标签:帮助 正则 分组 表达式 标志位 double 说明 pil 完整
Python -- 正则表达式
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。
Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式。
re 模块使 Python 语言拥有全部的正则表达式功能。
compile 函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象。该对象拥有一系列方法用于正则表达式匹配和替换。
re 模块也提供了与这些方法功能完全一致的函数,这些函数使用一个模式字符串做为它们的第一个参数。
本篇主要介绍Python中常用的正则表达式处理函数。
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
函数语法:
re.match(pattern, string, flags=0)
函数参数说明:
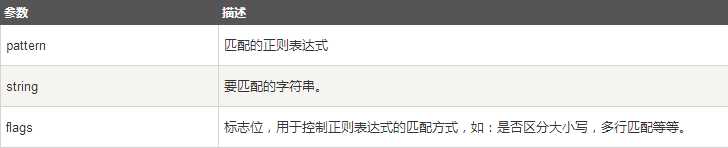
匹配成功re.match方法返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。

# -*- coding: UTF-8 -*- import re print(re.match(‘www‘, ‘www.runoob.com‘).span()) # 在起始位置匹配(0,3) print(re.match(‘com‘, ‘www.runoob.com‘)) # 不在起始位置匹配 none
import re line = "Cats are smarter than dogs" matchObj = re.match( r‘(.*) are (.*?) .*‘, line, re.M|re.I) if matchObj: print "matchObj.group() : ", matchObj.group() print "matchObj.group(1) : ", matchObj.group(1) print "matchObj.group(2) : ", matchObj.group(2) else: print "No match!!" #输出 #matchObj.group() : Cats are smarter than dogs #matchObj.group(1) : Cats #matchObj.group(2) : smarter
re.search 扫描整个字符串并返回第一个成功的匹配。
函数语法:
re.search(pattern, string, flags=0)
函数参数说明:
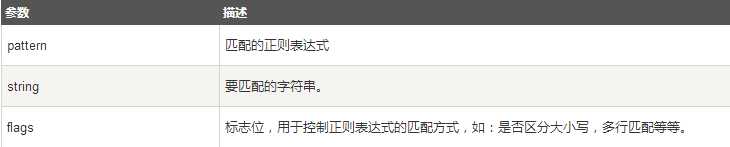
匹配成功re.search方法返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。

