标签:map import utf-8 dump images 字典 open file compile
1. 网址:http://maoyan.com/board/4?
2. 代码:

1 import json 2 from multiprocessing import Pool 3 import requests 4 from requests.exceptions import RequestException 5 import re 6 7 8 def get_one_page_html(url): 9 try: 10 response = requests.get(url) 11 if response.status_code == 200: 12 return response.text 13 return None 14 except RequestException: 15 return None 16 17 def parse_one_page(html): 18 pattern = re.compile(‘<dd>.*?board-index.*?>(\d+)</i>.*?alt.*?src="(.*?)".*?name"><a‘ 19 +‘.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>‘ 20 +‘.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>‘, re.S)# .可以匹配任意的换行符 21 22 items = re.findall(pattern,html) 23 #(‘1‘, ‘http://p1.meituan.net/movie/20803f59291c47e1e116c11963ce019e68711.jpg@160w_220h_1e_1c‘, ‘霸王别姬‘, ‘\n 主演:张国荣,张丰毅,巩俐\n ‘, ‘上映时间:1993-01-01(中国香港)‘, ‘9.‘, ‘6‘), 24 for item in items: 25 yield { 26 ‘index‘ : item[0], 27 ‘image‘ : item[1], 28 ‘title‘:item[2], 29 ‘actor‘ : item[3].strip()[3:], 30 ‘time‘: item[4].strip()[5:], 31 ‘score‘ : item[5] + item[6] 32 } 33 34 def write_to_file(content): 35 with open(‘result.txt‘, ‘a‘, encoding=‘utf-8‘)as f: 36 f.write(json.dumps(content, ensure_ascii=False) + ‘\n‘)#导入快捷见alt+enter,content内容是个字典,我们要把它变成字符串写入文件,加入换行符,每行一个 37 f.close() 38 39 def main(offset): 40 url = ‘http://maoyan.com/board/4?offset=‘ + str(offset) 41 html = get_one_page_html(url) 42 for item in parse_one_page(html): 43 print(item) 44 write_to_file(item) #会变成unicode编码,若想result.txt里面是中文,需要修改write_to_file函数,加上encoding=‘utf-8’和ensure_ascii=False 45 46 if __name__ == ‘__main__‘: 47 # for i in range(10): 48 # main(i*10) 49 50 pool = Pool() 51 pool.map(main, [i*10 for i in range(10)])
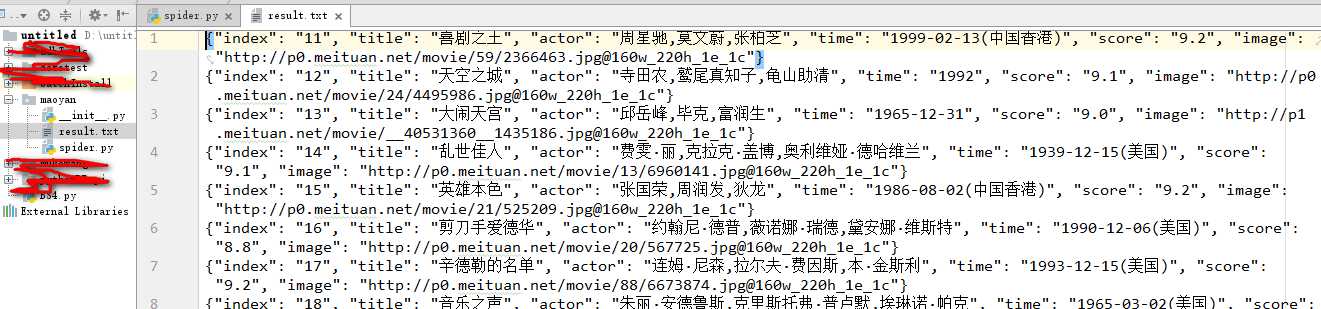
3. 结果:
注意:
1.正则匹配要好好看看
2.将输出的内容格式化,变成一个生成器字典
3.写到文件的时候把unicode编码变成中文显示
4.进程池Pool。实现秒抓
标签:map import utf-8 dump images 字典 open file compile
原文地址:http://www.cnblogs.com/rrl92/p/7656128.html
