标签:-- scott sql查询语句 use com 策略 art 优化 表示
什么是视图【View】
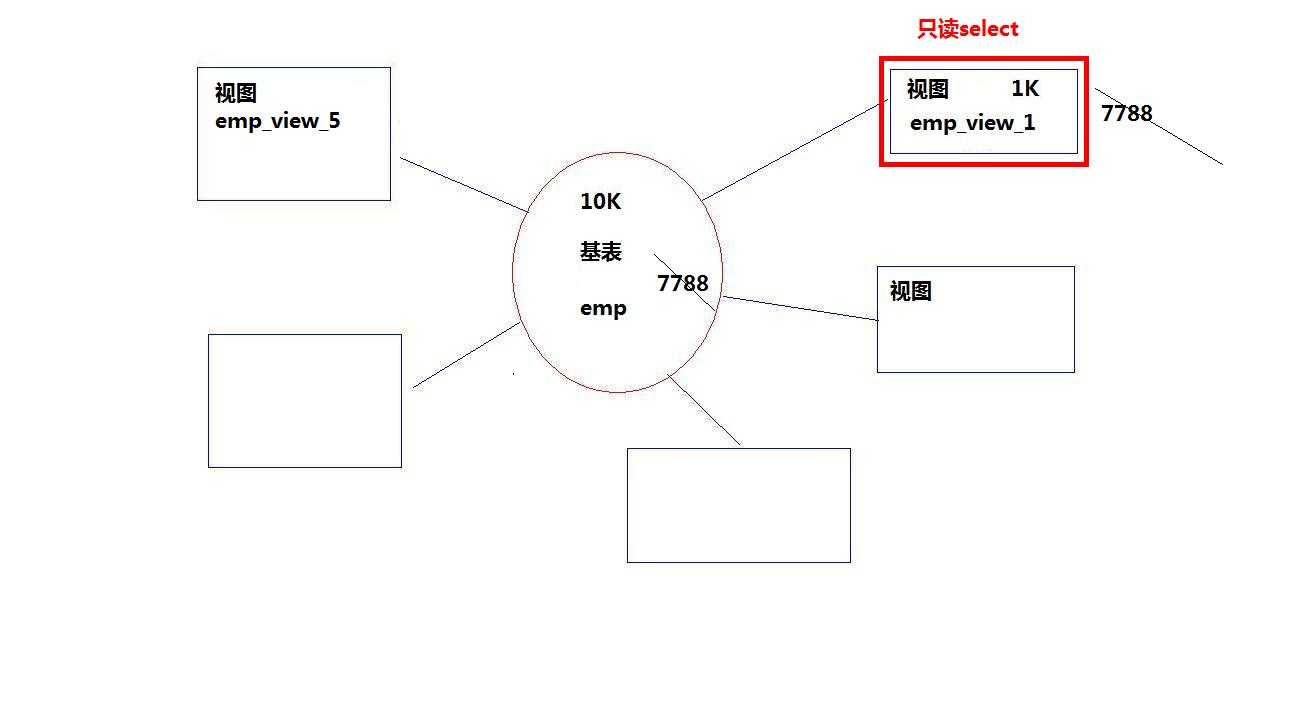
(1)视图是一种虚表
(2)视图建立在已有表的基础上, 视图赖以建立的这些表称为基表
(3)向视图提供数据内容的语句为 SELECT 语句,可以将视图理解为存储起来的 SELECT 语句
(4)视图向用户提供基表数据的另一种表现形式
(5)视图没有存储真正的数据,真正的数据还是存储在基表中
(6)程序员虽然操作的是视图,但最终视图还会转成操作基表
(7)一个基表可以有0个或多个视图
什么情况下会用到视图
(1)如果你不想让用户看到所有数据(字段,记录),只想让用户看到某些的数据时,此时可以使用视图
(2)当你需要减化SQL查询语句的编写时,可以使用视图,但不提高查询效率
视图应用领域
(1)银行,电信,金属,证券军事等不便让用户知道所有数据的项目中
视图的作用
(1)限制数据访问
(2)简化复杂查询
(3)提供数据的相互独立
(4)同样的数据,可以有不同的显示方式
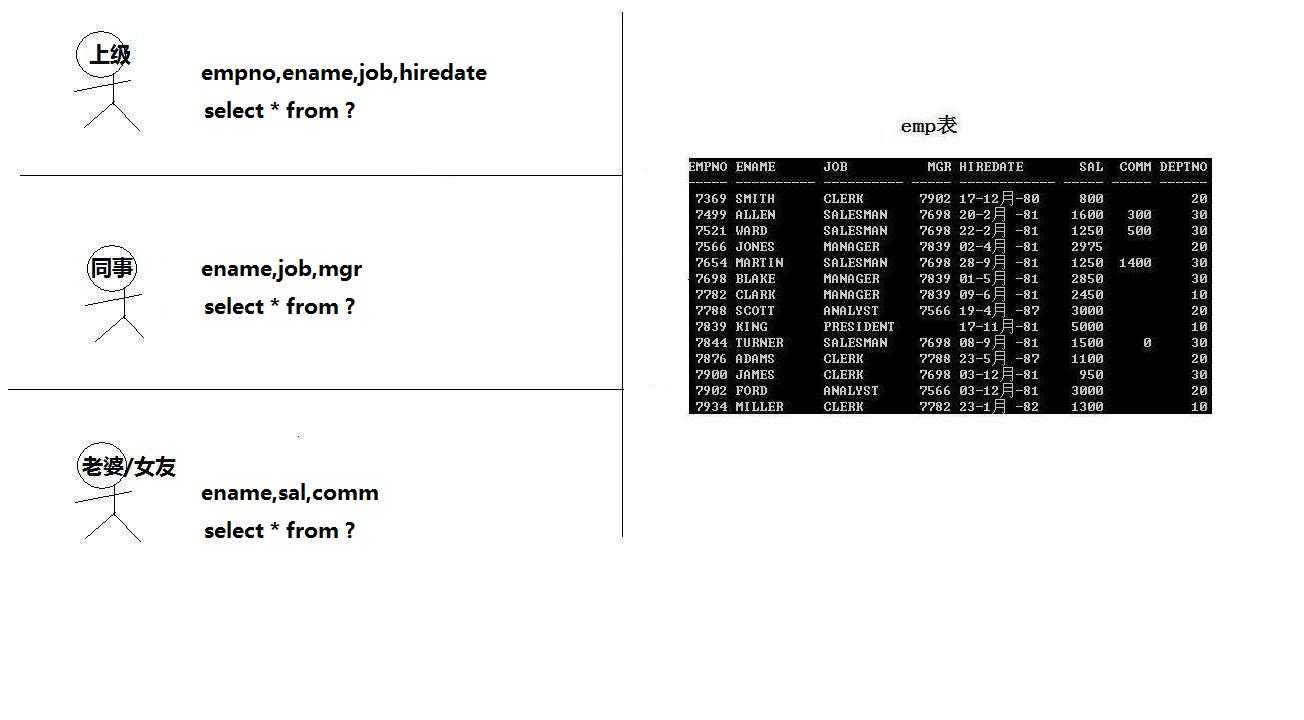
基于emp表所有列,创建视图emp_view_1,create view 视图名 as select对一张或多张基表的查询
create view emp_view_1
as
select * from emp;
默认情况下,普通用户无权创建视图,得让sysdba为你分配creare view的权限
以sysdba身份,授权scott用户create view权限
grant create view to scott;
以sysdba身份,撤销scott用户create view权限
revoke create view from scott;
基于emp表指定列,创建视图emp_view_2,该视图包含编号/姓名/工资/年薪/年收入(查询中使用列别名)
create view emp_view_2
as
select empno "编号",ename "姓名",sal "工资",sal*12 "年薪",sal*12+NVL(comm,0) "年收入"
from emp;
基于emp表指定列,创建视图emp_view_3(a,b,c,d,e),包含编号/姓名/工资/年薪/年收入(视图中使用列名)
create view emp_view_3(a,b,c,d,e)