# -*- coding: UTF-8 -*- import re print(re.search(‘www‘, ‘www.runoob.com‘).span()) # 在起始位置匹配 (0, 3) print(re.search(‘com‘, ‘www.runoob.com‘).span()) # 不在起始位置匹配 (11, 14)
import re line = "Cats are smarter than dogs"; searchObj = re.search( r‘(.*) are (.*?) .*‘, line, re.M|re.I) if searchObj: print "searchObj.group() : ", searchObj.group() print "searchObj.group(1) : ", searchObj.group(1) print "searchObj.group(2) : ", searchObj.group(2) else: print "Nothing found!!" #结果 #searchObj.group() : Cats are smarter than dogs #searchObj.group(1) : Cats #searchObj.group(2) : smarter
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
import re line = "Cats are smarter than dogs"; matchObj = re.match( r‘dogs‘, line, re.M|re.I) if matchObj: print "match --> matchObj.group() : ", matchObj.group() else: print "No match!!" matchObj = re.search( r‘dogs‘, line, re.M|re.I) if matchObj: print "search --> matchObj.group() : ", matchObj.group() else: print "No match!!" #结果 #No match!! #search --> matchObj.group() : dogs
Python 的 re 模块提供了re.sub用于替换字符串中的匹配项。
语法:
re.sub(pattern, repl, string, count=0, flags=0)
参数:前三个是必填参数,后两个是可选参数
import re phone = "2004-959-559 # 这是一个国外电话号码" # 删除字符串中的 Python注释 num = re.sub(r‘#.*$‘, "", phone) print "电话号码是: ", num # 删除非数字(-)的字符串 num = re.sub(r‘\D‘, "", phone) print "电话号码是 : ", num #结果 #电话号码是: 2004-959-559 #电话号码是 : 2004959559
以下实例中将字符串中的匹配的数字乘于 2:
