标签:释放 linux内核 中断上下文 根目录 通信 静态 cisc 表示 并发控制
内核基础
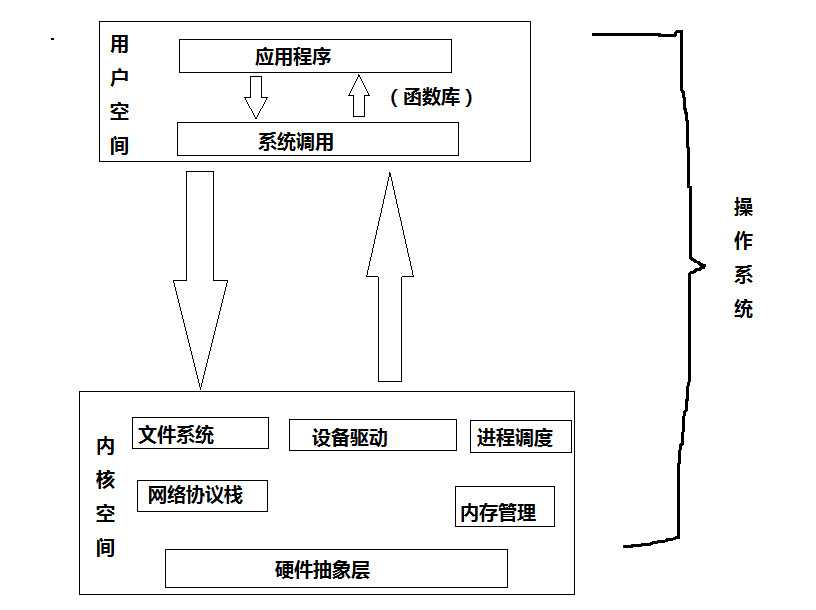
1、linux内核主要是由进程调度、内存管理、虚拟文件系统(字符设备驱动和块设备驱动)、网络接口(网络设备驱动)和进程通信5个子系统组成的。
1)进程调度控制系统中的多个进程对CPU的访问,使得多个进程能在CPU中"微观串行,宏观并行"地执行。
2)内存管理的主要作用就是控制多个进程安全的共享主内存区域,当CPU提供内存管理单元时,linux内存管理完成为每个进程进行虚拟内存到物理内存的转换。一般而言,linux的每一个进程享有4GB的内存空间。0~3GB为用户空间,3~4GB为内核空间,这1GB的内核空间又被划分为物理内存映射区,虚拟内存分配区、高端页面映射区和系统保留映射区。物理内存映射区最大长度为896MB,系统物理内存0~896MB就映射到这个物理内存映射区。系统物理内存中大于896MB的数据属于高端内存,会被映射到高端页面映射区。所以,在3~4GB的内核空间中,从低地址到高地址依次为:物理内存映射区----->隔离带------>虚拟内存分配区------>隔离带------>高端内存映射区------>专用页面映射区------>保留区。
3)虚拟文件系统隐藏各种硬件的具体细节,为所有的设备提供一套统一的接口。
4)网络接口提供了对各种网络标准的存取和各种网络硬件的支持。
5)进程通信支持提供进程之间的通信,包括信号量、共享内存、管道等。
2、进程管理:完全公平调度算法(CFS)
(1)多任务系统分为抢占式和非抢占式,linux提供抢占式多任务模式,进程在被抢占之前能够运行的时间叫做进程的时间片。
(2)进程可以分为I/O消耗型和处理器消耗型。I/O消耗型是指进程的大部分时间用来提交I/O请求或是等待I/O请求;处理器消耗型是指进程把事件大多数用在代码执行上。 linux中更倾向于I/O消耗型进程。
(3)调度程序总是选择时间片未用尽而且优先级最高的进程运行。
(4)上下文切换就是说从一个可执行进程切换到另一个可执行进程。
(5)进程的上下文: 当一个进程在执行时,CPU的所有寄存器中的值、进程的状态以及堆栈中的内容被称为该进程的上下文。当内核需要切换到另一个进程时,它需要保存当前进程的所有状态,即保存当前进程的上下文,以便在再次执行该进程时,能够得到切换时的状态执行下去。在LINUX中,当前进程上下文均保存在进程的任务数据结构中。在发生中断时,内核就在被中断进程的上下文中,在内核态下执行中断服务例程。但同时会保留所有需要用到的资源,以便中继服务结束时能恢复被中断进程的执行。
(6)系统调用:系统调用是用户空间访问内核的唯一手段,除异常和陷入外。它们是内核唯一的合法入口。一般应用程序中的API调用c库,c库再调用内核中的系统调用,在UNIX中,最流行的应用编程接口是基于POSIX标准的。
(7)由于内核驻留在受保护的地址空间中,所以用户空间程序无法直接访问内核空间。其中通知内核的机制是靠软中断来实现的,这个软中断都是通过执行"init $0x80"指令触发的,通过引发一个异常去促使系统切换到内核态去执行异常处理程序,这个异常处理程序就是系统调用处理程序:system_call.
