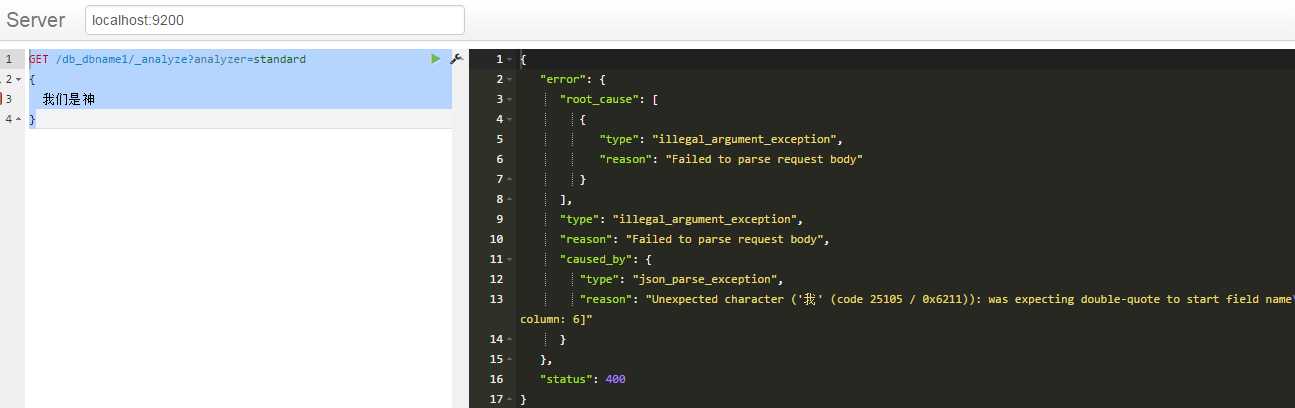
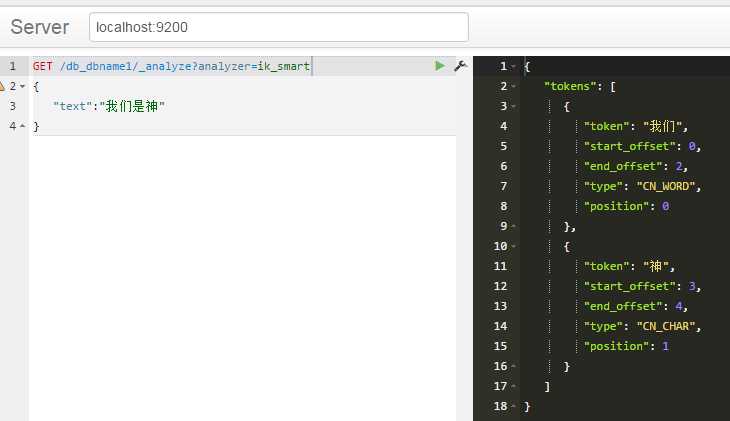
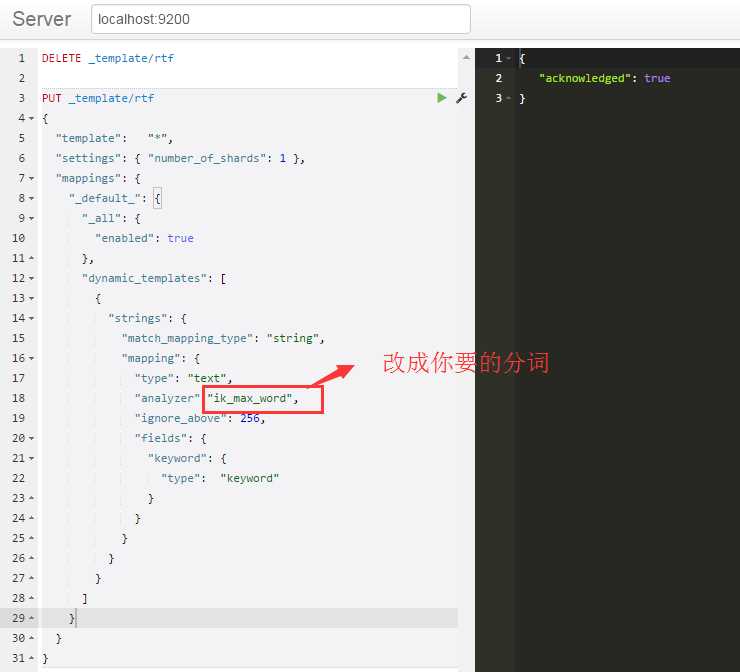
标签:back 标准 控制 系统 round 根据 analyzer server title
修改就是将id置为和存在的记录一致)
、、
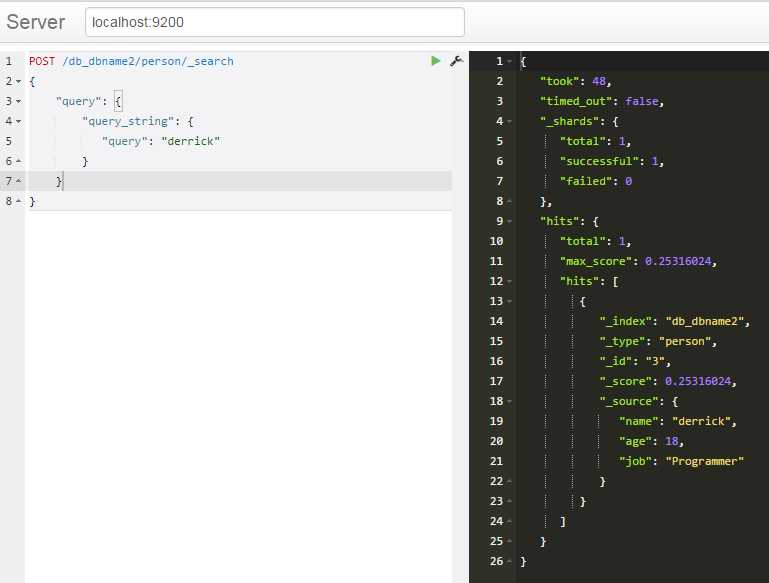
