标签:pre html 正则 表达式 imp 技术分享 images www base
无意间看到了网上python爬1024的文章,就想着晚点自己去撸一个全自动小电影下载器(就不用每次选半天了),上班挂着,下班回去就可以看了(身体已经被妹纸掏空了,还看),于是自己先试着写一个简单的爬虫,目标自然是博客园:使用简单的正则表达式匹配,当然也可以使用网上广泛使用的BeautifulSoup解析网页
import requests import re baseUrl = "https://www.cnblogs.com/" html = requests.get(baseUrl).text items=re.findall("_blank\">(.+)</a></h3>",html) for i in items: print(i) print("") print("over")
爬的内容非常简单,就是首页上的文章列表,虽然C#也可以做,但是感觉python真的是精简,几句代码就搞定了,厉害了word python!效果如下
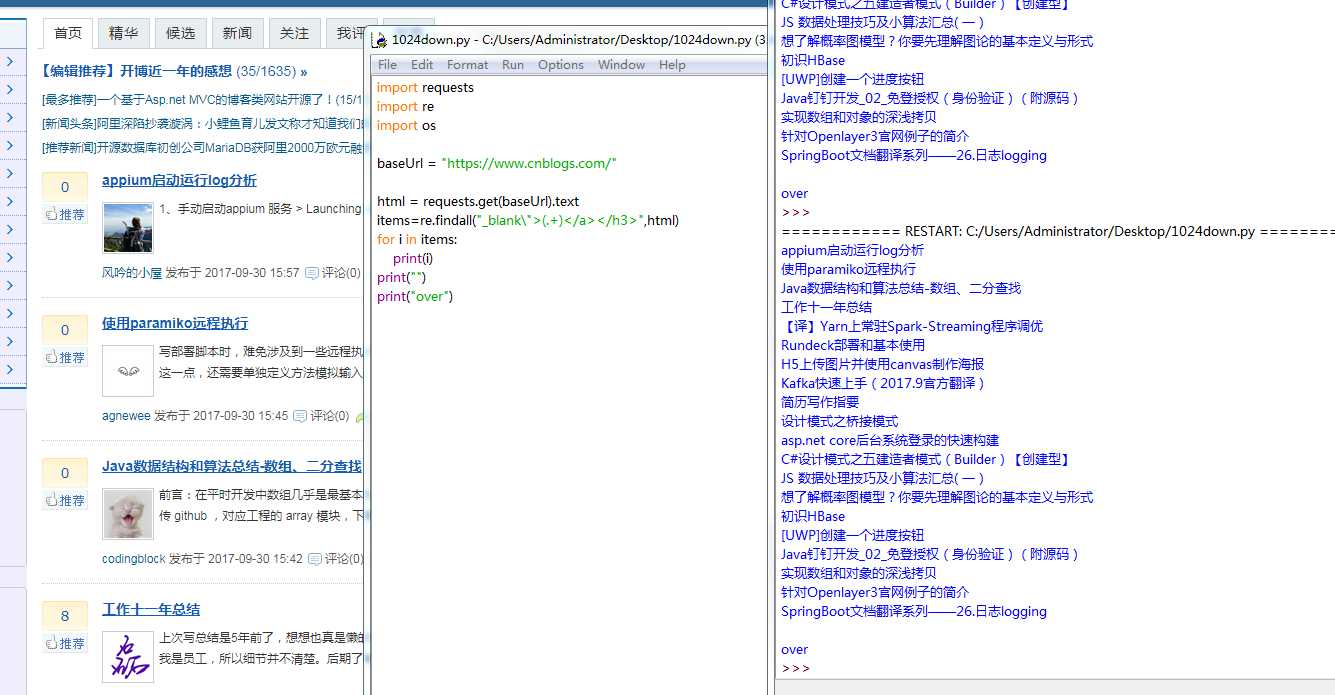
已经等不及下班回去开干了!
标签:pre html 正则 表达式 imp 技术分享 images www base
原文地址:http://www.cnblogs.com/HelliX/p/7615351.html