标签:number operator ever -- list element and app names
刚开始学习机器学习,先跟这《机器学习实战》学一些基本的算法
----------------------------------分割线--------------------------------------------
该算法是用来判定一个点的分类,首先先找到离该点最近的k个点,然后找出这k个点的哪种分类出现次数最多,就把该点设为那个分类
距离公式选用欧式距离公式:
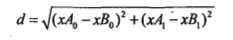
下面给出例子(来自《机器学习实战》)
1.约会对象喜欢程度的判定:
现需要一个约会对象喜欢程度的分类器
给定数据集,属性包含
每年获得的飞行常客里程数,玩视频游戏所耗时间百分比,每周消费的冰淇淋公升数,是否喜欢且喜欢程度(不喜欢,一般喜欢,特别喜欢),四个属性
分类器代码:
先获取整个数据集的约会对象个数t,然后把我们要分类的矩阵复制t次
然后减去原数据集,得到xA0-xB0和xA1-xB1,然后对矩阵每个元素平方,行内求和,开根号,得到所有点的距离
统计前k个数据类别出现次数,返回次数最多的类别
1 def classify0(inX, dataSet, labels, k): 2 dataSetSize = dataSet.shape[0] 3 diffMat = tile(inX, (dataSetSize,1)) - dataSet 4 sqDiffMat = diffMat**2 5 sqDistances = sqDiffMat.sum(axis=1) 6 distances = sqDistances**0.5 7 sortedDistIndicies = distances.argsort() 8 classCount={} 9 for i in range(k): 10 voteIlabel = labels[sortedDistIndicies[i]] 11 classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1 12 sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True) 13 return sortedClassCount[0][0]
先从文件中分别读前三个属性和喜欢程度到矩阵
然后进行归一化,最后分类得到结果统计一下就好了
1 def file2matrix(filename): 2 fr = open(filename) 3 numberOfLines = len(fr.readlines()) #get the number of lines in the file 4 returnMat = zeros((numberOfLines,3)) #prepare matrix to return 5 classLabelVector = [] #prepare labels return 6 fr = open(filename) 7 index = 0 8 for line in fr.readlines(): 9 line = line.strip() 10 listFromLine = line.split(‘\t‘) 11 returnMat[index,:] = listFromLine[0:3] 12 classLabelVector.append(int(listFromLine[-1])) 13 index += 1 14 return returnMat,classLabelVector 15 16 def autoNorm(dataSet): 17 minVals = dataSet.min(0) 18 maxVals = dataSet.max(0) 19 ranges = maxVals - minVals 20 normDataSet = zeros(shape(dataSet)) 21 m = dataSet.shape[0] 22 normDataSet = dataSet - tile(minVals, (m,1)) 23 normDataSet = normDataSet/tile(ranges, (m,1)) #element wise divide 24 return normDataSet, ranges, minVals 25 26 def datingClassTest(): 27 hoRatio = 0.50 #hold out 10% 28 datingDataMat,datingLabels = file2matrix(‘datingTestSet2.txt‘) #load data setfrom file 29 normMat, ranges, minVals = autoNorm(datingDataMat) 30 m = normMat.shape[0] 31 numTestVecs = int(m*hoRatio) 32 errorCount = 0.0 33 for i in range(numTestVecs): 34 classifierResult = classify0(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3) 35 print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, datingLabels[i]) 36 if (classifierResult != datingLabels[i]): errorCount += 1.0 37 print "the total error rate is: %f" % (errorCount/float(numTestVecs)) 38 print errorCount
2.数字识别
给定训练集包含32*32的01字符串,然后判定测试集的数字
对于把32*32每个数字都看作一个属性,然后直接算距离分类...
1 def img2vector(filename): 2 returnVect = zeros((1,1024)) 3 fr = open(filename) 4 for i in range(32): 5 lineStr = fr.readline() 6 for j in range(32): 7 returnVect[0,32*i+j] = int(lineStr[j]) 8 return returnVect 9 10 def handwritingClassTest(): 11 hwLabels = [] 12 trainingFileList = listdir(‘digits/trainingDigits‘) #load the training set 13 m = len(trainingFileList) 14 trainingMat = zeros((m,1024)) 15 for i in range(m): 16 fileNameStr = trainingFileList[i] 17 fileStr = fileNameStr.split(‘.‘)[0] #take off .txt 18 classNumStr = int(fileStr.split(‘_‘)[0]) 19 hwLabels.append(classNumStr) 20 trainingMat[i,:] = img2vector(‘digits/trainingDigits/%s‘ % fileNameStr) 21 testFileList = listdir(‘digits/testDigits‘) #iterate through the test set 22 errorCount = 0.0 23 mTest = len(testFileList) 24 for i in range(mTest): 25 fileNameStr = testFileList[i] 26 fileStr = fileNameStr.split(‘.‘)[0] #take off .txt 27 classNumStr = int(fileStr.split(‘_‘)[0]) 28 vectorUnderTest = img2vector(‘digits/testDigits/%s‘ % fileNameStr) 29 classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3) 30 print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, classNumStr) 31 if (classifierResult != classNumStr): errorCount += 1.0 32 print "\nthe total number of errors is: %d" % errorCount 33 print "\nthe total error rate is: %f" % (errorCount/float(mTest))
标签:number operator ever -- list element and app names
原文地址:http://www.cnblogs.com/humeay/p/7642602.html