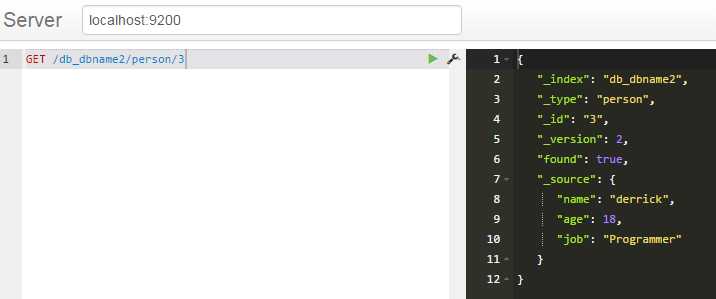
根据id查询单条记录
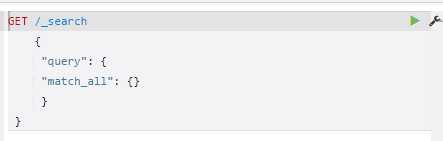
查询所有库,所有表的文档
ElasticSearch+.net 大数据处理(一)
原文地址:http://www.cnblogs.com/dongqinglove/p/b3945de2e477a2fea52518abe9dc5a37.html
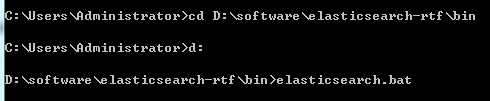