(8)内核提供了两种方式来完成内核空间和用户空间的数据拷贝:copy_to_user和copy_from_user,这两个函数都会引起阻塞。
3、中断处理:中断处理程序是被内核调用来响应中断的,它运行在中断上下文。
补充: 对Linux内核中进程上下文和中断上下文的理解
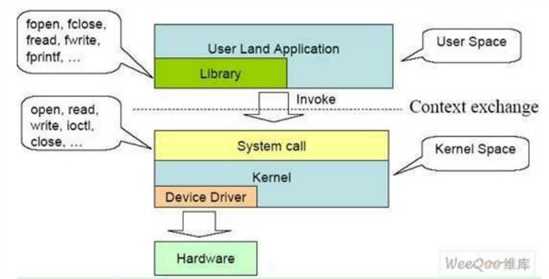
内核空间和用户空间是操作系统理论的基础之一,即内核功能模块运行在内核空间,而应用程序运行 在用户空间。现代的CPU都具有不同的操作模式,代表不同的级别,不同的级别具有不同的功能,在较低 的级别中将禁止某些操作。Linux系统设计时利用了这种硬件特性,使用了两个级别,最高级别和最低级 别,内核运行在最高级别(内核态),这个级别可以进行所有操作,而应用程序运行在较低级别(用户态), 在这个级别,处理器控制着对硬件的直接访问以及对内存的非授权访问。内核态和用户态有自己的内存映 射,即自己的地址空间。 正是有了不同运行状态的划分,才有了上下文的概念。用户空间的应用程序,如果想要请求系统服务, 比如操作一个物理设备,或者映射一段设备空间的地址到用户空间,就必须通过系统调用来(操作系统提 供给用户空间的接口函数)实现。如下图所示:
通过系统调用,用户空间的应用程序就会进入内核空间,由内核代表该进程运行于内核空间,这就涉 及到上下文的切换,用户空间和内核空间具有不同的地址映射,通用或专用的寄存器组,而用户空间的进 程要传递很多变量、参数给内核,内核也要保存用户进程的一些寄存器、变量等,以便系统调用结束后回 到用户空间继续执行,所谓的进程上下文,就是一个进程在执行的时候,CPU的所有寄存器中的值、进程 的状态以及堆栈中的内容,当内核需要切换到另一个进程时,它需要保存当前进程的所有状态,即保存当 前进程的进程上下文,以便再次执行该进程时,能够恢复切换时的状态,继续执行。
同理,硬件通过触发信号,导致内核调用中断处理程序,进入内核空间。这个过程中,硬件的一些变 量和参数也要传递给内核,内核通过这些参数进行中断处理,中断上下文就可以理解为硬件传递过来的这 些参数和内核需要保存的一些环境,主要是被中断的进程的环境。 Linux内核工作在进程上下文或者中断上下文。
提供系统调用服务的内核代码代表发起系统调用的应 用程序运行在进程上下文;另一方面,中断处理程序,异步运行在中断上下文。中断上下文和特定进程无 关。
运行在进程上下文的内核代码是可以被抢占的(Linux2.6支持抢占)。但是一个中断上下文,通常都 会始终占有CPU(当然中断可以嵌套,但我们一般不这样做),不可以被打断。正因为如此,运行在中断 上下文的代码就要受一些限制,不能做下面的事情:
1)、睡眠或者放弃CPU。
这样做的后果是灾难性的,因为内核在进入中断之前会关闭进程调度,一旦睡眠或者放弃CPU,这时
内核无法调度别的进程来执行,系统就会死掉
2)、尝试获得信号量
如果获得不到信号量,代码就会睡眠,会产生和上面相同的情况
3)、执行耗时的任务
中断处理应该尽可能快,因为内核要响应大量服务和请求,中断上下文占用CPU时间太长会严重影响
系统功能。
4)、访问用户空间的虚拟地址
因为中断上下文是和特定进程无关的,它是内核代表硬件运行在内核空间,所以在终端上下文无法访
问用户空间的虚拟地址
小结:进程上下文就是应用程序那边向内核发来的中断信号;而中断上下文就是硬件向内核发来的终端信号,前者可以被抢占,后者一般不能够被抢占。
4、并发同步:如果有一台支持多处理器(SMP)的机器,那么两个进程就可以真正在临界区域中同时执行,这就叫做真并发;反之称为伪并发。
