标签:black 二次开发 cal 才有 mon 共享 应该 容器管理 组件
之前的调度框架是基于 Mesos 自研的。采用的语言是 Python。运行了大概两年多的时间了,也一直比较稳定。但随着业务的增长,现有的框架的问题逐渐暴露。
解决上述问题的方案有两个,一个是对现有系统进行改进重构,另一个是迁移到 Kubernetes。我们最终选择迁移到 Kubernetes,主要基于以下考虑。
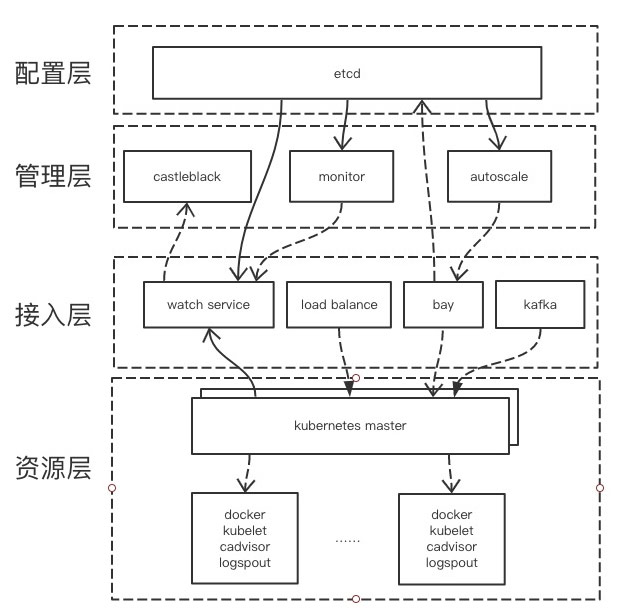
这一层主要是集群资源,主要包括内存、CPU、存储、网络等。主要运行的组件有 Docker daemon、kubelet、cAdvisor、CNI 网络插件等,主要为上层提供资源。
控制层主要包括 Kubernetes 的 master 组件,Scheduler、Controller、API Server。提供对 Kubernetes 集群资源的控制。
这一层包含的东西比较多,主要包含各个平台用于接入 Kubernetes 集群所开发的组件。主要包含以下组件:
主要是根据接入层提供的一些配置或者信息来完成特定的功能。
应用层的组件所需要的配置信息全部由接入层的服务写入到 etcd 中。应用层组件通过 watch etcd 来及时获取配置的更新。
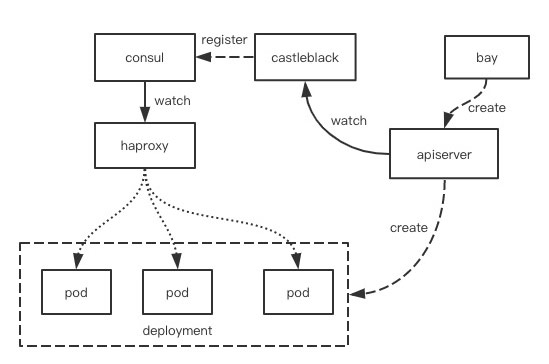
下面这张图说明了在我们的容器平台上,上面描述的一些组件是如何结合在一起,使业务可以对外提供服务的。通过 bay 平台向 Kubernetes APIServer发送请求,创建 deployment,pod 创建成功并且健康检查通过后,Castle Black watch 到 pod 信息,将 IP,port 等信息注册到 Consul 上,HAProxy watch 对应的 Consul key,将 pod 加入其后端列表,并对外提供服务。
我们的监控指标的收集主要是采用 CAvisor。没有采用 Heapster 的主要原因有以下几点:
指标和报警都是用的我们内部比较成熟的系统。
Logspout Kafka ES/HDFS,日志收集我们使用的也是 ELK,但跟通常的 ELK 有所不同。我们这里的 L 用的是 Logspout,一个主要用于收集容器日志的开源软件。我们对其进行了二次开发,使之可以支持动态 topic 收集。我们通过环境变量的形式把 topic 注入到容器中。logspout 会自动发现这个容器并提取出 topic,将该容器的日志发送到 Kafka 对应的 topic 上。因此我们每个业务日志都有自己的 topic,而不是打到一个大的 topic 里面。日志打到 Kafka 里之后,会有相应的 consumer 消费日志,落地 ES 和 HDFS。ES 主要用来作日志查询,HDFS 主要用来做日志备份。
整个日志收集流程如下图所求:

CNI Bridge host-local,网络部分我们做的比较简单。首先我们的每个主机都给分配了一个 C 段的 IP 池,这个地址段里的每个 IP 都是可以跨主机路由的。IP 地址从 X.X.X.2 到 X.X.X.255,容器可以使用的地址是 X.X.X.3 到 X.X.X.224,这个 IP 数量是足够的。然后在主机上创建一个该地址段的 Linux Bridge。容器的 IP 就从 X.X.X.3 到 X.X.X.224 这个地址空间内分配,容器的 veth pair 的一段挂在 Linux Bridge 上,通过 Linux Brigde 进行跨主机通信。性能方面基本没有损耗。
