包含多个sources和sinks。
Client:生产数据,运行在一个独立的线程。
Source:从Client收集数据,传递给Channel。
Sink:从Channel收集数据,运行在一个独立线程。
Channel:连接 sources 和 sinks ,这个有点像一个队列。
Events:可以是日志记录、 avro 对象等。
介绍一下flume中event的相关概念:flume的核心是把数据从数据源(source)收集过来,在将收集到的数据送到指定的目的地(sink)。为了保证输送的过程一定成功,在送到目的地(sink)之前,会先缓存数据(channel),待数据真正到达目的地(sink)后,flume在删除自己缓存的数据。
在整个数据的传输的过程中,流动的是event,即事务保证是在event级别进行的。那么什么是event呢?—–event将传输的数据进行封装,是flume传输数据的基本单位,如果是文本文件,通常是一行记录,event也是事务的基本单位。event从source,流向channel,再到sink,本身为一个字节数组,并可携带headers(头信息)信息。event代表着一个数据的最小完整单元,从外部数据源来,向外部的目的地去。
为了方便大家理解,给出一张event的数据流向图:
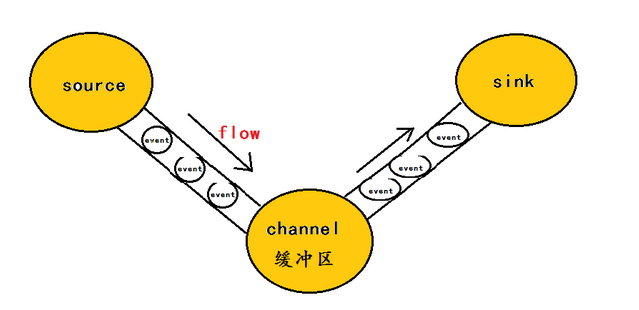
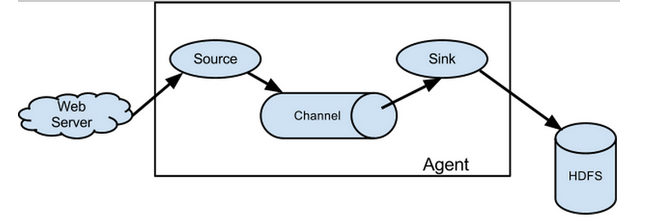
flume之所以这么神奇,是源于它自身的一个设计,这个设计就是agent,agent本身是一个Java进程,运行在日志收集节点—所谓日志收集节点就是服务器节点。
agent里面包含3个核心的组件:source—->channel—–>sink,类似生产者、仓库、消费者的架构。
source:source组件是专门用来收集数据的,可以处理各种类型、各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy、自定义。
channel:source组件把数据收集来以后,临时存放在channel中,即channel组件在agent中是专门用来存放临时数据的——对采集到的数据进行简单的缓存,可以存放在memory、jdbc、file等等。
sink:sink组件是用于把数据发送到目的地的组件,目的地包括hdfs、logger、avro、thrift、ipc、file、null、Hbase、solr、kafaka、自定义。
Source类型:
Avro Source: 支持Avro协议(实际上是Avro RPC),内置支持
Thrift Source: 支持Thrift协议,内置支持
Exec Source: 基于Unix的command在标准输出上生产数据
JMS Source: 从JMS系统(消息、主题)中读取数据
Spooling Directory Source: 监控指定目录内数据变更
Twitter 1% firehose Source: 通过API持续下载Twitter数据,试验性质
Netcat Source: 监控某个端口,将流经端口的每一个文本行数据作为Event输入
Sequence Generator Source: 序列生成器数据源,生产序列数据
Syslog Sources: 读取syslog数据,产生Event,支持UDP和TCP两种协议
HTTP Source: 基于HTTP POST或GET方式的数据源,支持JSON、BLOB表示形式
Legacy Sources: 兼容老的Flume OG中Source(0.9.x版本)
Channel类型:
Memory Channel:Event数据存储在内存中
JDBC Channel:Event数据存储在持久化存储中,当前Flume Channel内置支持Derby
File Channel:Event数据存储在磁盘文件中
Spillable Memory Channel:Event数据存储在内存中和磁盘上,当内存队列满了,会持
久化到磁盘文件
Pseudo Transaction Channel:测试用途
Custom Channel:自定义Channel实现
Sink类型 说明
HDFS Sink:数据写入HDFS
Logger Sink:数据写入日志文件
Avro Sink:数据被转换成Avro Event,然后发送到配置的RPC端口上
Thrift Sink:数据被转换成Thrift Event,然后发送到配置的RPC端口上
IRC Sink:数据在IRC上进行回放
File Roll Sink:存储数据到本地文件系统
Null Sink:丢弃到所有数据
HBase Sink:数据写入HBase数据库
Morphline Solr Sink:数据发送到Solr搜索服务器(集群)
ElasticSearch Sink:数据发送到Elastic Search搜索服务器(集群)
Kite Dataset Sink:写数据到Kite Dataset,试验性质的
Custom Sink:自定义Sink实现
flume的核心就是一个agent,这个agent对外有两个进行交互的地方,一个是接受数据的输入——source,一个是数据的输出sink,sink负责将数据发送到外部指定的目的地。source接收到数据之后,将数据发送给channel,chanel作为一个数据缓冲区会临时存放这些数据,随后sink会将channel中的数据发送到指定的地方—-例如HDFS等,注意:只有在sink将channel中的数据成功发送出去之后,channel才会将临时数据进行删除,这种机制保证了数据传输的可靠性与安全性。
flume之所以这么神奇—-其原因也在于flume可以支持多级flume的agent,即flume可以前后相继,例如sink可以将数据写到下一个agent的source中,这样的话就可以连成串了,可以整体处理了。flume还支持扇入(fan-in)、扇出(fan-out)。所谓扇入就是source可以接受多个输入,所谓扇出就是sink可以将数据输出多个目的地destination中。
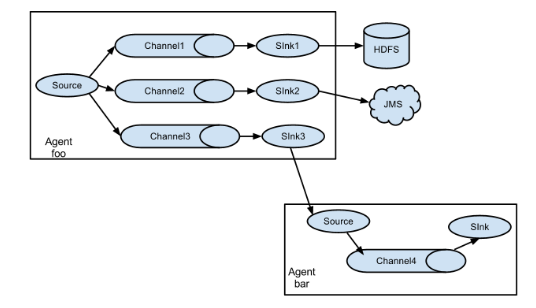
1. 下载源码包,上传到集群的节点:
2. 解压到指定目录
3. 修改conf/flume.env.sh:
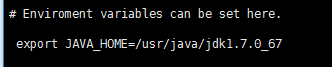
注意:JAVA_OPTS 配置 如果我们传输文件过大 报内存溢出时 需要修改这个配置项
4. 配置环境变量

刷新profile文件:source /etc/profile
5. 验证安装是否成功

http://flume.apache.org/FlumeUserGuide.html#a-simple-example
配置文件simple.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动flume
flume-ng agent -n a1 -c conf -f simple.conf -Dflume.root.logger=INFO,console