并发产生的原因有:
(1)中断
(2)软中断和tasklet;
(3)内核抢占;
(4)睡眠及用户空间的同步;
(5)对称多处理
避免死锁的方式有:
死锁和数据争夺只能尽量避免
一般来说,如果系统资源充足,进程的资源请求都能够得到满足,死锁出现的可能性就很低,否则就会因争夺有限的资源而陷入死锁。
另外死锁有4个必要条件(要发生缺一不可)
(1) 互斥条件:一个资源每次只能被一个进程使用。
(2) 请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
(3) 不剥夺条件:进程已获得的资源,在末使用完之前,不能强行剥夺。
(4) 循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
通过使用较好的资源分配算法,就可以尽可能地破坏死锁的必要条件,从而尽可能地避免死锁
解决并发同步的方法:
(1)原子操作
(2)自旋锁
(3)自旋锁和下半部的问题
(4)信号量
(5)互斥体
(6)完成量
(7)禁止抢占
5、内存管理:块----->扇区------>页------>字节
1)内核把物理页作为内存管理的基本单位,MMU(内存管理单元,管理内存并把虚拟地址转换为物理地址的硬件)通常以页为单位进行处理。大多数32位体系结构的处理器支持4KB的页。
2)内存除了管理本身的内存(物理内存)外,还必须管理用户空间中的进程的内存(虚拟内存),这个内存就叫做进程地址空间。尽管一个进程可以寻址4GB的虚拟内存,但是这并不代表它就有权访问所有的虚拟内存,这些可以被访问的地址空间称为内存区域。
3)当应用程序访问一个虚拟地址时,首先必须将虚拟地址转换为物理地址,然后处理器才能解析地址访问请求。地址转换需要将虚拟地址分段,使每段虚拟地址都作为一个索引指向页表,linux使用三级页表完成地址转换。
6、处理器:中央处理器体系架构可以分为冯诺伊曼结构和哈佛结构。
从指令的角度中央处理器分为RISC(精简指令集系统)和CISC(复杂指令集系统),中央处理器按照应用领域可以分为通用处理器(GPP),数字信号处理器(DSP)、专用处理器(ASIC).其中GPP包括MCU(微控制器,即单片机)和MPU(微处理器);DSP包括定点DSP和浮点DSP。
驱动概述
1、驱动看作是硬件的灵魂,这一比喻再恰当不过。设备驱动程序可以说相当于硬件的接口,操作系统只有通过这个接口才能够控制硬件的工作。
简单的说,驱动程序就相当于硬件和操作系统之间的桥梁,翻译官,接口;驱动协调操作系统和硬件之间的关系。
2、设备驱动的分类:字符设备驱动、块设备驱动和网络设备驱动。
注意:字符设备是指那些能一个字节一个字节读取数据的设备,内核为字符设备对应一个文件,字符设备文件与普通文件没有太大的区别,差别之处是字符设备一般不支持寻址,寻址的意思就是说对一个硬件中的一块寄存器进行随机的访问,不支持寻址就是说只能对硬件中的寄存器进行顺序的读取,读取数据后,由驱动程序自己来分析需要哪一部分数据。
网络设备实现了一种套接字接口,任何网络数据传输都可以通过套接字来完成。
3、linux操作系统与驱动的关系:操作系统包括:内核+应用程序(linux系统提供的API,包括shell等);而驱动又包含在内核中。
4、linux驱动程序开发:用户态和内核态
驱动程序与底层的硬件交互,工作在内核态;内核态大部分时间在完成与硬件的交互。注意的是:用户态和内核态是可以相互转换的,当应用程序执行系统调用或者是被硬件中断挂起时,linux操作系统都会从用户态切换到内核态。当系统调用完成或者是中断处理完成后操作系统会从内核态返回给用户态,继续执行应用程序。
