标签:hid 有限公司 隐藏 字符串 变量 targe 多媒体 内容 uila
1.知道本节点元素,如何定位到兄弟元素
详情见博客
XML代码见下
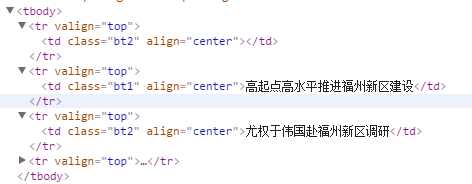
bt1在文档中只出现一次,所以很容易获取到bt1中内容,那怎么根据<td class=‘bt1‘>来获取bt2中的内容
content_title = driver.find_element_by_xpath("//td[@class=‘bt1‘]").text
# 获取content_title的父节点的哥哥节点
content_subtitle = driver.find_element_by_xpath("//td[@class=‘bt1‘]/../following-sibling::tr[1]").text
# 获取第二个tr下面td的父节点的弟弟节点
conten_subtitle = driver.find_element_by_xpath("//td[@class=‘bt1‘]/../preceding-sibling::tr[1]").text
返回的内容为:高起点高水平推进福州新区建设
尤权于伟国赴福州新区调研
‘’
2.元素替换,查找元素位置可以用变量替换字符串
>>> driver.find_element_by_xpath("//*[@id=‘mp1057136‘]").click()
>>> a=‘mp1057136‘
>>> driver.find_element_by_xpath("//*[@id=‘%s‘]"% a).click()
>>>
3.用webdriver获取网页上影藏的文字
网页格式和源码如下所示,网页上的内容被隐藏了,需要点击一下才会完全显示。右边是没有点击前页面的源码,可以看到完整的内容其实已经在页面上了,于是我通过下面方式获取


>>> driver.find_element_by_xpath(".//*[@id=‘company_base_info_detail‘]").text
‘‘
>>> driver.find_element_by_xpath("//script[@id=‘company_base_info_detail‘]").text
‘‘
通过定位获取到的竟然为空,并不想通过模拟点击生成新页面再来获取内容,看到网上博主有提到另一种获取隐藏信息的方式
driver.execute_script("return arguments[0].textContent",c)获取文字或者
driver.execute_script("return arguments[0].innerHTML",c)获取源码
>>> c=driver.find_element_by_xpath("//div[@class=‘sec-c2 over-hide‘]")
>>> driver.execute_script("return arguments[0].textContent",c)
‘简介:淘宝(中国)软件有限公司成立于2004年12月07日,主要经营范围为研究、开发计算机软、硬...\n 淘宝(中国)软件有限公司成立于2004年12月07日,主要经营范围为研究、开发计算机软、硬件,网络技术产品,多媒体产品等。\n 详情‘
>>> driver.execute_script("return arguments[0].innerHTML",c)
‘<span><span class="sec-c3">简介:</span>淘宝(中国)软件有限公司成立于2004年12月07日,主要经营范围为研究、开发计算机软、硬...</span><script type="text/html" id="company_base_info_detail">\n 淘宝(中国)软件有限公司成立于2004年12月07日,主要经营范围为研究、开发计算机软、硬件,网络技术产品,多媒体产品等。\n </script><span class="c9 point hover_underline" onclick="companyDetail()">详情</span>‘
>>> c=driver.find_element_by_xpath("//div[@class=‘sec-c2 over-hide‘]//script")
>>> driver.execute_script("return arguments[0].textContent",c)
‘\n 淘宝(中国)软件有限公司成立于2004年12月07日,主要经营范围为研究、开发计算机软、硬件,网络技术产品,多媒体产品等。\n ‘
>>>
后面我重新定义了c使得最终得到我想要的企业完整简介
标签:hid 有限公司 隐藏 字符串 变量 targe 多媒体 内容 uila
原文地址:http://www.cnblogs.com/bethansy/p/7597634.html