标签:spark class tar int end toc http 可变对象 结束
对于公有的方法,要用javadoc的@throws标签(tag)在文档中说明违反参数值限制时会抛出的异常。这样的异常通常为IllegalArgumentException, IndexOutOfBoundsException或NullPointerException.

非公有的方法通常应该使用断言(assertion)来检查它们的参数,具体做法如下所示:

没有对象的帮助时,虽然另个类不可能修改对象的内部状态,但是对象很容易在无意识的情况下提供这种帮助。例如,考虑下面的类,它声称可以表示一段不可变的时间周期:
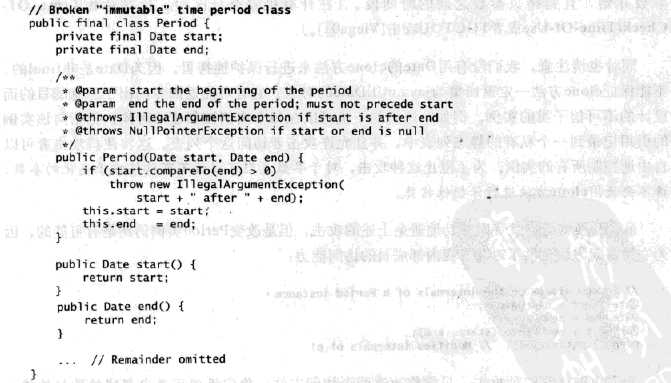
乍一看,这个类似乎是不可变的,并且强加了约束条件:周期的起始时间(start)不能在结束时间(end)之后。然而,因为Date类本身是可变的,因此很容易违反这个约束条件:

为了保护Period实例的内部信息避免受到这种攻击,时于构造器的每个可变参数进行保护性烤贝( defensive copy)是必要的,并且使用备份对象作为Period实例的组件,而不使用原始的对象:

注意,保护性拷贝是在检查参数的有效性之前进行的,并且有效性检查是针时拷贝之后的对象,而不是针时原始的时象。虽然这样做看起来有点不太自然,却是必要的。
一个反例:
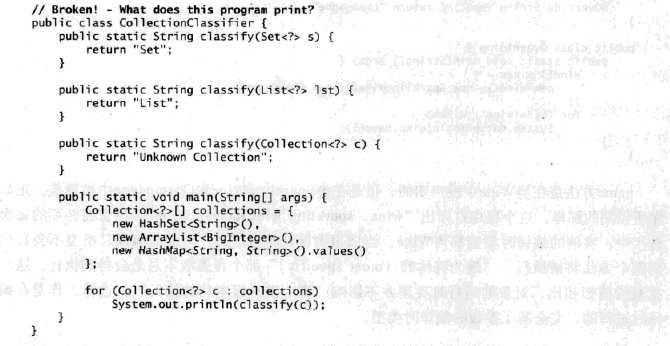
你可能期望这个程序会打印出"Set" ,紧接着是“List",以及“Unknown Collection" ,但实际上不是这样。它是打印“Unknown Collection"三次。
classify方法被重载(overloaded)了,而要调用哪个重载(overloading)方法是在编译时做出决定的。对于for循环中的全部三次迭代,参数的编译时类型都是相同的:Collections<>。每次迭代的运行时类型都是不同的,但这并不影响对重载方法的选择。因为该参数的编译时类型为Collection<>.
这个程序的行为有悖常理,因为对于重载方法(overloaded method ]的选择是静态的,而对于被覆盖的方法(overridden method)的选择则是动态的。选择被覆盖的方法的正确版本是在运行时进行的,选择的依据是被调用方法所在对象的运行时类型。

name方法是在类Wine中被声明的,但是在类SparklingWine和Champagne中被覆盖。正如你所预期的那样,这个程序打印出“wine, sparkling wine和champagne" ,尽管在循环的每次迭代中,实例的编译时类型都为Wine。当调用被覆盖的方法时,对象的编译时类型不会影响到哪个方法将被执行; “最为具体的(most specific)”那个覆盖版本总是会得到执行。
对classify方法的最佳修正方案是,用单个方法来替换这三个重载的classify方法,并在这个方法中做一个显式的instanceof测试:

