标签:纯粹 out nta xpl 评价 线性 size 应该 ons
本文是 GANs 的拓展,在产生 和 判别时,考虑到额外的条件 y,以进行更加“激烈”的对抗,从而达到更好的结果。
众所周知,GANs 是一个 minmax 的过程:
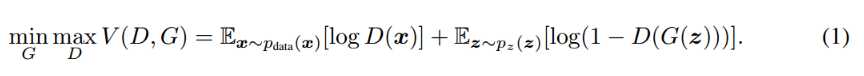
GAN的原始模型有很多可以改进的缺点,首当其中就是“模型不可控”。从上面对GAN的介绍能够看出,模型以一个随机噪声为输入。显然,我们很难对输出的结构进行控制。例如,使用纯粹的GAN,我们可以训练出一个生成器:输入随机噪声,产生一张写着0-9某一个数字的图片。然而,在现实应用中,我们往往想要生成“指定”的一张图片。
而本文通过引入 条件 y,从而将优化的目标函数变成了:
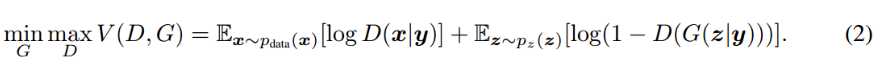
下图给出了条件产生式对抗网络的结构示意图:
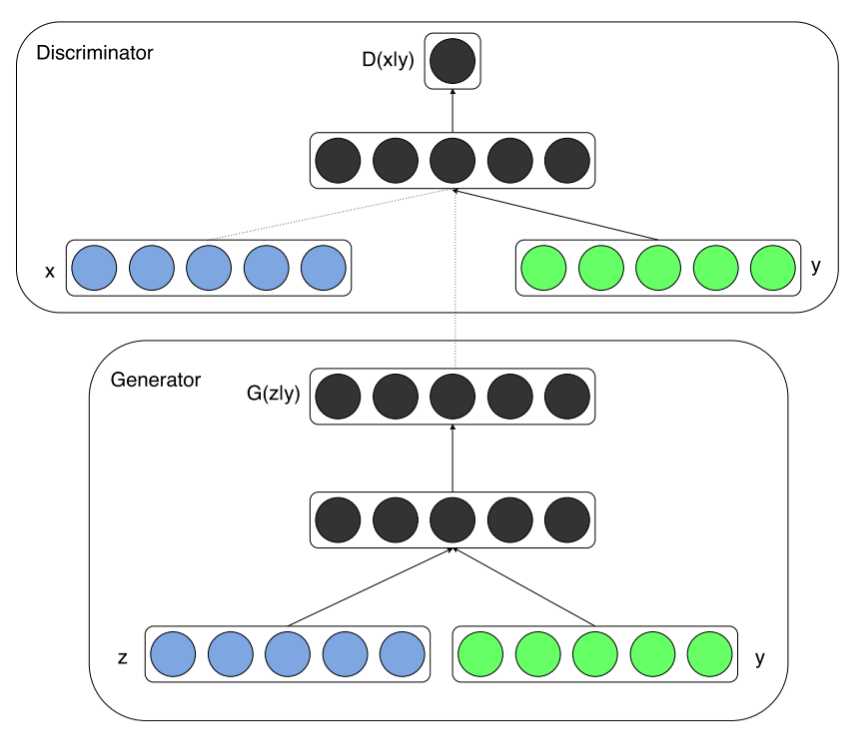
把噪声z和条件y作为输入同时送进生成器,生成跨域向量,再通过非线性函数映射到数据空间。
把数据x和条件y作为输入同时送进判别器,生成跨域向量,并进一步判断x是真实训练数据的概率。
实验
1.MNIST数据集实验
在MNIST上以数字类别标签为约束条件,最终根据类别标签信息,生成对应的数字。
生成模型的输入是100维服从均匀分布的噪声向量,条件y是类别标签的one hot编码。噪声z和标签y分别映射到隐层(200和1000个unit),在被第二次映射前,连接了所有1200个unit。最终用一个sigmoid层输出784维(28*28)的单通道图像。
判别模型把输入图像x映射到一个有240个unit和5 pieces的maxout layer,把y映射到有50个unit和5pieces的maxout layer。然后把所有隐层连在一起映射到240个unit和4pieces的maxout layer,然后经过sigmoid层。最终的输出是该样本x来自训练集的概率。

2.Flickr数据集上的图像自动标注实验(Mir Flickr-25k)
首先在完整的ImageNet数据集(21,000个label)上训练了一个卷积模型作为特征提取器。对于词语表达(原文中是world representation,个人认为是笔误,应该是word representation),作者使用YFCC100M数据集中的user-tags, titles和descriptions,利用skip-gram训练了一个200维的词向量。训练中忽略了词频小于200的词,最终词典大小是247465。
实验是基于MIR Flickr数据集,利用上面的模型提取图像和文本特征。为了便于评价,对于每个图片我们生成了100的标签样本,对于每个生成标签利用余弦相似度找到20个最接近的词,最后是选取了其中10个最常见的词。
在实验中,效果最好的生成器是接收100维的高斯噪声把它映射到500维的ReLu层,同时把4096维的图像特征向量映射到一个2000维的ReLu隐层,再上面的两种表示连接在一起映射到一个200维的线性层,最终由这个层输出200维的仿标签文本向量。(噪声+图像)
判别器是由500维和1200维的ReLu隐层组成,用于处理文本和图像。maxout层是有1000个单元和3spieces的连接层用于给最终的sigmoid层处理输入数据。(文本+图像)

注:
1.one hot编码
2.maxout(参数k=5)
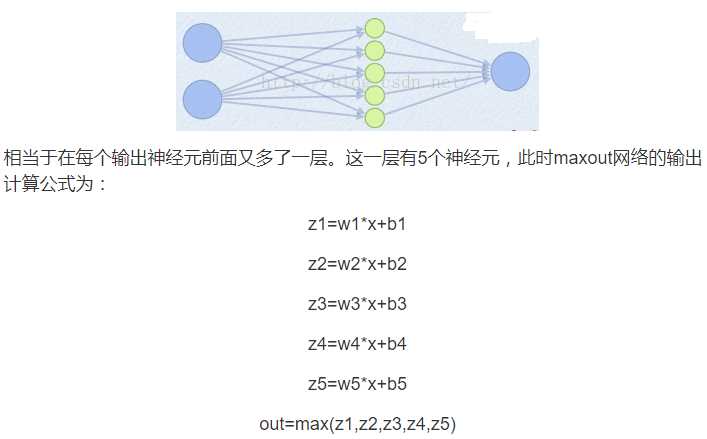
所以这就是为什么采用maxout的时候,参数个数成k倍增加的原因。本来我们只需要一组参数就够了,采用maxout后,就需要有k组参数。
Conditional Generative Adversarial Nets
标签:纯粹 out nta xpl 评价 线性 size 应该 ons
原文地址:http://www.cnblogs.com/J-K-Guo/p/7643439.html