标签:logs 基本 决定 放弃 理论 大话数据结构 size .net net
本文参考资料:
1、《大话数据结构》
2、http://blog.csdn.net/jzhf2012/article/details/8540543
3、http://blog.csdn.net/jzhf2012/article/details/8540410
4、http://www.cnblogs.com/ITtangtang/p/3948610.html
5、http://blog.csdn.net/zw0283/article/details/51132161
本来在分析完HashSet、HashMap之后,我想紧跟着分析TreeMap以及TreeSet的,但是当我读过源码以后,我就放弃了这个想法。并不是源码有多难,而是TreeMap涉及到的数据结构中的树结构,而我之前一直分析的都是线性结构,而且ArrayList、LinkedList也是线性结构,并且还没有分析。因此,我还是决定按部就班的进行,先把线性表全部分析完了,再去分析TreeMap。
ArrayList底层源码基本逻辑结构很简单,在《JDK学习---深入理解java中的String》一文中基本已经分析完毕,唯一不同的是String的底层数组不可变,而在ArrayList的底层Object[] 数组中,允许数组增、删、该操作,并且支持数组的动态扩容,这些东西不难,相信读者能很轻松搞明白这些知识,我就不再说明了。
本文我将重点的说明一下LinkedList知识点,而LinkedList的底层是一个双向链表结构,因此我会在解析源码之前,穿插一些双向链表的知识,然后结合代码进行分析。我不喜欢很空洞的单独去说数据结构,一是因为本人水平有限说不清楚,二是因为我觉得理论需要结合代码,这样分析更加的直观一些。如果读者想要仔细的了解数据结构的知识,可以去找一些书籍详细研读。
双向链表
《JDK学习---深入理解java中的String》一文介绍了数据结构的大体架构,《JDK学习---深入理解java中的HashMap、HashSet底层实现》介绍了线性表的单链表。
本文将继续介绍数据结构的双向链表。
双向链表:在单链表的每个节点中,再设置一个指向其前前驱节点的指针域 【DP】
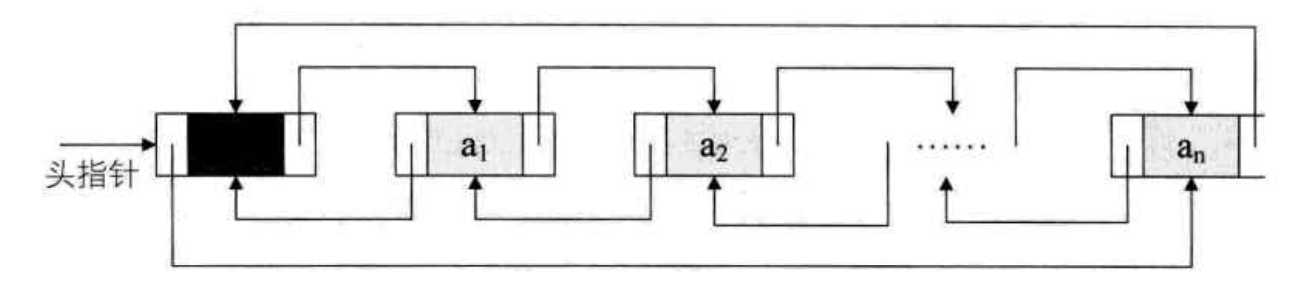
既然是双向链表,那么对于链表中的某一个节点(p),它的后继的前驱,以及前驱的后继,其实都是这个节点本身:
p->next->prior = p = p->next-prior
双链表的插入操作并不复杂,但是顺序很重要,千万不能写错。
假设,我们现在有一个节点s,它存储的元素为e,现在要将节点s插入到节点p和p->next之间,需要严格的遵守插入的先后顺序,如下图:
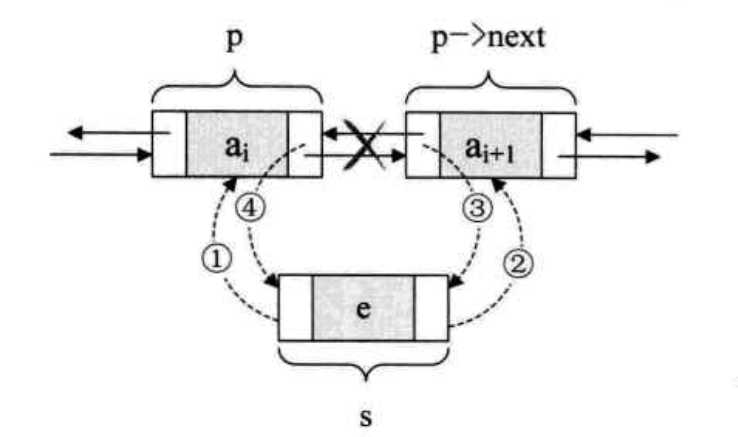
s -> prior = p; //把p赋值给s的前驱,如图中1 s -> next = p -> next; //把p -> next 赋值给s的后继,如图中2 p -> next -> prior = s; //把s 赋值给 p->next的前驱 ,如图中3 p -> next =s; //把s 赋值给p 的后继,如图中4
关键在于它们的顺序,由于第2、3步都用到了p->next , 如果第4步先执行,则会使得p->next提前变成了s,使得插入工作完成不了。口诀是:先搞定s的前驱和后继,再搞定后继的前驱,最后解决前节点的后继。
如果插入操作理解了,那么删除操作也就简单了。
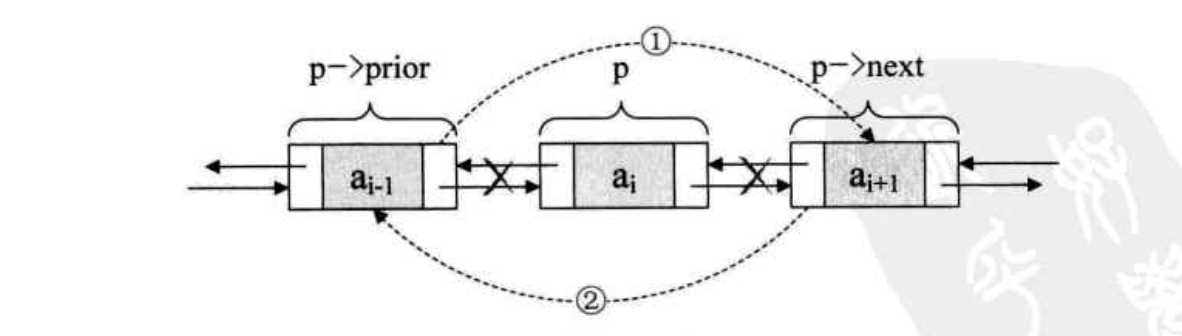
p ->prior -> next = p -> next; //把p ->next赋值给p->prior的后继,如图中1 p ->next -> prior = p ->prior; //把 p ->prior赋值给p ->next 的前驱,如图中2 free(p); //释放节点p
总结:双向链表对于单链表而言,增、删操作要复杂一些,毕竟多了一个prior指针域,所以操作需要格外小心。另外,由于每个节点都需要记录两份指针,空间相对而言也占用略多一些。不过,由于它良好的对称性,使得对某个节点的增、删操作带来了方便。说白了,就是用空间换时间。
标签:logs 基本 决定 放弃 理论 大话数据结构 size .net net
原文地址:http://www.cnblogs.com/chen1-kerr/p/7605898.html