as
select empno "编号",ename "姓名",sal "工资",sal*12 "年薪",sal*12+NVL(comm,0) "年收入"
from emp;
查询emp_view_3创建视图的结构
desc emp_view_3;
修改emp_view_3(id,name,salary,annual,income)视图,create or replace view 视图名 as 子查询
create or replace view emp_view_3(id,name,salary,annual,income)
as
select empno "编号",ename "姓名",sal "工资",sal*12 "年薪",sal*12+NVL(comm,0) "年收入"
from emp;
查询emp表,求出各部门的最低工资,最高工资,平均工资
select min(sal),max(sal),round(avg(sal),0),deptno
from emp
group by deptno;
创建视图emp_view_4,视图中包含各部门的最低工资,最高工资,平均工资
create or replace view emp_view_4
as
select deptno "部门号",min(sal) "最低工资",max(sal) "最高工资",round(avg(sal),0) "平均工资"
from emp
group by deptno;
创建视图emp_view_5,视图中包含员工编号,姓名,工资,部门名,工资等级
create or replace view emp_view_5
as
select e.empno "编号",e.ename "姓名",e.sal "工资",d.dname "部门名",s.grade "工资等级"
from emp e,dept d,salgrade s
where (e.deptno=d.deptno) and (e.sal between s.losal and s.hisal);
删除视图emp_view_1中的7788号员工的记录,使用delete操作,会影响基表吗
delete from emp_view_1 where empno=7788;写法正确,会影响基表
修改emp_view_1为只读视图【with read only】,再执行上述delete操作,还行吗?
create or replace view emp_view_1