5、内核的模块性(裁剪性)机制:静态装载和动态装载。
6、不能使用C库开发驱动程序,内核程序中所包含的头文件是指内核代码树中的内核头文件,不是指开发应用时的外部头文件。在内核中实现的库函数中的打印函数printk(),它是c库函数printf()的内核版本,两者具有基本相同的用法和功能。
7、因为内核要求使用常驻的内存空间,因此要求尽量少的占用常驻内存,而尽量多的留出内存提供给用户程序使用,因此内核栈的长度是固定大小的,不可动态增长的,32位机的内核栈是8KB,64位机的内核栈是16KB。
8、linux内核子系统:进程管理、内存管理、文件管理、设备管理和网络管理。
9、linux的kernel下源代码结构目录分析:
(1)arch目录:该目录包含与体系结构有关的代码
(2)drivers目录:该目录包含了linux内核支持的大部分驱动程序,每种驱动程序都占用一个子目录。
(3)fs目录:该目录包含了Linux所支持的所有文件系统相关的代码,每一个子目录中包含一种文件系统。
(4)makefile文件:用来组织内核的各个模块,记录了各个模块之间的相互联系,编译器根据这个文件来编译内核。
其他目录:
10、内核配置:配置文件的组织关系和编译过程
(0)make x210ii_qt_defconfig
(1)主目录中包含很多子目录,同时包含Kbulid和Makefile文件,各个子目录中也包括其他子目录和Kbulid和Makefile文件。
当执行make menuconfig命令时,配置程序会依次从目录由浅入深查找每一个Kbuikld文件,依照这个文件中的数据来生成一个配置菜单,在配置菜单中根据需要配置完成后会在主目录下生成一个.config文件,此文件中保存了配置信息。
(2)进行make命令,会依赖生成的.config文件,来确定哪些功能将会被编译到内核中去,哪些功能不会被编译进去,然后递归进入每一个目录,寻找Makefile文件,编译相应的代码。
11、嵌入式文件系统:
(1)linux支持多种文件系统,为了对各类文件系统进行统一的管理,linux引入了虚拟文件系统VFS,为各类文件系统提供一个统一的操作界面和应用编程接口。
(2)linux文件系统结构由4层构成,分别是用户层、内核层、驱动层和硬件层。
(3)根文件系统以树形结构来组织目录和文件的结构,系统启动后,根文件系统被挂载到根目录"/"上,根文件系统应该包含的目录遵循FHS(文件系统层次)标准。
(4)根文件系统目录结构:
(5)Busybox构建根文件系统。
12、构建第一个驱动程序
(1)内核:内核是一个提供硬件抽象层,磁盘及文件系统控制、多任务等功能的系统软件。
(2)厂商发行版内核和标准版内核的驱动程序是不相互兼容的。
(3)使用uname -r命令来查看内核的版本。
(4)第一个hello world程序:
一:驱动模块程序的组成:
(1)头文件(必选)
#include <linux/module.h>
#include <linux/init.h>
(2)模块参数(可选)
在驱动模块加载时,需要传递给驱动模块的参数,比如一个驱动模块需要完成两种功能,那么就可以通过模块参数选择使用哪一种功能。(步进电机的驱动)
(3)模块功能函数(可选)
(4)其他(可选)
(5)模块加载函数(必选)
模块加载时需要执行的函数,这是模块的初始化函数,就如同main()函数一样。
(6)模块卸载函数(必选)
模块卸载时需要执行的函数,这里清除了加载函数里分配的资源。
(7)模块许可声明(必选)
表示模块受内核支持的程度。
二、Hello World模块.
