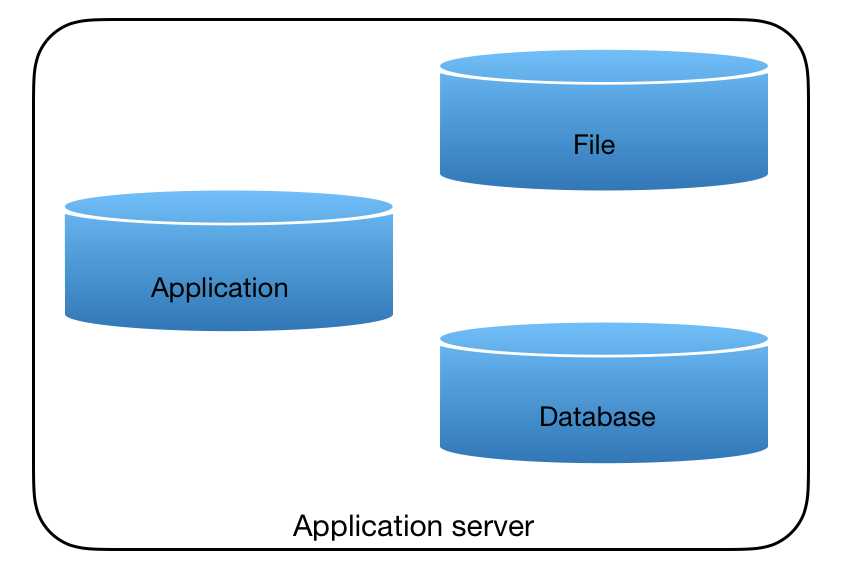
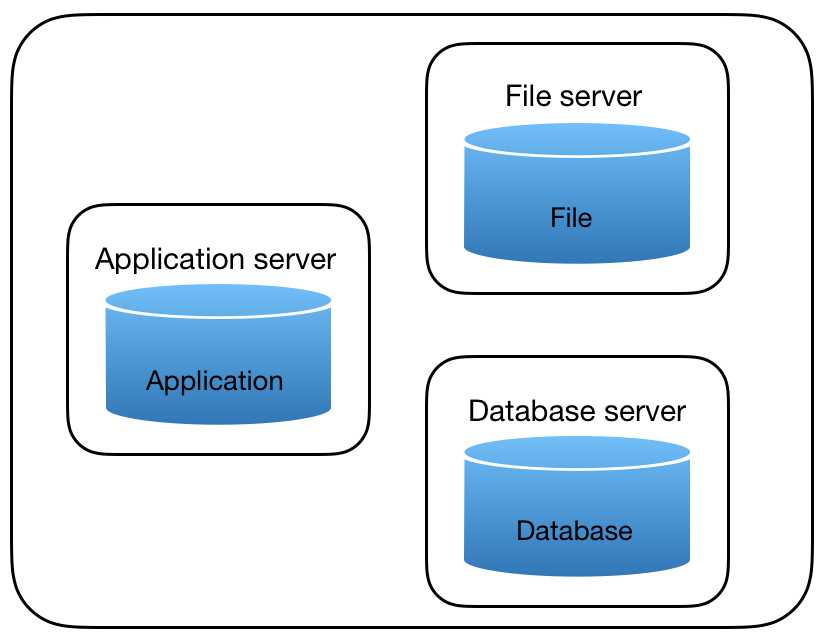
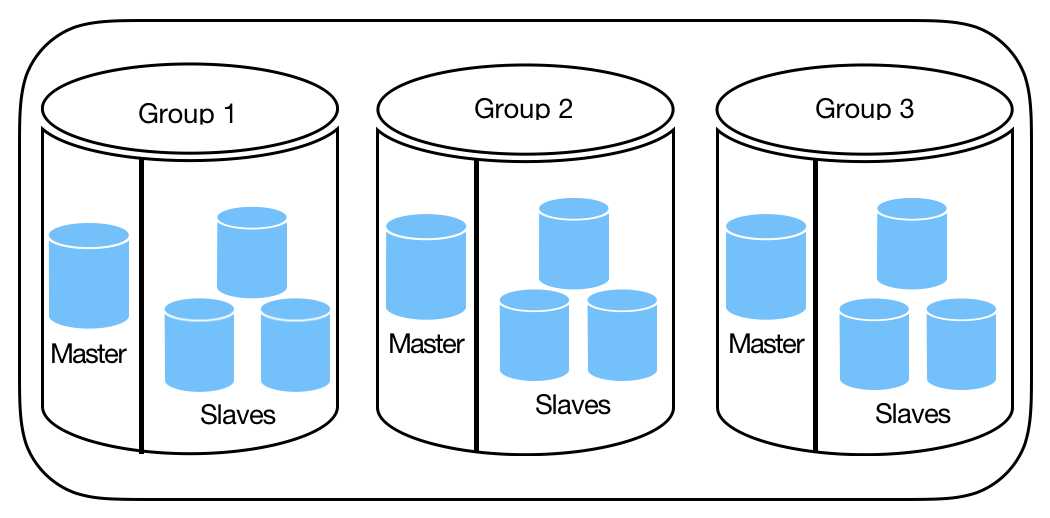
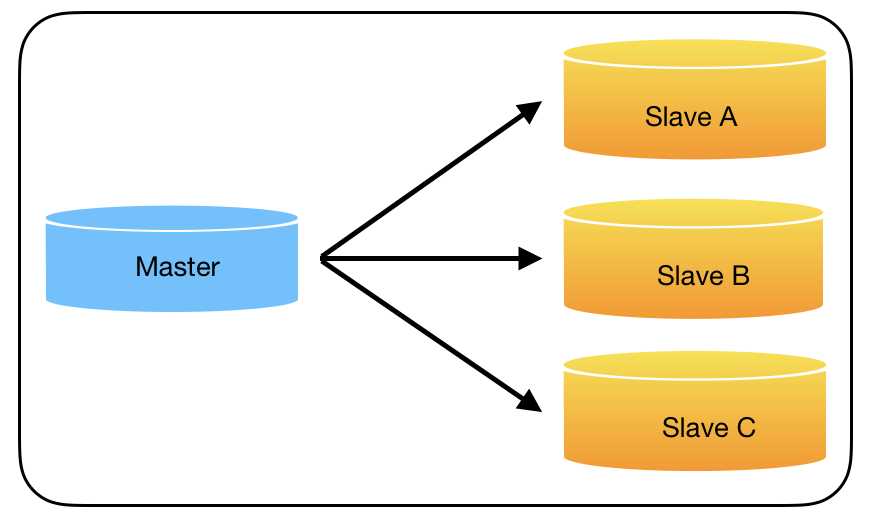
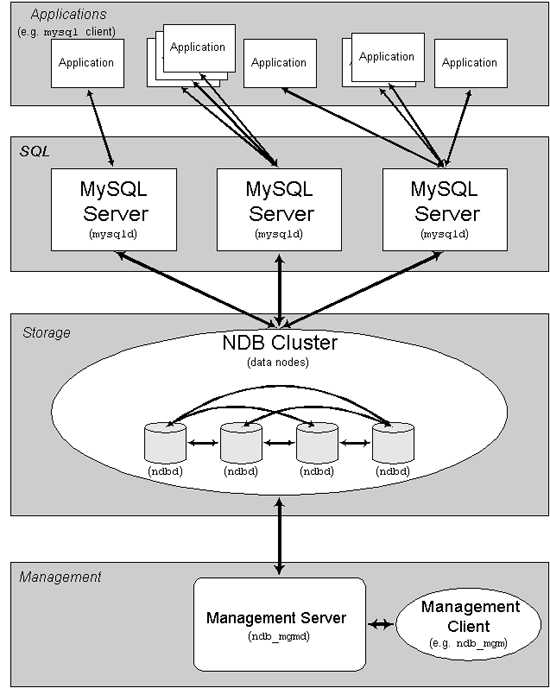
5、数据库垂直分割——解决部分数据写的问题
如果数据库服务器是采取主从方式部署的,当写操作占主数据库CPU消耗的50%以上时,从服务器的写操作也将占到CPU消耗的50%以上,一台从服务器提供的查询资源就非常有限,这时应考虑采取数据库垂直分区技术,按照功能把不同的数据分别放到不同的数据库和服务器中。