as
select * from emp
with read only;
不能进行delete操作了
删除视图中的【某条】记录会影响基表吗?
会影响基表
将【整个】视图删除,会影响表吗?
不会影响基表
删除视图,会进入回收站吗?
不会进入回收站
删除基表会影响视图吗?
会影响视图
闪回基表后,视图有影响吗?
视图又可以正常工作了
-------------------------------------------------------------------------------------同义词
什么是同义词【Synonym】
(1)对一些比较长名字的对象(表,视图,索引,序列,。。。)做减化,用别名替代
同义词的作用
(1)缩短对象名字的长度
(2)方便访问其它用户的对象
创建与salgrade表对应的同义词,create synonym 同义词 for 表名/视图/其它对象
create synonym e for salgrade;
create synonym ev5 for emp_view_5;
以sys身份授予scott普通用户create synonym权限
grant create synonym to scott;
以sys身份从scott普通用户撤销create synonym权限
revoke create synonym from scott;
使用同义词操作salgrade表
select * from s;
删除同义词
drop synonym ev5;
删除同义词,会影响基表吗?
不会影响基表
删除基表,会影响同义词吗?
会影响同义词
-------------------------------------------------------------------------------------序列
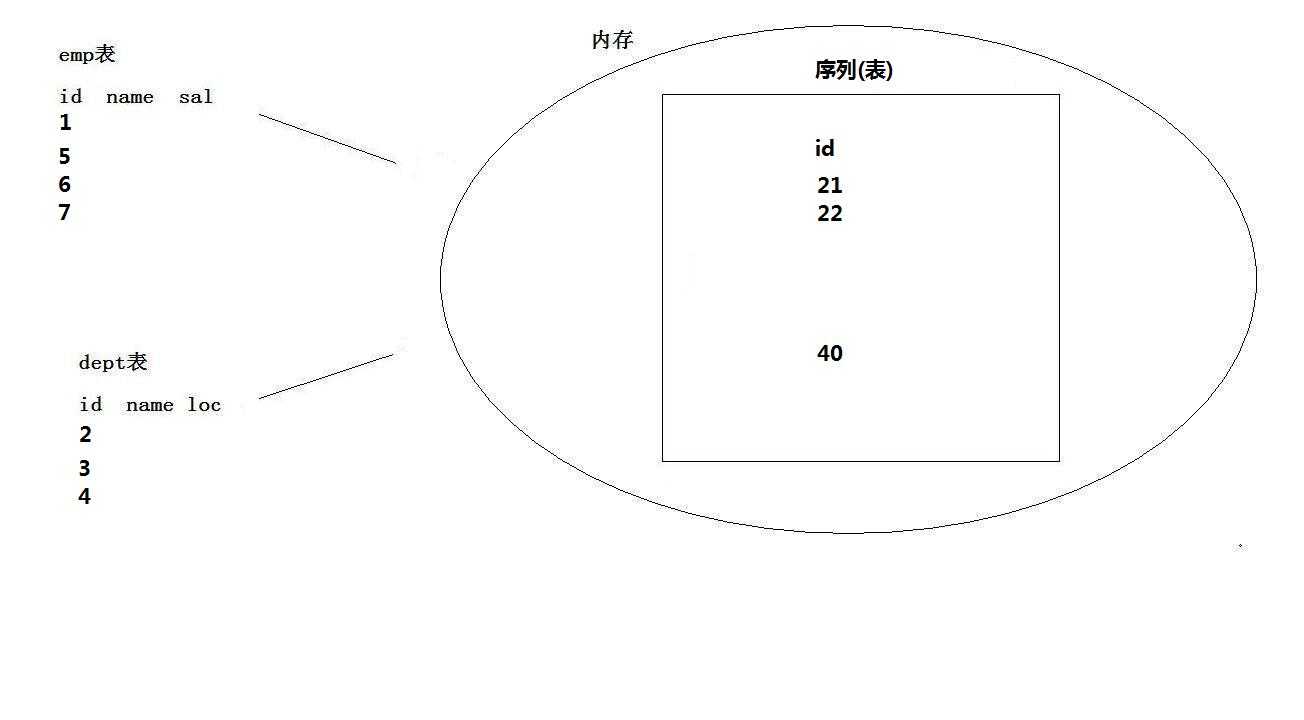
什么是序列【Sequence】
(1)类似于MySQL中的auto_increment自动增长机制,但Oracle中无auto_increment机制
(2)是oracle提供的一个产生唯一数值型值的机制
(3)通常用于表的主健值
(4)序列只能保证唯一,不能保证连续
声明:oracle中,只有rownum永远保持从1开始,且继续
(5)序列值,可放于内存,取之较快
题问:为什么oracle不直接用rownum做主健呢?
rownum=1这条记录不能永远唯一表示SMITH这个用户
