标签:符号 文字 字符 结果 ima fan 面积 title 房价
1、网页分析(获取所有城市列表)
citys.py
‘‘‘ Created on 2017-10-9 @author: wbhuangzhiqiang ‘‘‘ import csv import urllib.request from bs4 import BeautifulSoup url=‘https://www.lianjia.com‘ #获取html # 获取 html 页面 html = urllib.request.urlopen(url).read() # 获取 BeautifulSoup 对象,用 html5lib 解析(也可用 lxml 或其它方式解析,html5lib 容错性较好,所以此处选用 html5lib ) bsobj = BeautifulSoup(html, "html5lib") # 得到 class="cityList clear" 的 div 下所有 a 标签 city_tags = bsobj.find("div",{"class":"cityList clear"}).findChildren("a") print(city_tags) # 将每一条数据抽离,保存在 citys.csv 文件中 with open("./citys.csv", "w") as f: writ = csv.writer(f) for city_tag in city_tags: # 获取 <a> 标签的 href 链接 city_url = city_tag.get("href") # 获取 <a> 标签的文字,如:天津 city_name = city_tag.get_text() writ.writerow((city_name, city_url)) print (city_name, city_url)
2、二手房信息
‘‘‘ Created on 2017-10-9 @author: wbhuangzhiqiang ‘‘‘ import sys import re import csv import urllib.request from bs4 import BeautifulSoup # 成功打开页面时返回页面对象,否则打印错误信息,退出程序 def get_bsobj(url): page = urllib.request.urlopen(url) if page.getcode() == 200: html = page.read() bsobj = BeautifulSoup(html, "html5lib") return bsobj else: print ("页面错误") sys.exit() def get_house_info_list(url): house_info_list = [] bsobj = get_bsobj(url) if not bsobj: return None #获取页数 global house_info_page house_page = bsobj.find("a", {"gahref":"results_totalpage"}) house_info_page=int(house_page.get_text()) #print(house_info_page) house_list = bsobj.find_all("div", {"class":"info"}) for house in house_list: #title = house.find("div", {"class": "prop-title"}).get_text().split("|") # 获取信息数据(例:加怡名城 | 2室1厅 | 62.48平米 | 西 | 精装),通过“|”符号分割字符串 info = house.find("span", {"class": "info-col row1-text"}).get_text().split("|") #print("==========1====") info2 = house.find("span", {"class": "info-col row2-text"}).get_text().split("|") #print("==========2====") #print(info2) #print("==========2====") #print(info2) #print("==========2====") minor = house.find("span", {"class": "info-col price-item minor"}).get_text().strip() # 小区(例:加怡名城),strip()去除字符串两边的空格,encode,将字符串编码成 utf-8 格式 block = info2[1].strip()+info2[2].strip()+info2[0].strip() if len(info2)>3: naidai = info2[3].strip() else: naidai=‘未知‘ #房型 house_type =info[0].strip() #面积 size =info[1].strip() price_sz = house.find("span", {"class": "total-price strong-num"}).get_text() price_dw = house.find("span", {"class": "unit"}).get_text() price =price_sz+price_dw #print(price) house_info_list.append({‘房型‘:house_type,‘面积‘:size,‘价格‘:price,‘房屋位置‘:block,‘年代‘:naidai,‘单价‘:minor}) #print(‘**********************‘) #print(house_info_list) #print(len(house_info_list)) return house_info_list # 读取前100个页面的房屋信息,将信息保存到 house.csv 文件中 def house_mess(url): house_info_list =[] get_house_info_list(url) if house_info_page>20: for i in range(0,21): new_url = url +‘/d‘+str(i) house_info_list.extend(get_house_info_list(new_url)) #print(new_url) #print(house_info_list) #print("****************house_info_list*********************") #print(house_info_list) if house_info_list: # 将数据保存到 house.csv 文件中 with open("./house.csv", "w",newline=‘‘) as f: # writer 对象 writer = csv.writer(f) fieldnames=house_info_list[0].keys() writer.writerow(fieldnames) for house_info in house_info_list: #print(‘&&&&&&&&&&&&&&&&&&&&&&&‘) #print(house_info) writer.writerow(house_info.values()) #house_mess(‘http://sh.lianjia.com/ershoufang/minhang‘)
3、main.py
‘‘‘ Created on 2017-10-9 @author: wbhuangzhiqiang ‘‘‘ #coding=gbk import csv import sys import urllib.request from bs4 import BeautifulSoup from house_info import house_mess def get_city_dict(): city_dict = {} with open(‘./citys.csv‘, ‘r‘) as f: reader =csv.reader(f) for city in reader: if len(city)>0: city_dict[city[0]] = city[1] return city_dict city_dict = get_city_dict() #print(city_dict) # 打印所有的城市名 def get_district_dict(url): district_dict = {} html = urllib.request.urlopen(url).read() bsobj = BeautifulSoup(html, "html5lib") roles = bsobj.find("div", {"class":"level1"}).findChildren("a") for role in roles: # 对应区域的 url district_url = role.get("href") # 对应区域的名称 district_name = role.get_text() # 保存在字典中 district_dict[district_name] = district_url return district_dict def run(): city_dict = get_city_dict() for city in city_dict.keys(): print(city,end=‘ ‘) print() key_city= input("请输入城市 ") # 根据用户输入的城市名,得到城市 url city_url = city_dict.get(key_city) # 根据用户输入的城市名,得到城市 url if city_url: print (key_city, city_url) else: print( "输入错误") # 退出 sys.exit() ershoufang_city_url = city_url + "/ershoufang" print(ershoufang_city_url) district_dict = get_district_dict(ershoufang_city_url) # 打印区域名 for district in district_dict.keys(): print (district,end=‘ ‘) print() input_district = input("请输入地区:") district_url = district_dict.get(input_district) # 输入错误,退出程序 if not district_url: print ("输入错误") sys.exit() # 如果都输入正确 house_info_url = city_url + district_url house_mess(house_info_url) if __name__ == "__main__": run()
4、以上海闵行为例,house.csv 爬取的内容为
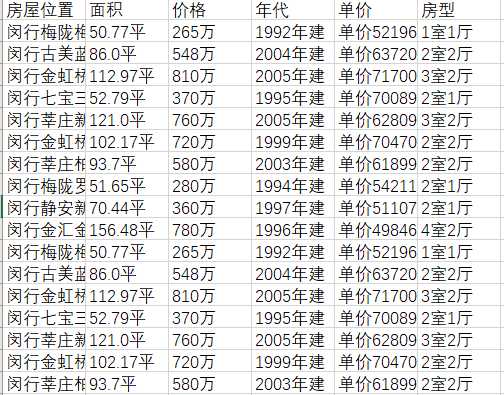
结果表明,上海房价真的是高啊~~
标签:符号 文字 字符 结果 ima fan 面积 title 房价
原文地址:http://www.cnblogs.com/HZQHZA/p/7648452.html