比如用户的个人数据和用户的博客数据,它们之间的关联性不强,可以分别部署在两个独立的数据库服务器上。
6、数据库水平分割——分片
如果数据库垂直分区后仍然无法应对大量的写操作,应采取数据库水平分区技术。把一个表的数据根据一定的规则划分到不同的数据库(两个数据库的表结构一样),进而部署在不同的数据库服务器上。以上述博客为例,数据可以根据user_id的奇偶来确定数据的划分,把id为奇数的数据放到A库,id为偶数的数据放在B库,这样就可以通过user_id知道用户的博客数据在哪个数据库。
二、数据库高可用架构
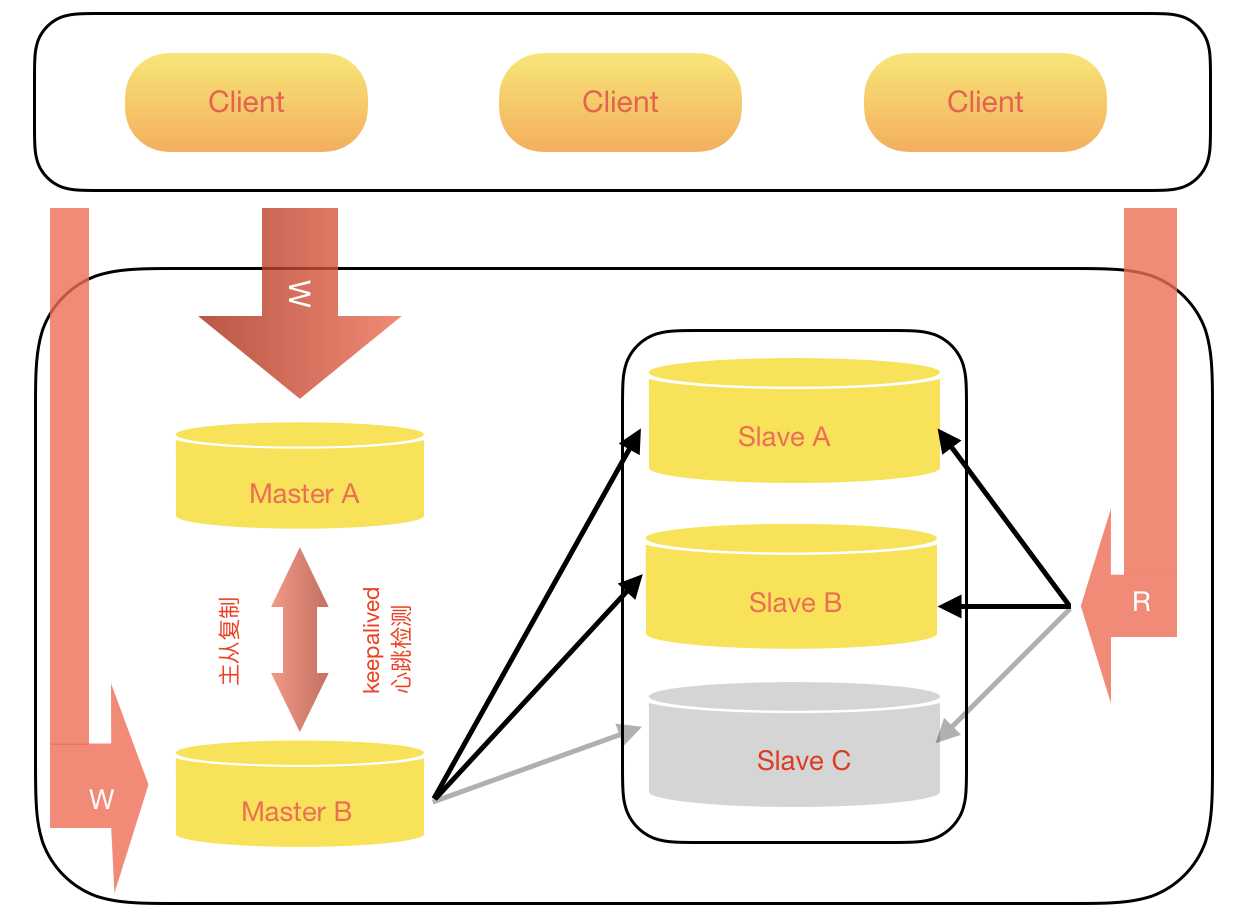
1、基于keepalived主从复制方案