但主键=1确可以永远唯一表示SMITH这个用户
为什么要用序列
(1)以前我们为主健设置值,需要人工设置值,容易出错
(2)以前每张表的主健值,是独立的,不能共享
为emp表的empno字段,创建序列emp_empno_seq,create sequence 序列名
create sequence emp_empno_seq;
删除序列emp_empno_seq,drop sequence 序列名
drop sequence emp_empno_seq;
查询emp_empno_seq序列的当前值currval和下一个值nextval,第一次使用序列时,必须选用:序列名.nextval
select emp_empno_seq.nextval from dual;
select emp_empno_seq.currval from dual;
使用序列,向emp表插入记录,empno字段使用序列值
insert into emp(empno) values(emp_empno_seq.nextval);
insert into emp(empno) values(emp_empno_seq.nextval);
insert into emp(empno) values(emp_empno_seq.nextval);
修改emp_empno_seq序列的increment by属性为20,默认start with是1,alter sequence 序列名
alter sequence emp_empno_seq
increment by 20;
修改修改emp_empno_seq序列的的increment by属性为5
alter sequence emp_empno_seq
increment by 5;
修改emp_empno_seq序列的start with属性,行吗
alter sequence emp_empno_seq
start with 100;
有了序列后,还能为主健手工设置值吗?
insert into emp(empno) values(9999);
insert into emp(empno) values(7900);
删除表,会影响序列吗?
你无法做insert操作
删除序列,会影响表吗?
表真正亡,序列亡
在hibernate中,如果是访问oracle数据库服务器,那么User.hbm.xml映射文件中关于<id>标签如何配置呢?