13、字符设备驱动框架
(1)字符设备是指那些只能一个字节一个字节读写数据的设备,不能随机读取设备内存中的某一数据,其读取数据需要按照先后顺序。字符设备是面向数据流的设备。
(2)块设备:
应用程序可以随机访问设备数据,程序可自行确定读取数据的位置。硬盘是典型的块设备,应用程序可以寻址磁盘上的任何位置,并由此读取数据。此外,数据的读写只能以块(通常是512B)的倍数进行。与字符设备不同,块设备并不支持基于字符的寻址。
两种设备本身并没用严格的区分,主要是字符设备和块设备驱动程序提供的访问接口(file I/O API)是不一样的。
(3)每一个字符设备或者块设备都在/dev 目录下对应一个设备文件,使用命令: cd /dev ,然后ls -l可以查看具体信息,其中第5、6、个字段代表主、此设备号。eg: crw-rw-rw- 1 root dialout 4, 65 Aug16 00:00 ttyS1
(4)一个字符设备或者块设备都有一个主设备号和次设备号,主设备号和次设备号统称为设备号,主设备号用来表示一个特定的驱动程序(表示是哪种驱动程序),次设备号用来表示使用该驱动程序的各个具体子设备。
(5)
(6)静态分配设备号和动态分配设备号(推荐):
静态分配设备号就是驱动程序开发者静态地指定一个设备号,但是这种方式容易产生冲突。我们在指定前一般先查看,使用: cat /proc/devices命令来查看,该文件下包含字符设备和块设备的设备号。
动态分配设备号(推荐):使用alloc_chrdev_region()函数;
(7)
14、设备驱动开发中的并发控制:内核需要提供并发控制机制,对公用资源进行保护。
(0)1、什么是临界区? 答:每个进程中访问临界资源的那段程序称为临界区(临界资源是一次仅允许一个进程使用的共享资源)。每次只准许一个进程进入临界区,进入后不允许其他进程进入。 2、进程进入临界区的调度原则是: ①如果有若干进程要求进入空闲的临界区,一次仅允许一个进程进入。②任何时候,处于临界区内的进程不可多于一个。如已有进程进入自己的临界区,则其它所有试图进入临界区的进程必须等待。③进入临界区的进程要在有限时间内退出,以便其它进程能及时进入自己的临界区。④如果进程不能进入自己的临界区,则应让出CPU,避免进程出现“忙等”现象。
(1)现代操作系统的三大特性:中断处理、多任务处理和多处理器(SMP)。
(2)内核的并发控制机制有:(1)原子变量操作(2)自旋锁(3)信号量(4)完成量
一:原子变量操作(一般用汇编语言实现),只能做计数操作。
原子操作需要硬件的支持跟架构相关。
在linux中定义了两种原子变量操作方法,一种是原子整型操作,另一种是原子位操作。
原子整型操作:
typedef struct
{
volatile int counter;
}atomic_t;
atomic_t 类型的变量只能通过linux内核中定义的专用函数来操作。
操作函数:
1)定义atomic_t类型的变量并初始化值的宏:atomic_t count = ATOMIC_INIT(0);
2)设置atomic_t类型的变量的值:atomic_read(v,i)宏,其中v为要设置值的变量,i为要设置的值。
3)读取atomic_t类型的变量的值:atomic_read(v)宏 .
4)原子变量的加减法函数:atomic_add(int include,volatile atomic_t *v)函数用来加i的值;atomic_sub(int include,volatile atomic_t *v )函数用来减去i的值。
原子位操作:根据数据的每一位进行单独的操作。
操作函数的参数是一个指针和一个位号。
原子位操作定义在文件中。令人感到奇怪的是位操作函数是对普通的内存地址进行操作的。原子位操作在多数情况下是对一个字长的内存地址访问,因而位号该位于0-31之间(在64位机器上是0-63之间),但是对位号的范围没有限制。
原子操作中的位操作部分函数如下:
void set_bit(int nr, void *addr) 原子设置addr所指的第nr位
void clear_bit(int nr, void *addr) 原子的清空所指对象的第nr位
void change_bit(nr, void *addr) 原子的翻转addr所指的第nr位
int test_bit(nr, void *addr) 原子的返回addr位所指对象nr位
int test_and_set_bit(nr, void *addr) 原子设置addr所指对象的第nr位,并返回原先的值
int test_and_clear_bit(nr, void *addr) 原子清空addr所指对象的第nr位,并返回原先的值
int test_and_change_bit(nr, void *addr) 原子翻转addr所指对象的第nr位,并返回原先的值
代码示例:
unsigned long word = 0;
set_bit(0, &word); /*第0位被设置*/
set_bit(1, &word); /*第1位被设置*/
clear_bit(1, &word); /*第1位被清空*/
change_bit(0, &word); /*翻转第0位*/
二:自旋锁(类型位:struct spinlock_t )自旋锁只允许短时间锁定
