标签:blog 2-2 nbsp es2017 movies str 请求 关于 响应
关于模拟浏览器登录的header,可以在相应网站按F12调取出编辑器,点击netwook,如下:
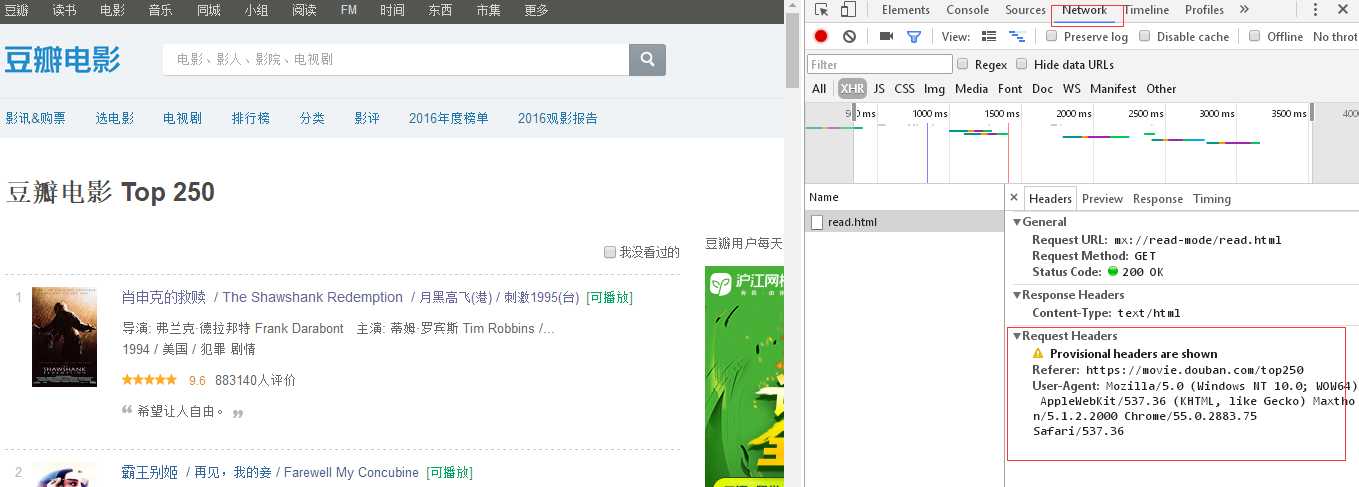
以便于不会被网站反爬虫拒绝。
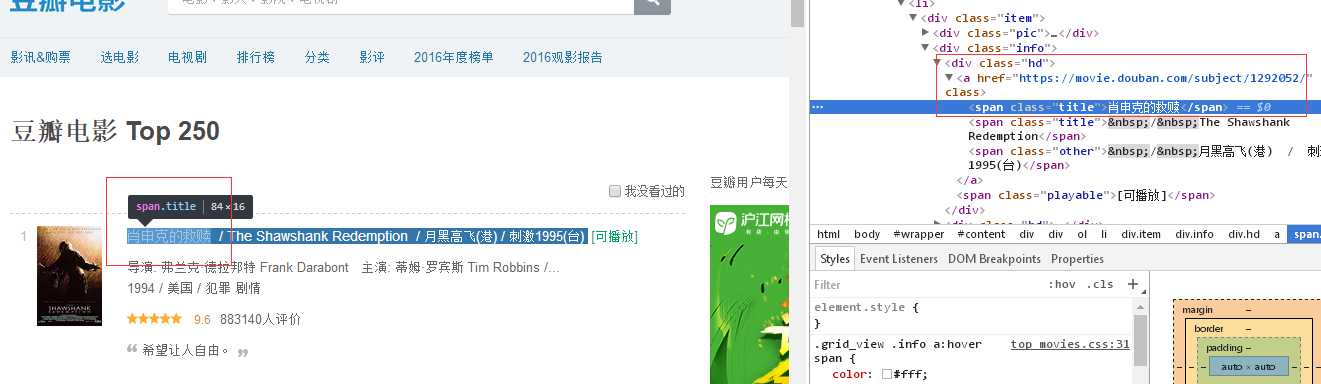
1 import requests 2 from bs4 import BeautifulSoup 5 def get_movies(): 6 headers = { 7 ‘user-agent‘: ‘Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.82 Safari/537.36‘, 8 ‘Host‘: ‘movie.douban.com‘ 9 } 10 movie_list = [] #定义序列 11 for i in range(0, 10): 12 link = ‘https://movie.douban.com/top250?start=‘ + str(i * 25) #通过循环,下载第二页,第三页 13 r = requests.get(link, headers=headers, timeout=10) #timeout=10,响应时长 14 print(str(i + 1), "页响应状态码:", r.status_code) #显示状态码,返回200,请求成功 15 16 soup = BeautifulSoup(r.text, "lxml") 17 div_list = soup.find_all(‘div‘, class_=‘hd‘) #如下图显示,电影名字在div标签之后 18 for each in div_list: 19 movie = each.a.span.text.strip() #span后的文本 20 movie_list.append(movie) #append(movie),在movie_list中添加movie序列
21 return movie_list
24 movies = get_movies()
25 print(movies)
标签:blog 2-2 nbsp es2017 movies str 请求 关于 响应
原文地址:http://www.cnblogs.com/leon507/p/7614345.html