<id name="id" column="id">
<generator class="increment/identity/uuid/【sequence】/【native】"/>
</id>
-------------------------------------------------------------------------------------索引
什么是索引【Index】
(1)是一种快速查询表中内容的机制,类似于新华字典的目录
(2)运用在表中某个/些字段上,但存储时,独立于表之外
为什么要用索引
(1)通过指针加速Oracle服务器的查询速度
(2)通过rowid快速定位数据的方法,减少磁盘I/O
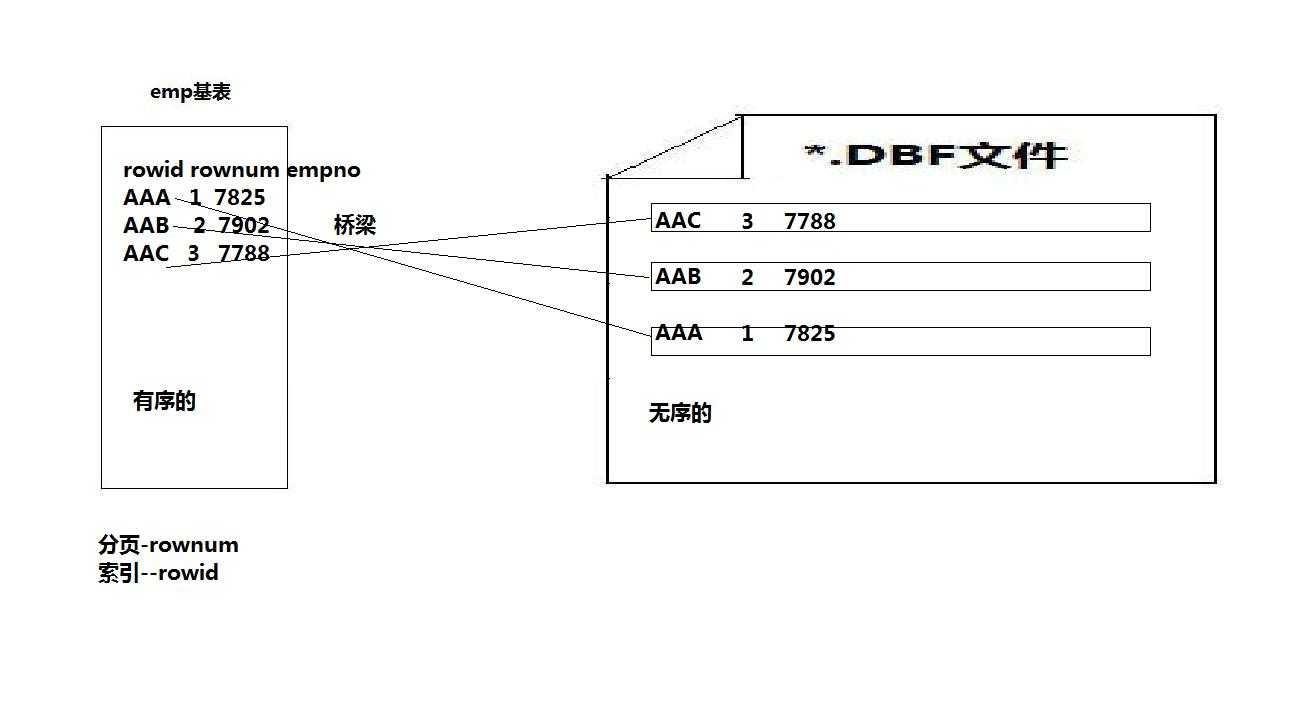
rowid是oracle中唯一确定每张表不同记录的唯一身份证
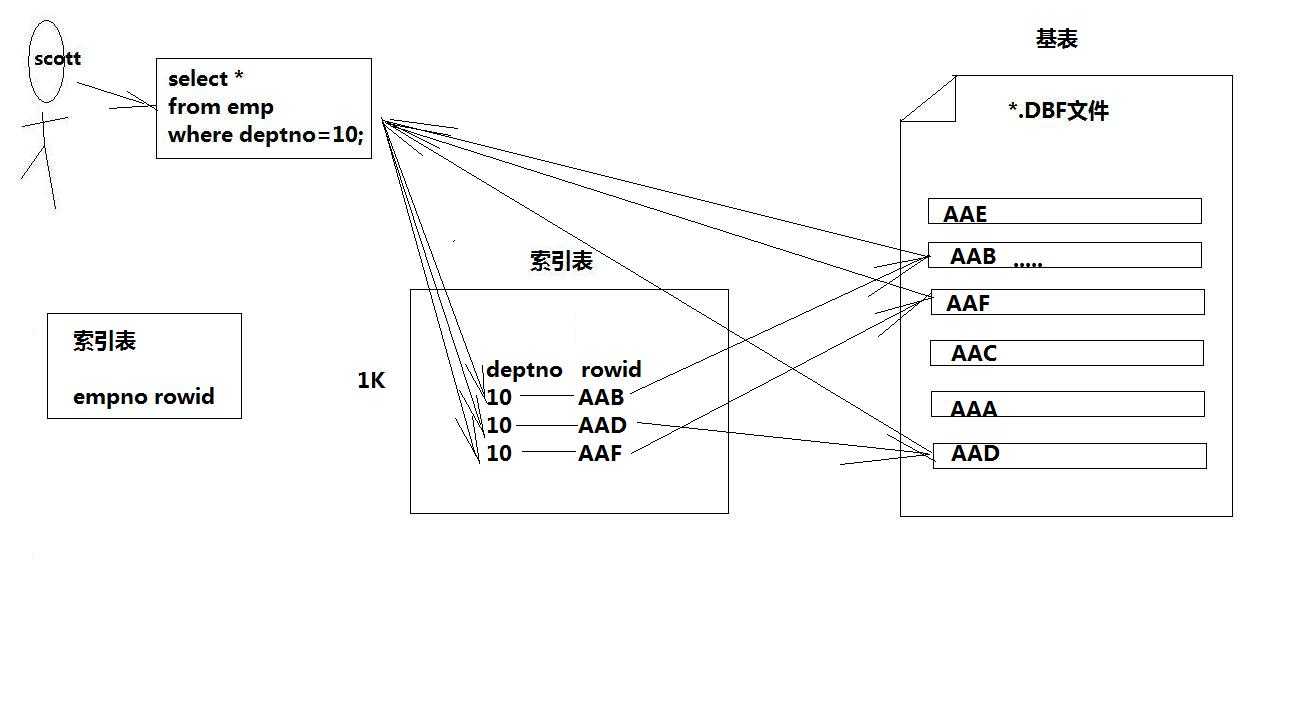
rowid的特点
(1)位于每个表中,但表面上看不见,例如:desc emp是看不见的
(2)只有在select中,显示写出rowid,方可看见
(3)它与每个表绑定在一起,表亡,该表的rowid亡,二张表rownum可以相同,但rowid必须是唯一的
(4)rowid是18位大小写加数字混杂体,唯一表代该条记录在DBF文件中的位置
(5)rowid可以参与=/like比较时,用‘‘单引号将rowid的值包起来,且区分大小写
(6)rowid是联系表与DBF文件的桥梁
索引的特点
(1)索引一旦建立, Oracle管理系统会对其进行自动维护, 而且由Oracle管理系统决定何时使用索引
(2)用户不用在查询语句中指定使用哪个索引
(3)在定义primary key或unique约束后系统自动在相应的列上创建索引