linux中可以认为有两种锁(对临界资源进行并发控制):自旋锁和信号量。
对自旋锁的操作和使用:
1、定义和初始化自旋锁
spinlock_t lock;//一个自旋锁必须初始化才能使用,使用spin_lock_init(spinlock_t lock)函数进行动态的初始化;
2、锁定自旋锁
spin_lock(lock)宏来锁定。
3、释放自旋锁
当不再使用临界区(通过临界区来访问临界资源)时,使用spin_unlock(lock)宏来释放自旋锁。
综合代码示例:
spinlock_t lock;
spin_lock_init(&lock);
spin_lock(&lock);
临界资源
spin_unlock(&lock);
三:信号量
linux中提供了两种信号量,一种是基于内核程序中的,一种是基于应用程序中的。
linux中,信号量的类型为struct semaphore,
一.什么是信号量
信号量的使用主要是用来保护共享资源,使得资源在一个时刻只有一个进程(线程)
所拥有。
信号量的值为正的时候,说明它空闲。所测试的线程可以锁定而使用它。若为0,说明
它被占用,测试的线程要进入睡眠队列中,等待被唤醒。
二.信号量的分类
在学习信号量之前,我们必须先知道——Linux提供两种信号量:
(1) 内核信号量,由内核控制路径使用
(2) 用户态进程使用的信号量,这种信号量又分为POSIX信号量和SYSTEM
V信号量。
POSIX信号量又分为有名信号量和无名信号量。
有名信号量,其值保存在文件中, 所以它可以用于线程也可以用于进程间的同步。无名
信号量,其值保存在内存中。
倘若对信号量没有以上的全面认识的话,你就会很快发现自己在信号量的森林里迷
失了方向。
三.内核信号量
1.内核信号量的构成
内核信号量类似于自旋锁,因为当锁关闭着时,它不允许内核控制路径继续进行。然而,
当内核控制路径试图获取内核信号量锁保护的忙资源时,相应的进程就被挂起。只有在资源
被释放时,进程才再次变为可运行。
只有可以睡眠的函数才能获取内核信号量;中断处理程序和可延迟函数都不能使用内
核信号量。
内核信号量是struct semaphore类型的对象,它在<asm/semaphore.h>中定义
1、定义并初始化信号量
struct semaphore sema;//定义一个 信号量
void sema_init (struct semaphore *sem, int val);
sema_init(sema,1); //将sem的值置为1,表示资源空闲
sema_init(sema,0); //将sem的值置为0,表示资源忙
2、锁定信号量
void down(struct semaphore * sem); // 可引起睡眠
int down_interruptible(struct semaphore * sem); // down_interruptible能被信号打断
int down_trylock(struct semaphore * sem); // 非阻塞函数,不会睡眠。无法锁定资源则马上返回
3、释放信号量
void up(struct semaphore * sem);
代码示例:
ssize_t globalvar_write(struct file *filp, const char *buf, size_t len, loff_t *off)
{
//锁定信号量
if (down_interruptible(&sem))
{
return - ERESTARTSYS;
}
//将用户空间的数据复制到内核空间的global_var
if (copy_from_user(&global_var, buf, sizeof(int)))
{
up(&sem);
return - EFAULT;
}
//释放信号量
up(&sem);
return sizeof(int);
}
四:完成量
完成量的主要机制就是说实现一个线程发送一个信号通知另一个线程开始执行某个任务,就是说告诉一个线程某个事件已经发生,可以在此事件基础上做你想做的另一个事件了。
完成量的使用:完成量的类型是:struct completion
1、定义和初始化完成量
struct completion com;//定义一个完成量
init_completion(&com);//初始化一个完成量
2、等待完成量(锁定完成量) 该函数会阻塞调用进程,如果所等待的完成量没有被唤醒,那就一直阻塞下去,而且不会被信号打断;
wait_for_completion(&com)函数 //获得完成量
3、释放完成量
当需要同步的任务完成之后,可以使用complete(&com)函数来唤醒完成量,当唤醒之后,wait_for_completion()函数之后的代码才可以继续执行。该函数只唤醒一个正在等待完成量comp的执行单元void complete_all(struct completion* comp):该函数唤醒所有正在等待同一个完成量comp的执行单元;
代码示例:

15、设备驱动中的阻塞和同步机制:
16、内核中的中断处理:
17、内外存访问:
(56)Linux驱动开发之二
标签:释放 linux内核 中断上下文 根目录 通信 静态 cisc 表示 并发控制
原文地址:http://www.cnblogs.com/wycBlog/p/7610998.html