标签:char 代码结构 合成 数据 结果 div erp byte c语言实现
上一节实现了主GPT头的信息提取,这一节继续提取整个的GPT数据,并且将GPT分区表和MBR分区表两种格式融合成一个模块,使主调函数(也可以说是使用者)不需要关心磁盘的分区表类型:它太底层了,确实不需要过多的关心。
继续看上一节的图1,这里就不贴图了,LBA1的主GPT头给出了分区信息的总数,还有每一个分区信息所占用的字节数,分区信息的结构如表1:
表1 分区信息结构(GPT Entry)
|
字节偏移量 |
数据长度(字节) |
范例数值 |
数据项说明 |
|
0x00 |
16 |
28 73 2A C1 1F F8 D2 11 BA 4B 00 A0 C9 3E C9 3B |
用GUID表示的分区类型 |
|
0x10 |
16 |
82 63 7A C8 13 0E F8 46 95 29 E6 31 E9 16 B5 42 |
用GUID表示的分区唯一标示符 |
|
0x20 |
8 |
00 08 00 00 00 00 00 00 |
该分区的起始扇区,用LBA值表示 |
|
0x28 |
8 |
FF 27 E6 31 E9 16 B5 42 |
该分区的结束扇区(包含),用LBA值表示,通常是奇数 |
|
0x30 |
8 |
00 00 00 00 00 00 00 80 |
该分区的属性标志 |
|
0x38 |
72 |
|
UTF-16LE编码的人类可读的分区名称,最大32个字符 |
可以看到,这个结构非常之简洁,只标注了起始扇区,结束扇区,分区类型,GUID,属性,分区名,而不关心磁头、磁道等等信息。
需要特殊说明的是,整个分区信息的结构,也就是从LBA2到LBA34(MS总是给划分128个分区信息),是完全连续的,不依靠任何扇区等信息去定位,也就是说,第n个分区信息的结构起始地址,仅仅根据LBA2的起始地址+分区字节数*n来确定,最常见的是微软定义的128个分区信息,512字节扇区,128字节的分区信息字节数,所以最常见的是每一个扇区4个分区信息,密集的排列32个扇区。然而正确的计数方法是每128个字节一个分区信息,密集排列128个。当扇区不是512字节时(注意这里不要跟簇混淆,目前我还没见过不是512字节扇区的存储器),每个扇区存储的分区信息有可能不是4个,下面的程序规避了这个问题,采用了一个新的磁盘读写函数——ReadDiskData而不是ReadSectorData——来防止读分区信息出现错误。
1 /******************************************************************************* 2 3 函 数 名:GetVolumeNumberOfGPT 4 5 函数功能:获取一个GPT格式的磁盘中有效分卷数 6 7 输入参数: 8 9 hDisk:磁盘句柄 10 11 DPT: 磁盘DPT 12 13 返回参数:int型,返回DPT中包含的有效分区数量(包含未格式化的分卷),如果该DPT不是GPT 14 15 分区形式,将会返回-1 16 17 *******************************************************************************/ 18 19 int GetVolumeNumberOfGPT(HANDLE hDisk, DPT_Info* DPT) 20 21 { 22 23 if (DPTDetermination(DPT) == DPT_MBR) 24 25 return -1; 26 27 GPTEntry_Byte GPTEbuffer; 28 29 GPTEntry_Info GPTEinfo; 30 31 PGPTH_Info PGPTH; 32 33 GetPGPTH(hDisk, &PGPTH); 34 35 int ValidPartitions = 0; 36 37 for (int i = 0; i < PGPTH.PartitionTables; i++) 38 39 { 40 41 ReadDiskData( 42 43 hDisk, //读取磁盘句柄 44 45 SECTOR_SIZE * PGPTH.PartitionStart + i * PGPTH.BytesPerPartitionTable, //计算读取的GPTE位置 46 47 (uint8_t*)(void*)&GPTEbuffer, //缓冲区地址 48 49 sizeof(GPTEntry_Byte)); //字节数 50 51 GetGPTEInfo(&GPTEbuffer, &GPTEinfo); 52 53 if (GUIDcmp(&(GPTEinfo.TypeGUID), (GUID_Info*)&GUID_ptUnuse)) 54 55 break; 56 57 else 58 59 ValidPartitions++; 60 61 } 62 63 return ValidPartitions; 64 65 }
分区类型是有规定的,一般有表2的几种GUID;属性标志也是有规定的,见表3。
表2:分区类型的16Byte GUID
|
数值 |
类型说明 |
|
00000000-0000-0000-0000-000000000000 |
未使用 |
|
024DEE41-33E7-11D3-9D69-0008C781F39F |
MBR分区表 |
|
C12A7328-F81F-11D2-BA4B-00A0C93EC93B |
EFI系统分区[EFI System partition (ESP)],必须是VFAT格式 |
|
BC13C2FF-59E6-4262-A352-B275FD6F7172 |
扩展boot分区,必须是VFAT格式 |
|
21686148-6449-6E6F-744E-656564454649 |
BIOS引导分区,其对应的ASCII字符串是"Hah!IdontNeedEFI"。 |
|
D3BFE2DE-3DAF-11DF-BA40-E3A556D89593 |
Intel Fast Flash (iFFS) partition (for Intel Rapid Start technology) |
|
E3C9E316-0B5C-4DB8-817D-F92DF00215AE |
微软保留分区 |
|
EBD0A0A2-B9E5-4433-87C0-68B6B72699C7 |
基本数据分区 |
|
DE94BBA4-06D1-4D40-A16A-BFD50179D6AC |
Windows恢复环境 |
|
0FC63DAF-8483-4772-8E79-3D69D8477DE4 |
数据分区。Linux曾经使用和Windows基本数据分区相同的GUID。 |
|
44479540-F297-41B2-9AF7-D131D5F0458A |
x86根分区 (/) 这是systemd的发明,可用于无fstab时的自动挂载 |
|
4F68BCE3-E8CD-4DB1-96E7-FBCAF984B709 |
x86-64根分区 (/) 这是systemd的发明,可用于无fstab时的自动挂载 |
|
69DAD710-2CE4-4E3C-B16C-21A1D49ABED3 |
ARM32根分区 (/) 这是systemd的发明,可用于无fstab时的自动挂载 |
|
B921B045-1DF0-41C3-AF44-4C6F280D3FAE |
AArch64根分区 (/) 这是systemd的发明,可用于无fstab时的自动挂载 |
|
3B8F8425-20E0-4F3B-907F-1A25A76F98E8 |
服务器数据分区(/srv) 这是systemd的发明,可用于无fstab时的自动挂载 |
|
933AC7E1-2EB4-4F13-B844-0E14E2AEF915 |
HOME分区 (/home) 这是systemd的发明,可用于无fstab时的自动挂载 |
|
0657FD6D-A4AB-43C4-84E5-0933C84B4F4F |
交换分区(swap) 不是systemd的发明,但同样可用于无fstab时的自动挂载 |
|
A19D880F-05FC-4D3B-A006-743F0F84911E |
RAID分区 |
|
E6D6D379-F507-44C2-A23C-238F2A3DF928 |
逻辑卷管理器(LVM)分区 |
|
8DA63339-0007-60C0-C436-083AC8230908 |
保留 |
上面的GUID数值比较有意思,根据winHex得到的扇区数据,它将16字节的GUID分成了5部分,在很多编译器中已经有GUID结构体的定义不过是4部分的,在这里无法使用,所以我们另外定义一个结构