# -*- coding: UTF-8 -*- import re # 将匹配的数字乘于 2 def double(matched): value = int(matched.group(‘value‘)) return str(value * 2) s = ‘A23G4HFD567‘ print(re.sub(‘(?P<value>\d+)‘, double, s)) #value = 23 、4 、567等等,一次次调用double 返回乘于2后的值 #结果 #A46G8HFD1134
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。多个标志可以通过按位 OR(|) 它们来指定。如 re.I | re.M 被设置成 I 和 M 标志:

模式字符串使用特殊的语法来表示一个正则表达式:
字母和数字表示他们自身。一个正则表达式模式中的字母和数字匹配同样的字符串。
多数字母和数字前加一个反斜杠时会拥有不同的含义。
标点符号只有被转义时才匹配自身,否则它们表示特殊的含义。
反斜杠本身需要使用反斜杠转义。
由于正则表达式通常都包含反斜杠,所以你最好使用原始字符串来表示它们。模式元素(如 r‘\t‘,等价于 ‘\\t‘)匹配相应的特殊字符。
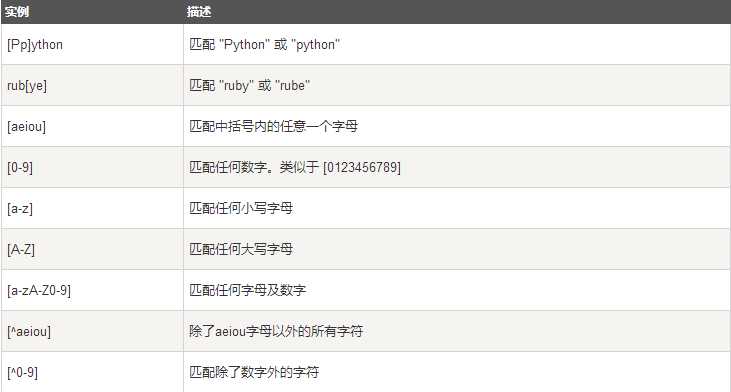
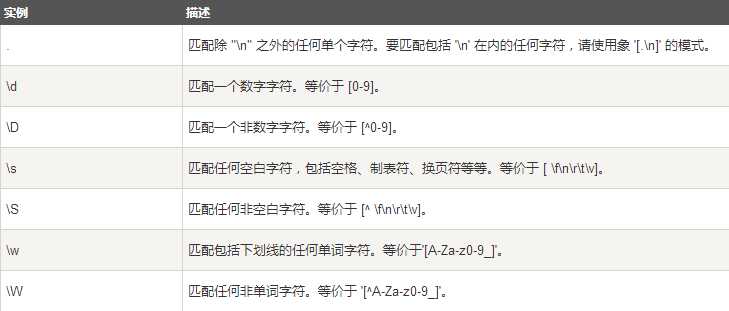
下表列出了正则表达式模式语法中的特殊元素。如果你使用模式的同时提供了可选的标志参数,某些模式元素的含义会改变。
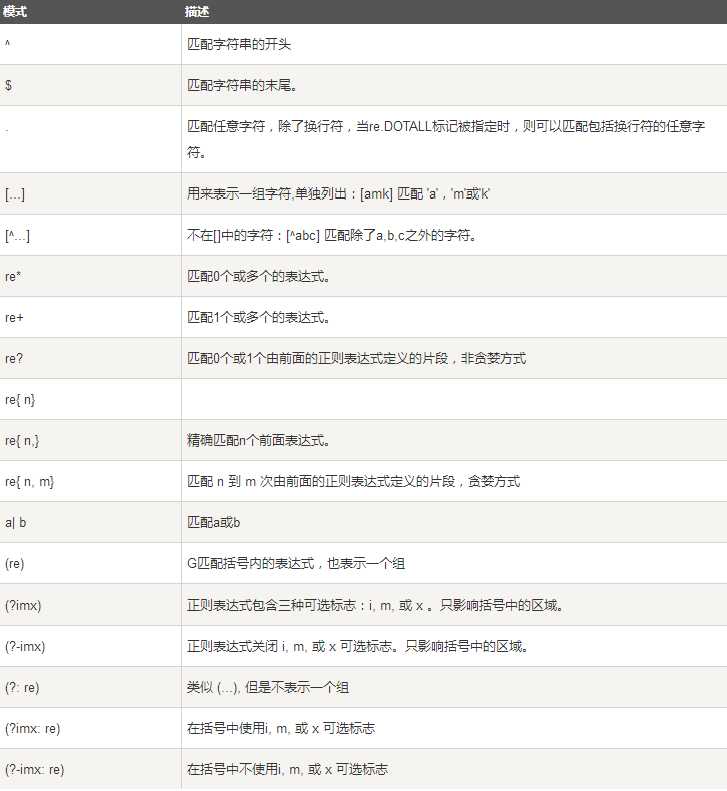
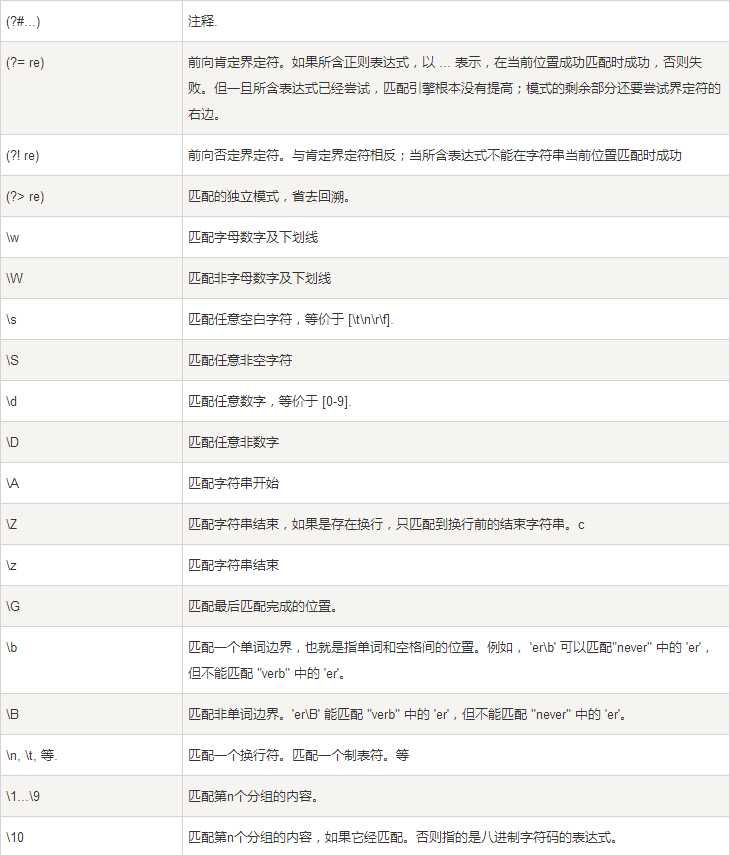

import re line = "Cats are smarter than dogs" matchObj = re.match( r‘(.*) are (.*?) .*‘, line, re.M|re.I) if matchObj: print "matchObj.group() : ", matchObj.group() print "matchObj.group(1) : ", matchObj.group(1) print "matchObj.group(2) : ", matchObj.group(2) else: print "No match!!" #正则表达式: r‘(.*) are (.*?) .*‘
解析:
首先,这是一个字符串,前面的一个 r 表示字符串为非转义的原始字符串,让编译器忽略反斜杠,也就是忽略转义字符。但是这个字符串里没有反斜杠,所以这个 r 可有可无。
matchObj.group() 等同于 matchObj.group(0),表示匹配到的完整文本字符
matchObj.group(1) 得到第一组匹配结果,也就是(.*)匹配到的
matchObj.group(2) 得到第二组匹配结果,也就是(.*?)匹配到的
因为只有匹配结果中只有两组,所以如果填 3 时会报错。
结果
matchObj.group() : Cats are smarter than dogs matchObj.group(1) : Cats matchObj.group(2) : smarter
标签:帮助 正则 分组 表达式 标志位 double 说明 pil 完整
原文地址:http://www.cnblogs.com/BlueSkyyj/p/7616664.html