因为覆盖机制是规范,而重载机制是例外,所以,覆盖机制满足了人们对于方法调用行为的期望。正如CollectionClassifier例子所示,重载机制很容易使这些期望落空。
到底怎样才算胡乱使用重载机制呢?这个问题仍有争议. 安全而保守的策略是,永远不要导出两个具有相同参数数目的重载方法。如果方法使用可变参数(varargs),保守的策略是根本不要重载它.
你始终可以给方法起不同的名称,而不使用重载机制。
对于构造器,你没有选择使用不同名称的机会;一个类的多个构造器总是重载的。在许多情况下,可以选择导出静态工厂,而不是构造器.
JDK一个反例
在Java 1.5发行版本之前,所有的基本类型都根本不同于所有的引用类型。但是当自动装箱出现之后,就不再如此了,它会导致真正的麻烦。考虑下面这个程序:

如果像大多数人一样。希望程序从集合和列表中去除非整数值(0, 1和2),并打印出[-3, -2, -1] [-3, -2, -1]。事实上,打印出[-3, -2, -1] [-2, 0, -2] .
实际发生的情况是: set.remove(i)调用选择重载方法remove(E),这里的E是集合(Integer)的元素类型,将i从int自动装箱到Integer中。这是你所期待的行为,因此程序不会从集合中去除正值。另一方面,list.remove(i)调用选择重载方法remove(int i),它从列表的指定位置上去除元素。
可变参数方法接受0个或者多个指定类型的参数。可变参数机制通过先创建一个数组,数组的大小为在调用位置所传递的参数数量,然后将参数值传到数组中,最后将数组传递给方法。
printf和反射机制都从可变参数中极大地受益。
对于一个返回null而不是零长度数组或者集合的方法,几乎每次用到该方法时都需要这种曲折的处理方式。这样做很容易出错,因为编写客户端程序的程序员可能会忘记写这种专门的代码来处理null返回值。
有时候会有人认为:null返回值比零长度数组更好,因为它避免了分配数组所需要的开销。这种观点是站不住脚的,原因有两点口第一,在这个级别上担心性能问题是不明智的,除非分析表明这个方法正是造成性能问题的真正源头(见第55条)。第二,对于不返回任何元素的调用,每次都返回同一个零长度数组是有可能的,因为零长度数组是不可变的,而不可变对象有可能被自由地共享(见第15条).
比如可以这样做:


同样地,集合值的方法也可以做成在每当需要返回空集合时都返回同一个不可变的空集合。Collections.emptySet, emptyList和emptyMap方法提供的正是你所需要的,如下所示:

简而言之,返回类型为数组或集合的方法没理由返回null,而不是返回一个零长度的数组或者集合。
为了正确地编写API文档,必须在每个被导出的类、接口、构造器、方法和域声明之前增加一个文档注释。
多行的代码示例前使用字符
{ @code ,然后在代码后面加上}。
不要忘记,为了产生包含HTML元字符的文档,比如小于号(<)、大于号(>)以及“与”号(&),必须采取特殊的动作。让这些字符出现在文档中的最佳办法是用{@literal}标签将它们包围起来,这样就限制HTML标记和嵌套的Javadoc标签的处理。
Java 1.5发行版本中增加的三个特性在文档注释中需要特别小心:泛型、枚举和注解. 当为泛型或者方法编写文档时,确保要在文档中说明所有的类型参数。

当为枚举类型编写文档时,要确保在文档中说明常童,以及类型,还有任何公有的方法。注意,如果文档注释很简短,可以将整个注释放在一行上:

为注解类型编写文档时,要确保在文档中说明所有成员,以及类型本身。

从Java 1.5发行版本开始,包级私有的文档注释就应该放在一个称作package-info.java的文件中,而不是放在package.html中。除了包级私有的文档注释之外,package-info.java也可以(但并非必需)包含包声明和包注解。
Javadoc具有“继承”方法注释的能力。如果API元素没有文档注释,Javadoc将会搜索最为适用的文档注释,接口的文档注释优先于超类的文档注释。
也可以利用{@inheritDoc}标签从超类型中继承文档注释的部分内容。这意味着,不说别的,类还可以重用它所实现的接口的文档注释,而不需要拷贝这些注释。
标签:spark class tar int end toc http 可变对象 结束
原文地址:http://www.cnblogs.com/myitroad/p/7614660.html