为了达到更高的可用性,在实际的应用环境中,一般都是采用MySQL replication技术配合高可用集群软件keepalived来实现自动failover,这种方式可以实现95.000%的SLA。
(注:failover:意思就是当服务器down掉,或者出现错误的时候,可以自动的切换到其他待命的服务器,不影响服务器上App的运行。)
keepalived是一个HA软件,它的作用是检测服务器(web服务器,DB服务器等)状态,检查原理是模拟网络请求检测,检测方式包括HTTP_GET|SSL_GET|TCP_CHECK|SMTP_CHECK|MISC_CHECK等。
对于DB服务器而言,主要就是IP,端口(TCP_CHECK),但这可能不够(比如DB服务器ReadOnly),因此keepalived也支持自定义脚本。
keepalived通过监听来确认服务器的状态,如果发现服务器故障,则将故障服务器从系统中剔除。当Master故障时,keepalived感知,并将Slave提升主,继续提供服务对应用层透明。
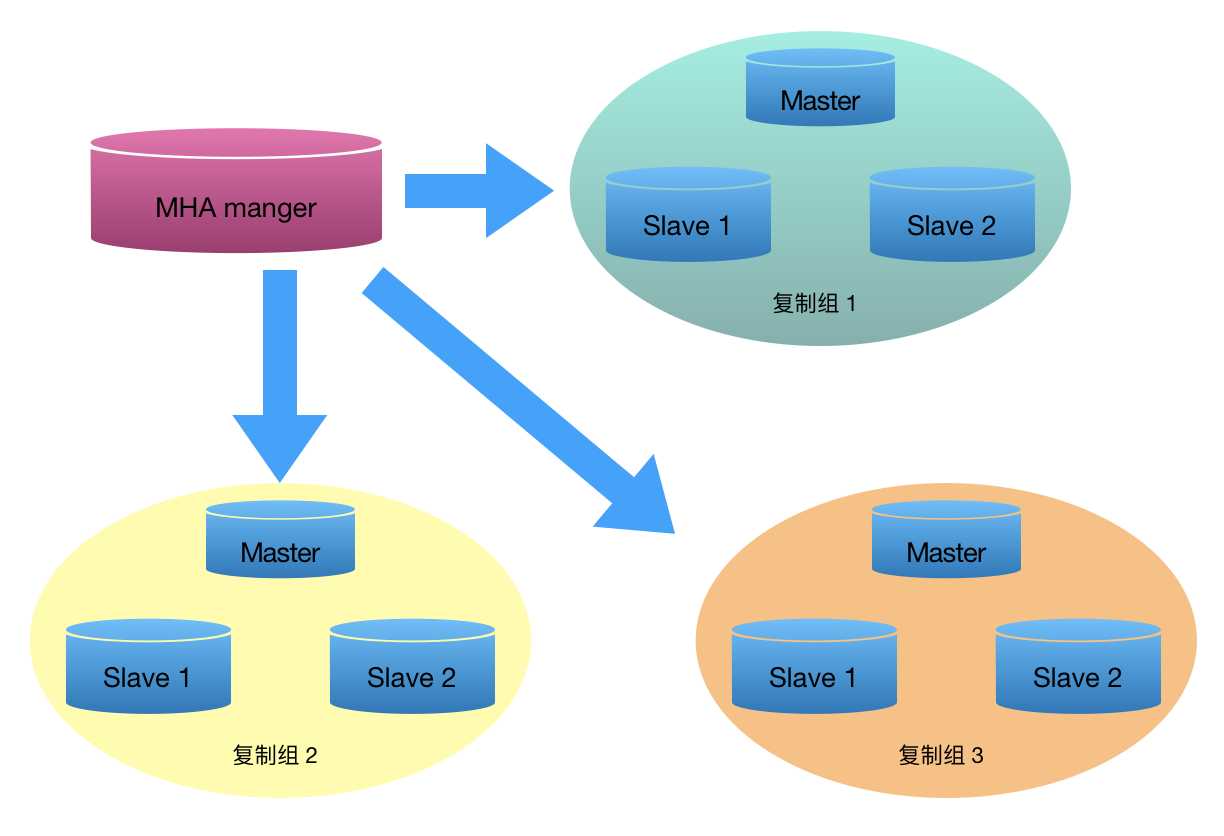
2、基于MHA高可用解决方案
MHA(Master High Availability)是一套MySQL故障切换方案,保证数据库的高可用。通过从宕机的主服务器上保存二进制日志来进行回补,能在最大程度上减少数据丢失。
MHA由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。
MHA可以单独部署在一台独立的机器上管理多个master-slave集群,MHA Node运行在每台MySQL服务器上,主要作用是切换时处理二进制日志,确保切换尽量少丢数据。
MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新数据的slave提升为新的master,然后将所有其他的slave重新指向新的master,整个故障转移过程对应用程序完全透明。
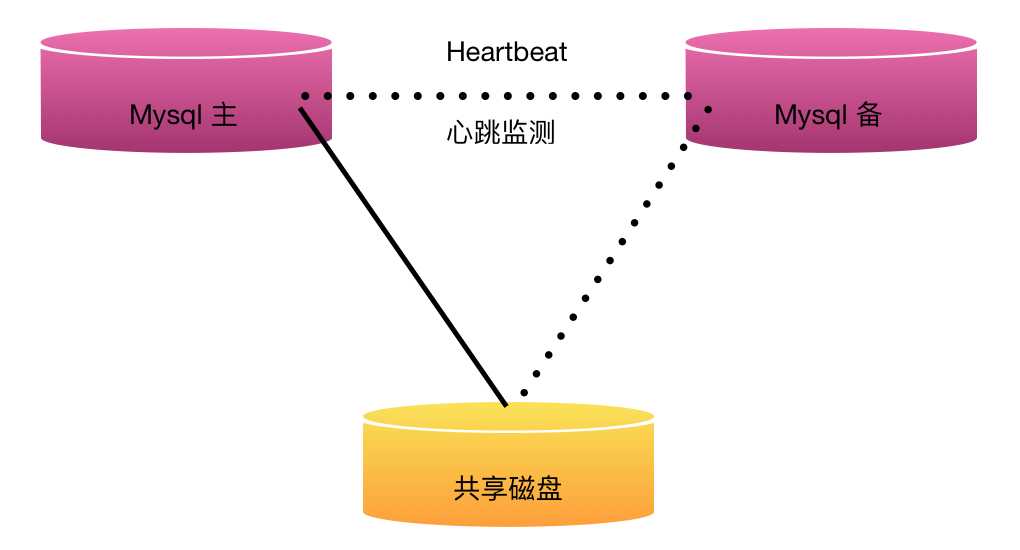
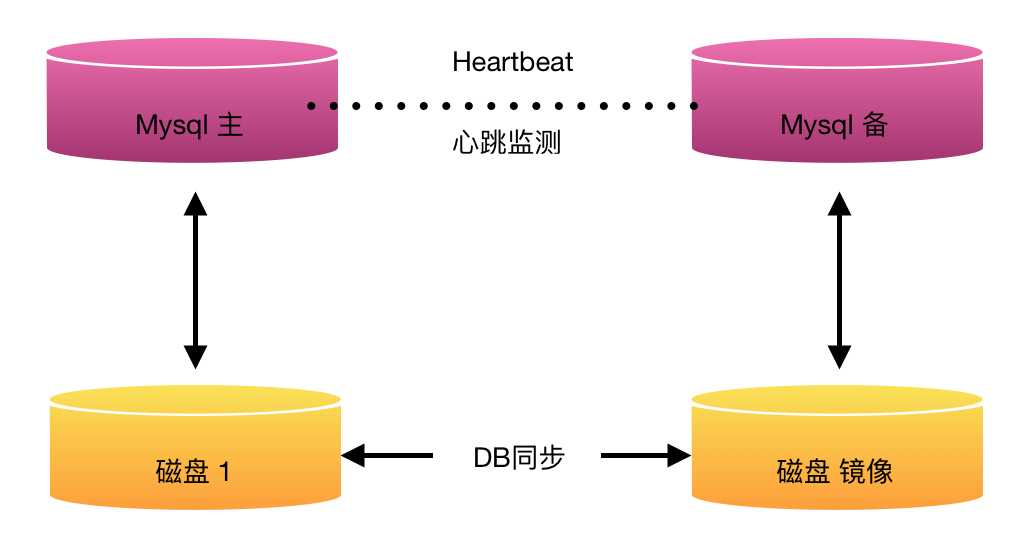
3、基于Heartbeat/SAN高可用解决方案
处理failover的方式是高可用集群软件Heartbeat,它监控管理各个节点间连接的网络,并监控集群服务。当节点出现故障或不可用时,自动在其他节点启动集群服务。