标签:文本 inpu nim block img 分割 教程 作者 html
今天的博文是安装和使用光学字符识别(OCR)的Tesseract库的两部分系列的第一部分。
本系列的第一部分将着重于在您的机器上安装和配置Tesseract,然后使用tesseract命令将OCR应用于输入图像。
在这篇博文中,我们将:
通过本教程后,您将有知识在您自己的图像上运行Tesseract。下面给出具体的教程:
1. 为了使用Tesseract库,我们首先需要将它安装在我们的系统上。
打开终端ternimal,输入命令:
$ sudo apt-get install tesseract-ocr
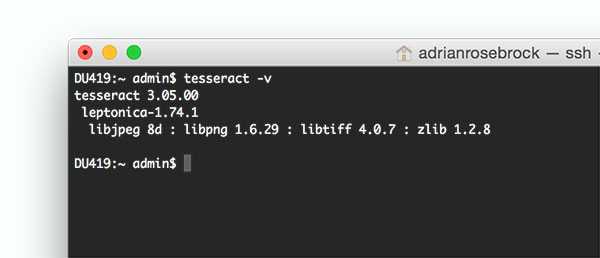
2.要验证Tesseract已成功安装在您的计算机上,请执行以下命令:
$ tesseract -v
3.测试Tesseract OCR
使用Tesseract时,我建议:
现在,我们将OCR应用到以下示例图像。(首先需要到原文链接中下载示例图像,原文链接在下文中给出)
进到你的项目路径下,在你的ternimal中输入下面的命令:
你会看到结果如截图所示:

到此,OCR已经完成,当然,你还可以尝试其他示例图像。
附上原文链接:https://www.pyimagesearch.com/2017/07/03/installing-tesseract-for-ocr/
版权声明:
作者:王老头
出处:http://www.cnblogs.com/wmr95/p/7642938.html
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,并在文章页面明显位置给出原文链接,否则,作者将保留追究法律责任的权利。
[PyImageSearch] Ubuntu16.04下针对OCR安装Tesseract
标签:文本 inpu nim block img 分割 教程 作者 html
原文地址:http://www.cnblogs.com/wmr95/p/7642938.html