标签:支持 log 技术分享 记事本 4.4 bsp 路径 随机 发展
1. 什么是中文分词器
对于英文,是安装空格、标点符号进行分词
对于中文,应该安装具体的词来分,中文分词就是将词,切分成一个个有意义的词。
比如:“我的中国人”,分词:我、的、中国、中国人、国人。
2. Lucene自带的中文分词器
单字分词:就是按照中文一个字一个字地进行分词。如:“我爱中国”,
效果:“我”、“爱”、“中”、“国”。
二分法分词:按两个字进行切分。如:“我是中国人”,效果:“我是”、“是中”、“中国”“国人”。
上边两个分词器无法满足需求。
3. 第三方中文分词器
4. Ikanalyzer的使用
4.1 将jar包拷贝到项目路径下并发布
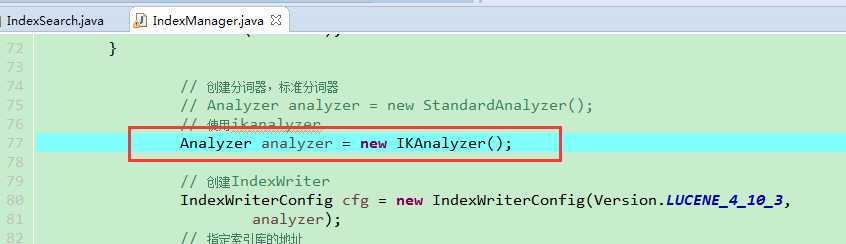
4.2 代码中使用Ikanalyzer替换标准分词器
4.3 扩展中文词库
config文件夹下创建以下文件(扩展词文件和停用词文件的编码要是utf-8。注意:不要用记事本保存扩展词文件和停用词文件,那样的话,格式中是含有bom的。)

IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典 --> <entry key="ext_dict">ext.dic;</entry>
<!--用户可以在这里配置自己的扩展停止词字典--> <entry key="ext_stopwords">stopword.dic;</entry>
</properties>
4.4 使用luke来查询中文分词效果
step1:将ikanalyzer的jar包,拷贝到luke工具的目录

step2:使用命令打开luke工具
java -Djava.ext.dirs=. -jar lukeall-4.10.3.jar
标签:支持 log 技术分享 记事本 4.4 bsp 路径 随机 发展
原文地址:http://www.cnblogs.com/zjfjava/p/7639319.html