标签:archive bwt .net 位置 sub amp sharp res eof
转自:http://www.cnblogs.com/xudong-bupt/p/3763814.html
具体分析见:http://blog.csdn.net/windroid/article/details/50570450
1.什么是BWT
压缩技术主要的工作方式就是找到重复的模式,进行紧密的编码。
BWT(Burrows–Wheeler_transform)将原来的文本转换为一个相似的文本,转换后使得相同的字符位置连续或者相邻,之后可以使用其他技术如:Move-to-front transform 和 游程编码 进行文本压缩。
2.BWT原理
2.1 BWT编码
(1)首先,BWT先对需要转换的文本块,进行循环右移,每次循环一位。可以知道长度为n的文本块,循环n次后重复,这样就得到看n个长度为n的字符串。如下图中的“Rotate Right”列。(其中‘#’作为标识符,不在文本块的字符集中,这样保证n个循环移位后的字符串均布相同。并且定义‘#‘小于字符集中的任意字符)。
(2)对循环移位后的n个字符串按照字典序排序。如下图中的“Sorted (M)”列。
(3)记录下“Sorted (M)”列中每个字符串的最后一个字符,组成了“L”列。(其中"F"列是“Sorted (M)”列中每个字符串的前缀)
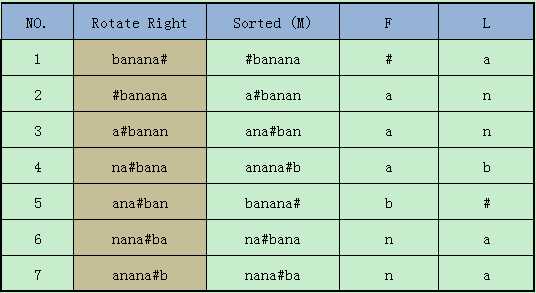
这样,原来的字符串“banana#”就转换为了“annb#aa”。在某些情况下,使用L列进行压缩会有更好的效果。“L”列就是编码的结果。
2.2 BWT解码
因为进行的是循环移位,且是循环左移注意下面的性质:
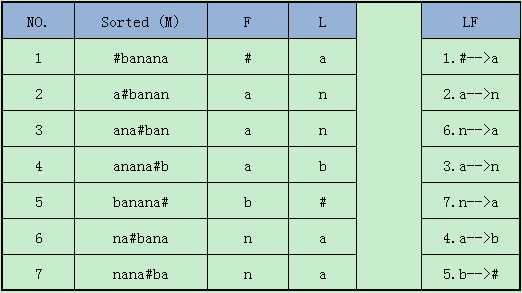
3.BWT文本块编码、解码实例
1 #include <iostream>
2 #include <string>
3 #include <algorithm>
4 #include <string.h>
5 using namespace std;
6
7 ///编码,生成last数组
8 int getLastArray(char *lastArray,const string &str){ ///子串排序
9 int len=str.size();
10 string array[len];
11
12 for(int i=0;i<len;i++){
13 array[i] = str.substr(i);
14 }
15 sort(array,array+len);
16 for(int i=0;i<len;i++){
17 lastArray[i] = str.at((2*len-array[i].size()-1)%len);
18 }
19 return 0;
20 }
21
22 int getCountPreSum(int *preSum,const string &str){
23 memset(preSum,0,27*sizeof(int));
24 for(int i=0;i<str.size();i++){
25 if(str.at(i) == ‘#‘)
26 preSum[0]++;
27 else
28 preSum[str.at(i)-‘a‘+1]++;
29 }
30
31 for(int i=1;i<27;i++)
32 preSum[i] += preSum[i-1];
33 return 0;
34 }
35
36 ///解码,使用last数组,恢复原来的文本块
37 int regainTextFromLastArray(char *lastArray,char *reGainStr,int *preSum){
38 int len=strlen(lastArray);
39 int pos=0;
40 char c;
41 for(int i=len-1;i>=0;){
42 reGainStr[i] = lastArray[pos];
43 c = lastArray[pos];
44 pos = preSum[c-‘a‘]+count(lastArray,lastArray+pos,c);
45 i--;
46 }
47 return 0;
48 }
49
50 int main (){
51 string str("sdfsfdfdsdfgdfgfgfggfgdgfgd#");
52 int preSum[27];
53 int len=str.size();
54
55 char *lastArray = new char[len+1];
56 char *reGainStr = new char[len+1];
57 lastArray[len]=‘\0‘;
58 reGainStr[len]=‘\0‘;
59
60 getCountPreSum(preSum,str);
61 getLastArray(lastArray,str);
62 regainTextFromLastArray(lastArray,reGainStr,preSum);
63
64 cout<<" str: "<<str<<endl;
65 cout<<"lastArray : "<<lastArray<<endl;
66 cout<<"reGainStr : "<<reGainStr<<endl;
67
68 delete lastArray;
69 delete reGainStr;
70 return 0;
71 }
代码执行输出:
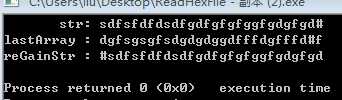
参考:
http://en.wikipedia.org/wiki/Burrows%E2%80%93Wheeler_transform
http://emily2ly.iteye.com/blog/742869
额外阅读:
MTF(Move-to-front transform)数据转换
BWT (Burrows–Wheeler_transform)数据转换算法
标签:archive bwt .net 位置 sub amp sharp res eof
原文地址:http://www.cnblogs.com/skykill/p/7612729.html