具体的实现我们采用了 Bridge 和 host-local 这两个 CNI 插件,Bridge 主要用来挂载/卸载容器的 veth pair 到 Linux Bridge 上,host-local 主要利用本地的配置来给容器分配 IP。
上述流程如下图所示:
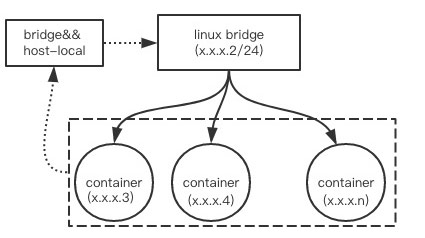
IP 池的分配由我们的云服务商提供,我们不需要管具体的 IP 池的分配与路由配置。
上面主要介绍了知乎在容器和 Kubernetes 应用的一些现状,在这个过程中我们也踩了不少坑,在这里与大家分享一下。
Kubernetes 的较新版本默认使用的存储后端是 etcd3。etcd 选用的版本不对,是会有坑的。etcd 3.10 之前的版本,V3 的 delete api 默认是不会返回被删除的 value 的。导致 Kubernetes API server 会收不到 delete event。被占用的资源会得不到释放。最终导致资源耗尽。scheduler 无法再调度任何任务。详细信息可以看这个 issue(https://github.com/coreos/etcd/issues/4620)。
这个是 Kubernetes 的一个特性,如果由于网络或者机器原因,node 离线了,变为 unready 状态。Kubernetes 的 node controller 会将该 node 上的 pod 删除,称作 pod eviction。这个特性应该说是合理的,但在大概是 1.5 版本之前,当集群中所有的 node 都变为 unready 状态的时候,所有 node 上的 pod 都会被删除。这个其实是不合理的,因为出现这种情况大概率是 API Server 的机器网络出了问题,所以这个时候不应该把所有 node 上的 pod 全部删除。最新的版本将这个特性进行了改进,集群中 ready 的 node 达到一定数量的情况下,才对 not ready 的 node 进行 pod eviction。这个就比较合理了。另外提醒大家一定要做好 API Server 的高可用。
在使用 CNI 网络插件的时候,如果 Docker daemon 发生了重启,会重新分配新的 IP,但旧的 IP 不会被释放,会导致 IP 地址的泄漏。由于时间和精力问题,我们采取了比较 tricky 的方式,在 Docker dameon 启动之前,我们会默认把本机的 IP 全部释放掉。这个是通过 Supervisor 的启动脚本来实现的。希望后续 Kubernetes 社区可以从根本上解决这个问题。
Docker 使用过程中也遇到了一些 bug。比如 docker ps 会卡住, 使用 portmapping 会遇到端口泄漏的问题等。我们内部自己维护了一个分支,修复了类似的问题。Docker daemon 是基础,它的稳定性一定要有保证,整个系统的稳定性才有保证。
Kubernetes 的 Controller manager、Scheduler、以及 API Server 都是有默认的 rate limit 的,在集群规模较大的时候,默认的 rate limit 肯定是不够用的,需要自己进行调整。
https://www.kubernetes.org.cn/2508.html
标签:black 二次开发 cal 才有 mon 共享 应该 容器管理 组件
原文地址:http://www.cnblogs.com/allcloud/p/7614275.html