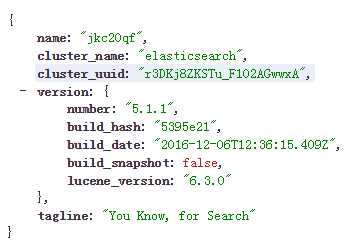
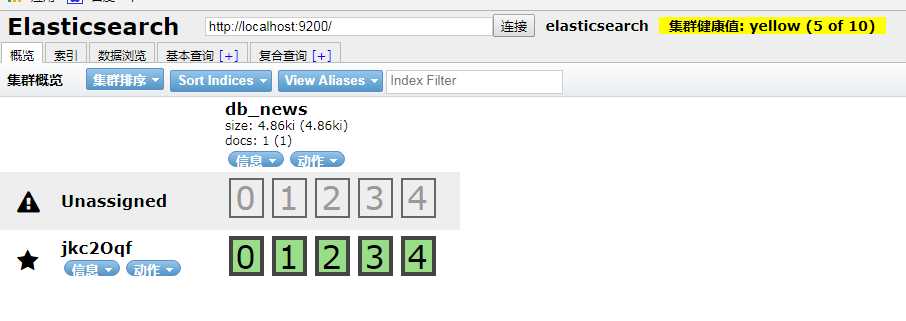
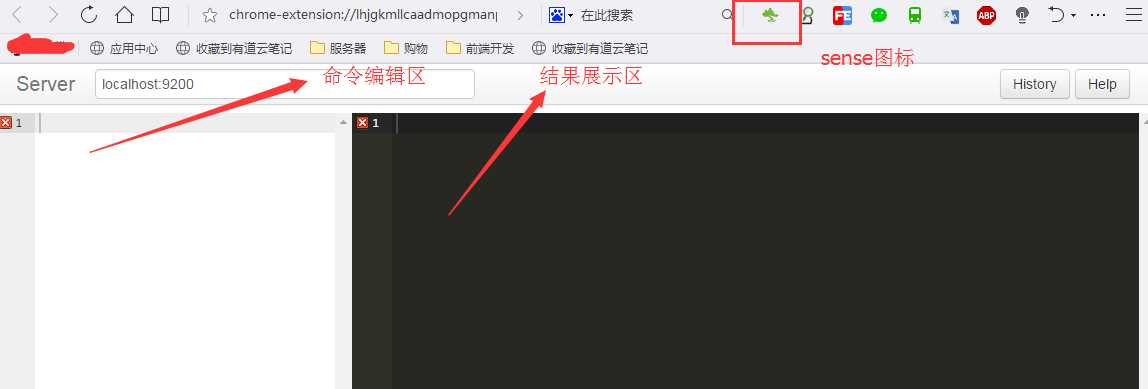
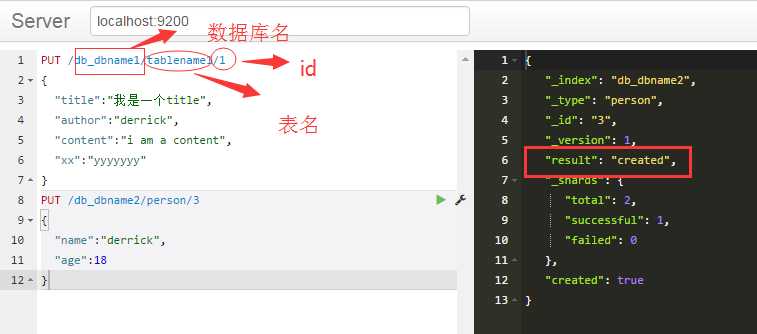
、、
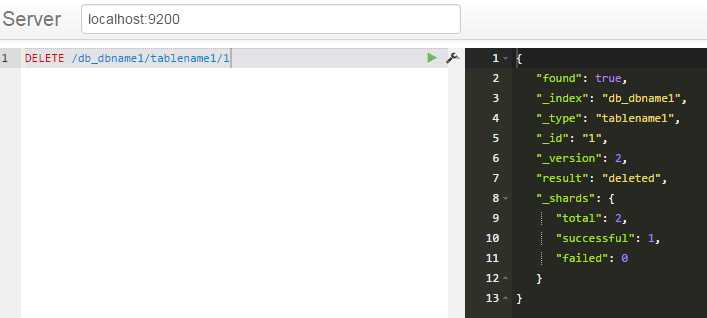
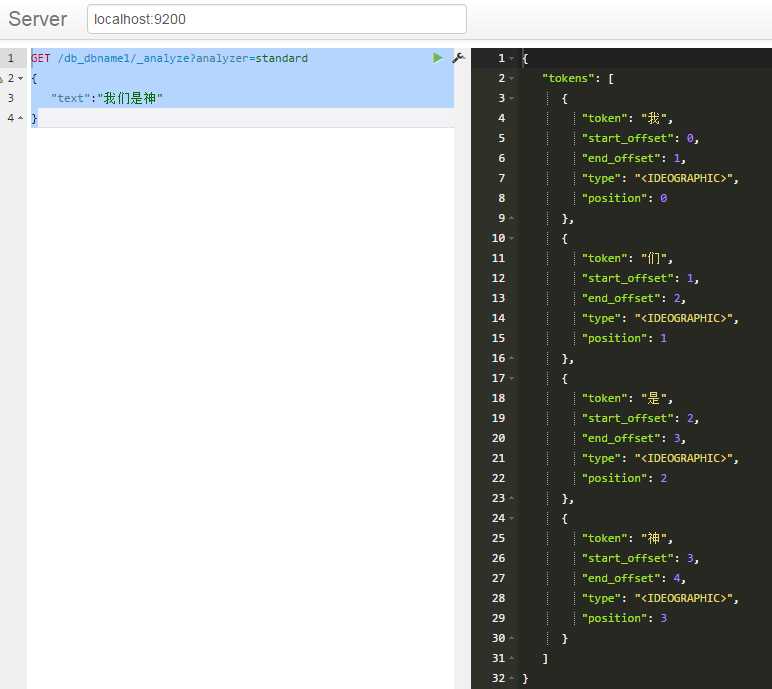 、
、