1 typedef struct 2 3 { 4 5 uint32_t Part1; //GUID第1部分 6
7 uint16_t Part2; //GUID第2部分 8 9 uint16_t Part3; //GUID第3部分 10 11 uint16_t Part4; //GUID第4部分 12 13 uint48_t Part5; //GUID第5部分 14 15 }GUID_Info;
来表示GUID。而有意思的地方在于,这5部分并不是单纯的完全大端或者小端模式,它是混合着来的,前三个部分是小端,后两个部分是大端,我们在读取结构的时候一定要注意这点。
表3:分区属性
|
数值 |
类型说明 |
|
0 |
系统分区 |
|
1 |
EFI隐藏分区(EFI不可见分区) |
|
2 |
传统的BIOS的可引导分区标志 |
|
60 |
只读 |
|
62 |
隐藏 |
|
63 |
不自动挂载,也就是不自动分配盘符 |
以上的属性列表并不完全,至少我的硬盘分区之后,类型就是0x80。因为只有一个字节有用的信息,一个枚举类型就足以解决问题。
现在我们实际看一个拥有4个分区信息的LBA,如图1:

图1 LBA分区
如图所示,红框框起来的部分就是一个分区信息结构,比较精髓的部分是粉色框里的72字节,它是以UTF16的小端模式编码的,因为涉及到了中文问题,UTF16LE解码比较复杂,在这里我们直接用wchar_t来获取这个结构:
1 typedef struct 2 3 { 4 5 uint8_t TypeGUID[16]; //用GUID表示的分区类型 6 7 uint8_t UniqueGUID[16]; //用GUID表示的分区唯一标示符 8 9 uint8_t SectorStart[8]; //该分区的起始扇区,用LBA值表示 10 11 uint8_t SectorEnd[8]; //该分区的结束扇区(包含),用LBA值表示,通常是奇数 12 13 uint8_t PartitionAttrib[8]; //该分区的属性标志 14 15 WCHAR PartitionName[36]; //UTF-16LE编码的人类可读的分区名称,最大32个字符。 16 17 }GPTEntry_Byte;
现在GPT结构已经可以完整的读取,由于博文实在实验阶段性完成后做的,所以没有截图(=_=尴尬)。
接下来的步骤是整合GPT和MBR。由于DPT引导到GPT和MBR的部分可以直接整合,所以原DPT部分代码可以不动,但不同的是GPT是通过读取LBA直接得到每个分区的起始扇区、终止扇区、分区类型等等,而MBR方式是先通过DPT得到小于等于4个引导扇区的位置,然后对这几个引导扇区进行解析,每个引导扇区对应一个分区信息。
在使用其他的一些库的时候,笔者受到困扰的地方就是,API函数太多,有很多的库有不同的API功能是接近的,同时又有很多API名字相近但功能截然不同,所以为了避免这种情况,在这里尽量缩减API。根据这个思想,可以构建大致的流程如下:首先由用户提取分区总数,然后用户来进行malloc操作来根据分区数建立分区列表,然后根据分区列表可以找到每个分区的引导扇区位置。在本节中,所谓的“分区信息”是针对于分区表的分区信息,事实上根据前几节的介绍,分卷容量并不一定等于分区容量,所以目前的代码中都是以Partition代表分区,而以Volume代表分卷。
详细的代码结构这里不进行更多的截取,有关代码的调用方式在main.cpp中很容易的看到。在压缩包里有基于VS2015community环境的完整工程。
最后贴上一张完整的分区列表运行结果(磁盘3是我的移动硬盘,磁盘4是我的64GB SD卡)。
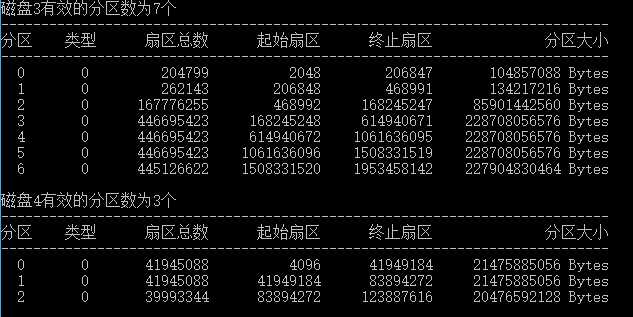
图2 代码运行结果
工程下载地址:https://files.cnblogs.com/files/Coder-Ku/NTFS5.rar
在STM32上实现NTFS之5:GPT分区表的C语言实现(2)GPT实现以及统一方式读取磁盘分区
标签:char 代码结构 合成 数据 结果 div erp byte c语言实现
原文地址:http://www.cnblogs.com/Coder-Ku/p/7628078.html