标签:扫描 为我 inno 地址 博客 来讲 data log 它的
因为我们大多数情况下使用的都是Innodb,所以这篇博客主要依据Innodb来讲
b+树(图片来自网络)
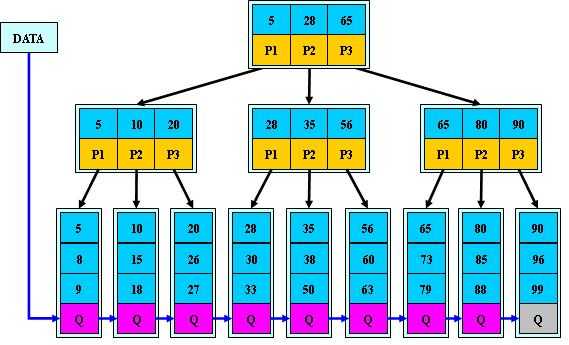
b+树图来自网络
1.聚集索引与非聚集索引区别
聚集索引:叶子节点包含完整的数据(物理地址连续),叫做聚集索引
非聚集索引(又称辅助索引):它的叶子节点并不包含行记录的全部数据,叶子结点除了包含键值以外,每个叶子结点中的索引行还包含了一个书签,该书签用来告诉存储引擎可以在哪找到相应的数据行。需要引用主索引作为data域,其实原理就是直接通过辅助索引无法找到数据,需要通过辅助索引找到主键,然后再根据主索引去查找其对应叶子节点的数据。其过程就是(辅助索引+主键+columns值)。
2.分页需要优化原因
例:select a from table where b=1
①如果b字段没有索引,则数据库会进行全表扫描,扫描所有的数据库
②如果b字段有索引,索引需要扫描3个数据块
⑴获取所有b=1的主键与其rowid
⑵再根据rowid查找数据。
⑶如果数据不在该数据块回表,如果a在索引中则不会表。
其缓慢的原因其实是因为辅助索引需要回表去根据主键再去查询。
3.分页具体实现
例:select book_name,book_info from libary limit 20000,10 (表主键为其id)
覆盖索引:包含所有满足查询需要的索引成为覆盖索引
即(id,book_name,book_info)作为组合索引,就是覆盖索引的一种体现
标签:扫描 为我 inno 地址 博客 来讲 data log 它的
原文地址:http://www.cnblogs.com/boycelee/p/7615471.html