安装telnet
yum install telnet
Memory Chanel 配置
capacity:默认该通道中最大的可以存储的event数量是100,
trasactionCapacity:每次最大可以source中拿到或者送到sink中的event数量也是100
keep-alive:event添加到通道中或者移出的允许时间
byte**:即event的字节量的限制,只包括eventbody
node01服务器中,配置文件
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = node1
a1.sources.r1.port = 44444
# Describe the sink
# a1.sinks.k1.type = logger
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = node2
a1.sinks.k1.port = 60000
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1node02服务器中,安装Flume(步骤略)
配置文件
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = avro
a1.sources.r1.bind = node2
a1.sources.r1.port = 60000
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1先启动node02的Flume
flume-ng agent -n a1 -c conf -f avro.conf -Dflume.root.logger=INFO,console
再启动node01的Flume
flume-ng agent -n a1 -c conf -f simple.conf2 -Dflume.root.logger=INFO,console
打开telnet 测试 node02控制台输出结果
http://flume.apache.org/FlumeUserGuide.html#exec-source
配置文件
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/flume.exec.log
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1启动Flume
flume-ng agent -n a1 -c conf -f exec.conf -Dflume.root.logger=INFO,console
创建空文件演示 touch flume.exec.log
循环添加数据
for i in {1..50}; do echo "$i hi flume" >> flume.exec.log ; sleep 0.1; done
http://flume.apache.org/FlumeUserGuide.html#spooling-directory-source
配置文件
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /home/logs
a1.sources.r1.fileHeader = true
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1启动Flume
flume-ng agent -n a1 -c conf -f spool.conf -Dflume.root.logger=INFO,console
拷贝文件演示
mkdir logs
cp flume.exec.log logs/
http://flume.apache.org/FlumeUserGuide.html#hdfs-sink
配置文件
############################################################
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /home/logs
a1.sources.r1.fileHeader = true
# Describe the sink
***只修改上一个spool sink的配置代码块 a1.sinks.k1.type = logger
a1.sinks.k1.type=hdfs
a1.sinks.k1.hdfs.path=hdfs://sxt/flume/%Y-%m-%d/%H%M
##每隔60s或者文件大小超过10M的时候产生新文件
# hdfs有多少条消息时新建文件,0不基于消息个数
a1.sinks.k1.hdfs.rollCount=0
# hdfs创建多长时间新建文件,0不基于时间
a1.sinks.k1.hdfs.rollInterval=60
# hdfs多大时新建文件,0不基于文件大小
a1.sinks.k1.hdfs.rollSize=10240
# 当目前被打开的临时文件在该参数指定的时间(秒)内,没有任何数据写入,则将该临时文件关闭并重命名成目标文件
a1.sinks.k1.hdfs.idleTimeout=3
a1.sinks.k1.hdfs.fileType=DataStream
a1.sinks.k1.hdfs.useLocalTimeStamp=true
## 每五分钟生成一个目录:
# 是否启用时间上的”舍弃”,这里的”舍弃”,类似于”四舍五入”,后面再介绍。如果启用,则会影响除了%t的其他所有时间表达式
a1.sinks.k1.hdfs.round=true
# 时间上进行“舍弃”的值;
a1.sinks.k1.hdfs.roundValue=5
# 时间上进行”舍弃”的单位,包含:second,minute,hour
a1.sinks.k1.hdfs.roundUnit=minute
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
############################################################
创建HDFS目录
hadoop fs -mkdir /flume
启动Flume
flume-ng agent -n a1 -c conf -f hdfs.conf -Dflume.root.logger=INFO,console
查看hdfs文件
hadoop fs -ls /flume/...
hadoop fs -get /flume/...
版权声明:本文为yunshuxueyuan原创文章。
如需转载请标明出处:http://www.cnblogs.com/sxt-zkys/
QQ技术交流群:299142667
标签:包括 unix 目标 enc 收集 null rect logs 传输数据
原文地址:http://www.cnblogs.com/sxt-zkys/p/7601821.html