(4)用户也能按自己的需求,对指定单个字段或多个字段,添加索引
什么时候【要】创建索引
(1)表经常进行 SELECT 操作
(2)表很大(记录超多),记录内容分布范围很广
(3)列名经常在 WHERE 子句或连接条件中出现
注意:符合上述某一条要求,都可创建索引,创建索引是一个优化问题,同样也是一个策略问题
什么时候【不要】创建索引
(1)表经常进行 INSERT/UPDATE/DELETE 操作
(2)表很小(记录超少)
(3)列名不经常作为连接条件或出现在 WHERE 子句中
同上注意
为emp表的empno单个字段,创建索引emp_empno_idx,叫单列索引,create index 索引名 on 表名(字段,...)
create index emp_empno_idx
on emp(empno);
为emp表的ename,job多个字段,创建索引emp_ename_job_idx,多列索引/联合索引
create index emp_ename_job
on emp(ename,job);
如果在where中只出现job不使用索引
如果在where中只出现ename使用索引
我们提倡同时出现ename和job
注意:索引创建后,只有查询表有关,和其它(insert/update/delete)无关,解决速度问题
删除emp_empno_idx和emp_ename_job_idx索引,drop index 索引名
drop index emp_empno_idx;
drop index emp_ename_job_idx;
标签:-- scott sql查询语句 use com 策略 art 优化 表示
原文地址:http://www.cnblogs.com/webyyq/p/7632607.html